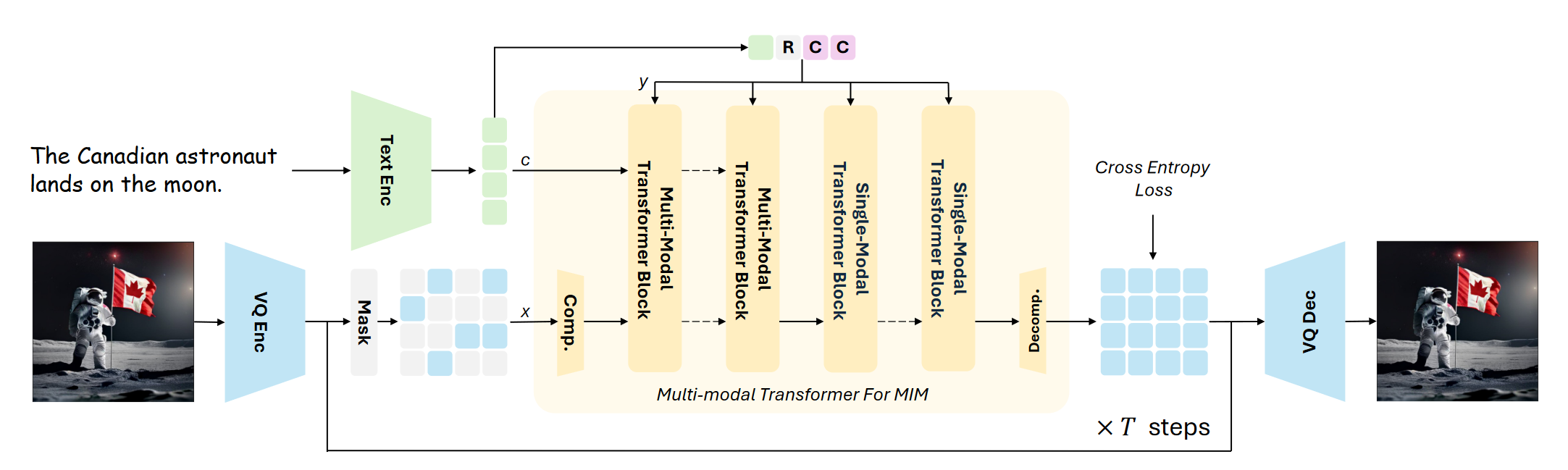
1 研究背景、动机、主要贡献1.1 存在问题(动机)自回归生成由于图像令牌数量庞大,效率低下;而非自回归方法(如MIM)则在性能上有限,无法与先进的扩散模型相比。 1.2 主要贡献 增强的变换器架构:结合多模态和单模态变换器层,提高M...
SHOW-O: ONE SINGLE TRANSFORMER TO UNIFYMULTIMODAL UNDERSTANDING AND GENERATION
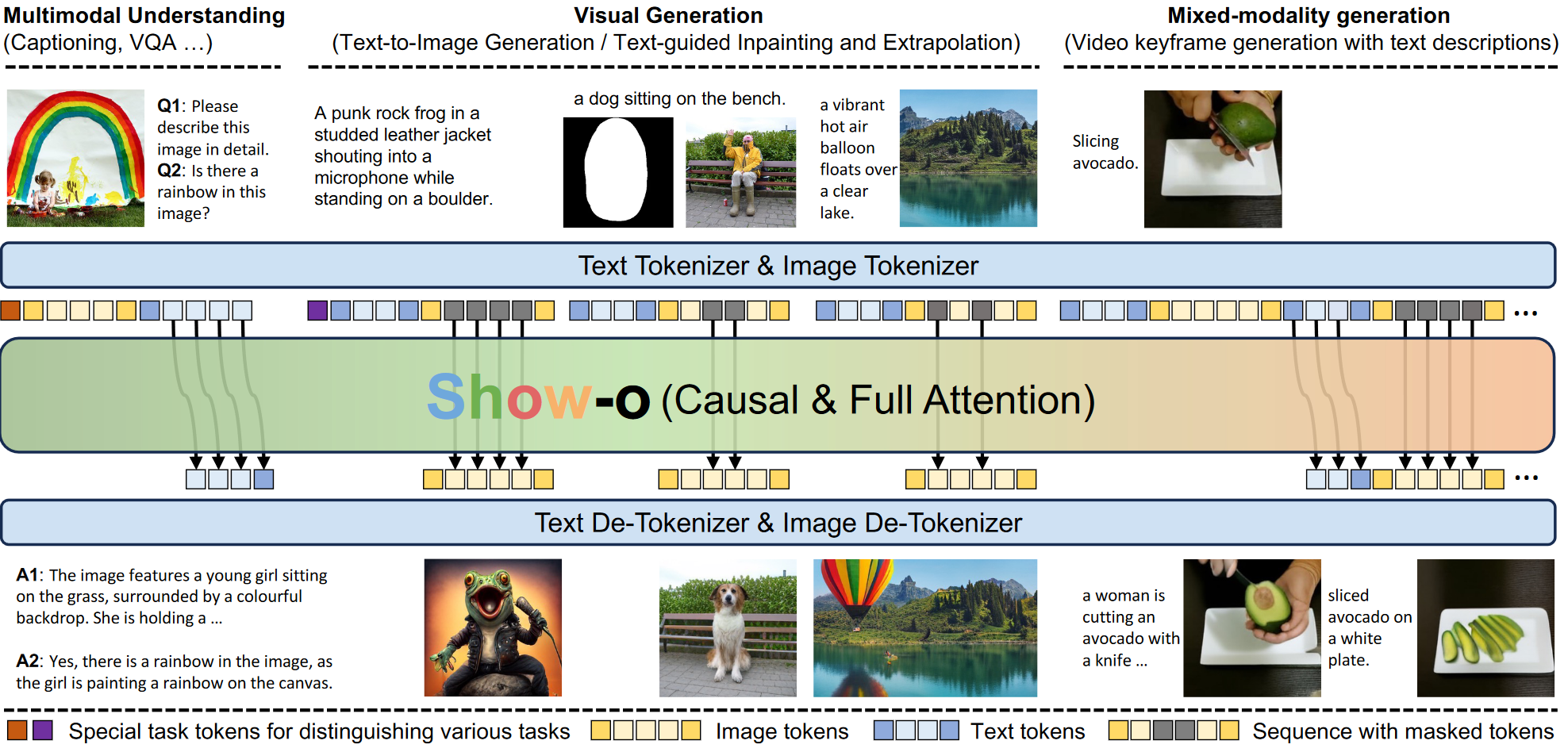
