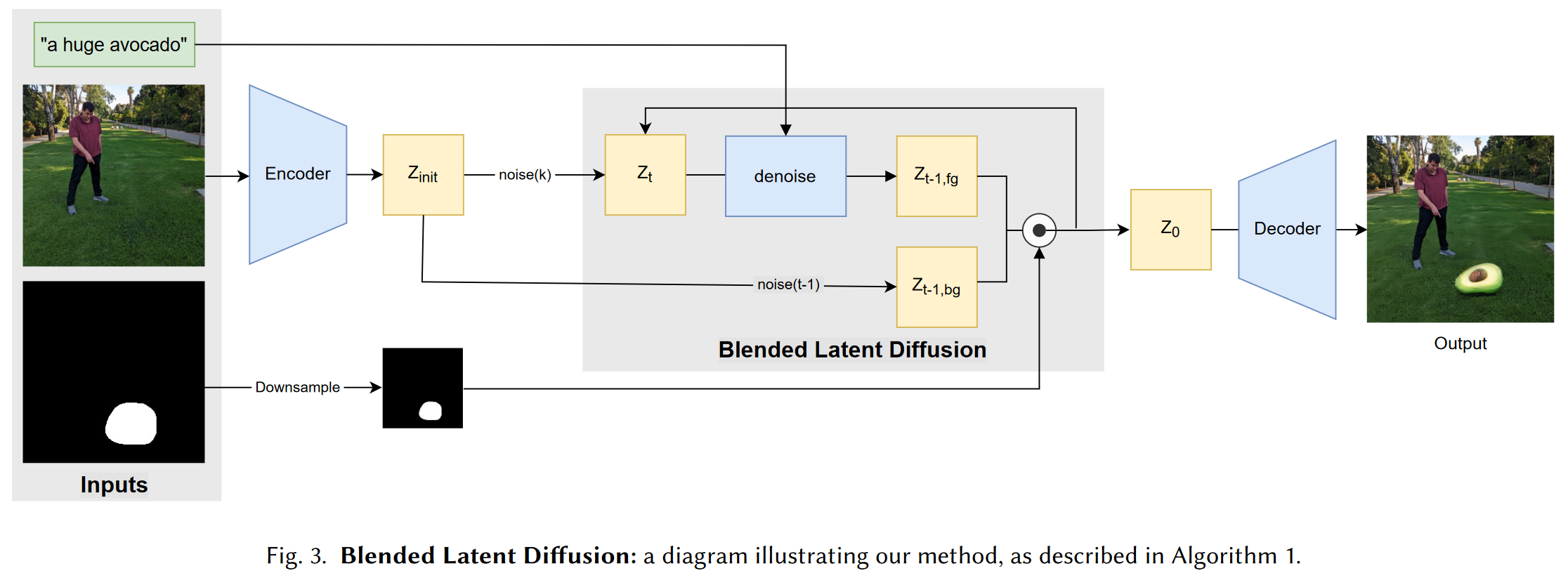
1 研究背景、动机、主要贡献 1.1 研究背景 GAN的崛起,扩散模型迅速发展,视觉-语言模型(如CLIP)的发展,Blended Diffusion 的提出。 1.2 存在问题(动机) 1.2.1 现有方案 Blende...