1 研究背景、动机、主要贡献 1.1 研究背景 现有的尝试主要是独立地对待每个领域,并且通常涉及单独负责理解和生成的模型。 1.2 主要贡献 提出了Show-o,一个能够同时处理多模态理解和生成任务的统一Transfo...
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
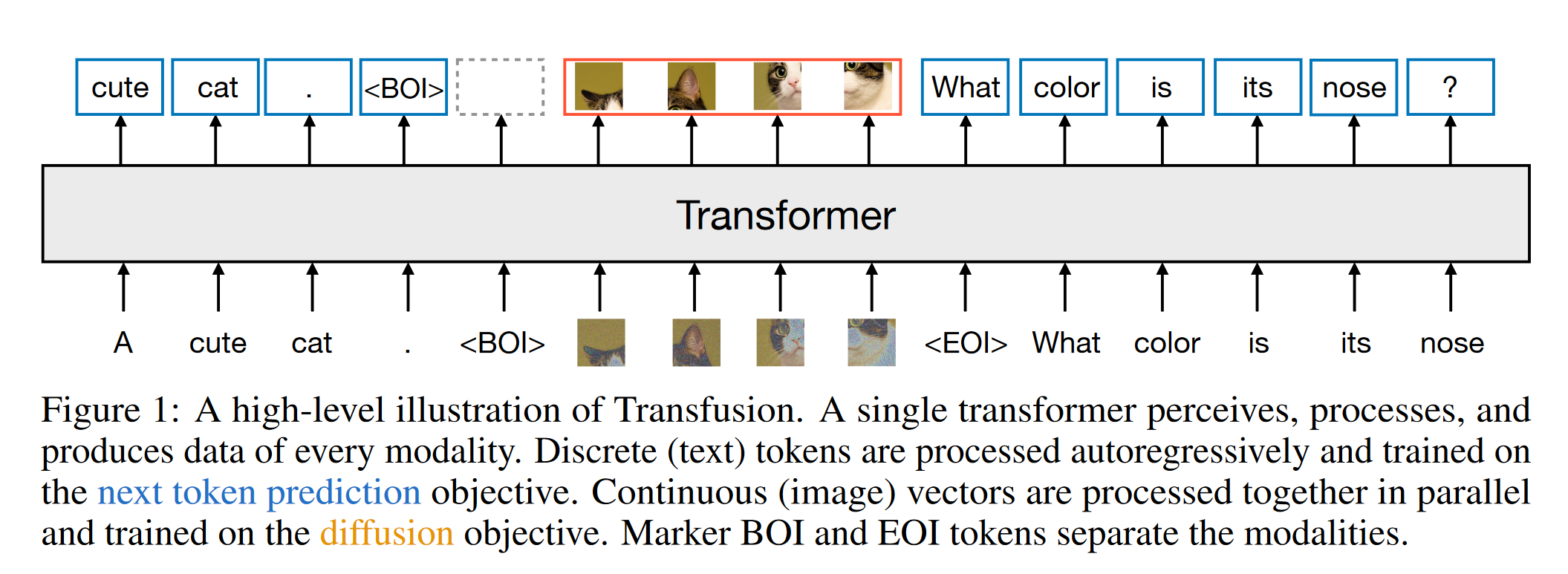
1 研究背景、动机、主要贡献 主要贡献 Transfusion方法的提出:通过将离散文本标记的预测和连续图像的扩散过程完全整合,Transfusion能够同时处理这两种模态,无信息损失。 多模态训练框架:论文展示了如何在一个统一...
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
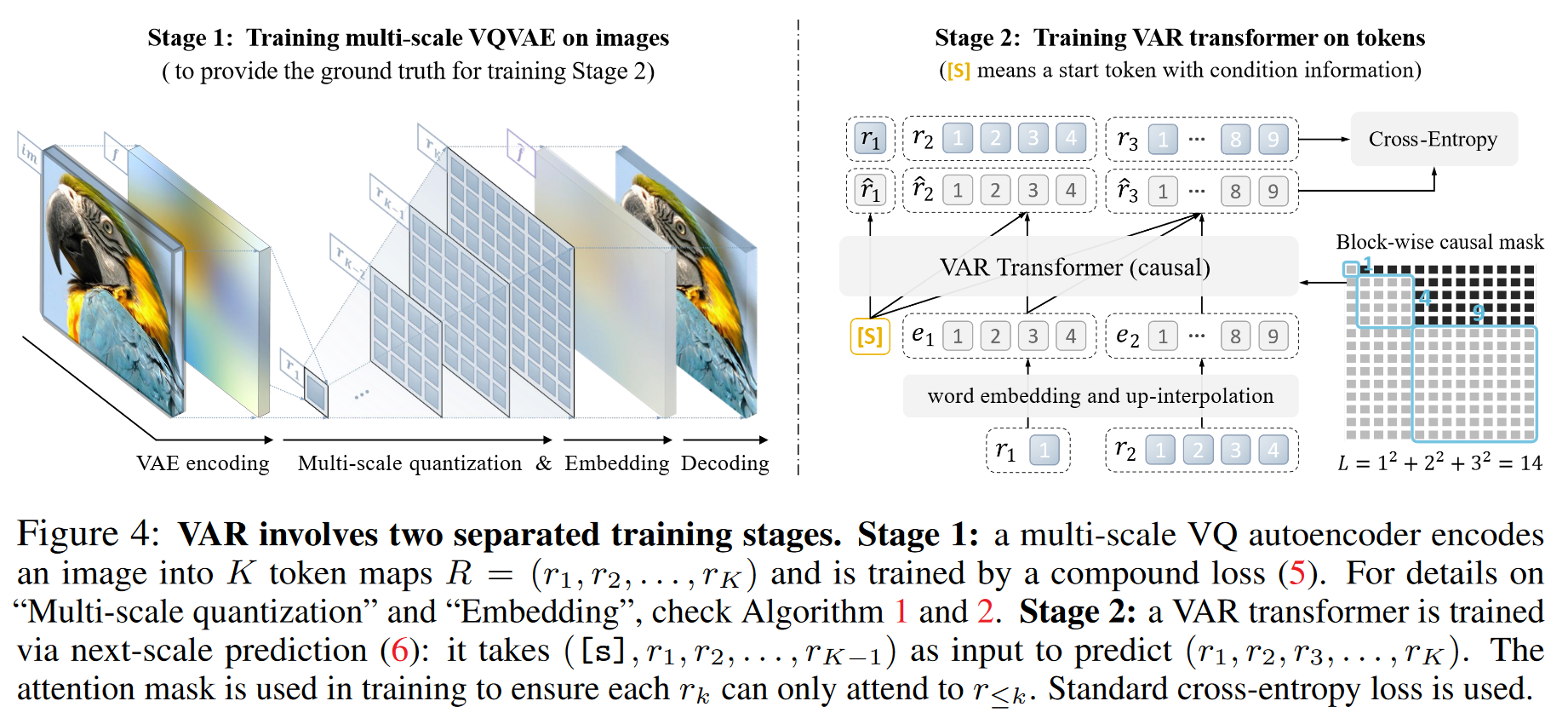
1 研究背景、动机、主要贡献 1.1 研究背景 标准自回归模型 vs. VAR AR在文本中的应用:按顺序从左到右逐个生成文本标记。 AR在图像中的应用:以类似的方式,从左到右、从上到下逐行生成图像的视觉标记,类似于在文本...

Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
1 研究背景 基于自回归模型的 LLMs 取得了显著进展,部分研究开始探讨自回归模型在图像生成领域的应用,并引入图像标记化技术将连续图像转换为离散标记,从而实现图像标记的生成。 2 论文提出的新思路、新理论、或新方法 首先,...
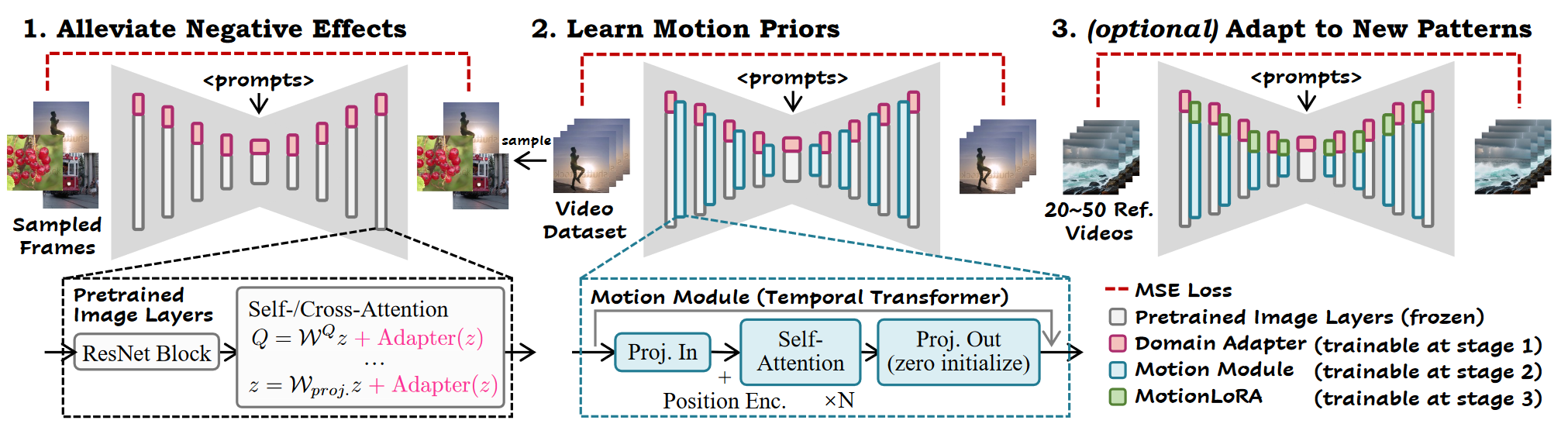
ANIMATEDIFF: ANIMATE YOUR PERSONALIZEDTEXT-TO-IMAGE DIFFUSION MODELS WITHOUT SPECIFIC TUNING
1. 研究背景、动机 在视频生成领域,通常通过时间结构来扩展预训练的T2I模型,但这些方法通常更新所有参数,修改原始T2I模型的特征空间,因此与个性化 T2I 模型不兼容。 预备知识 Stable Diffusion L...
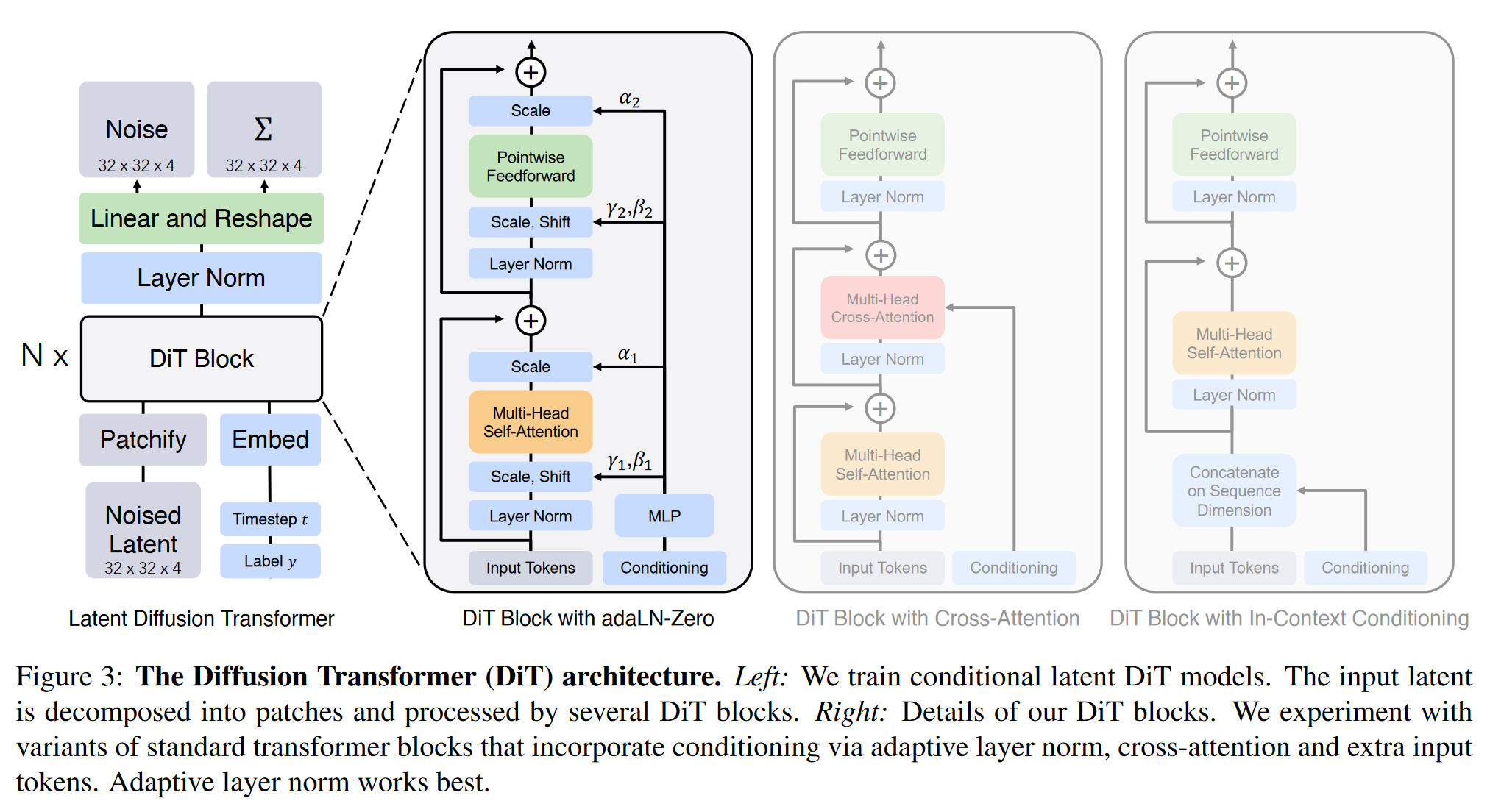
Scalable Diffusion Models with Transformers
1. 研究背景、动机、主要贡献 传统的扩散模型大多采用U-Net作为主干网络,LDM ( High-Resolution Image Synthesis with Latent Diffusion Models ) 也只是通过交...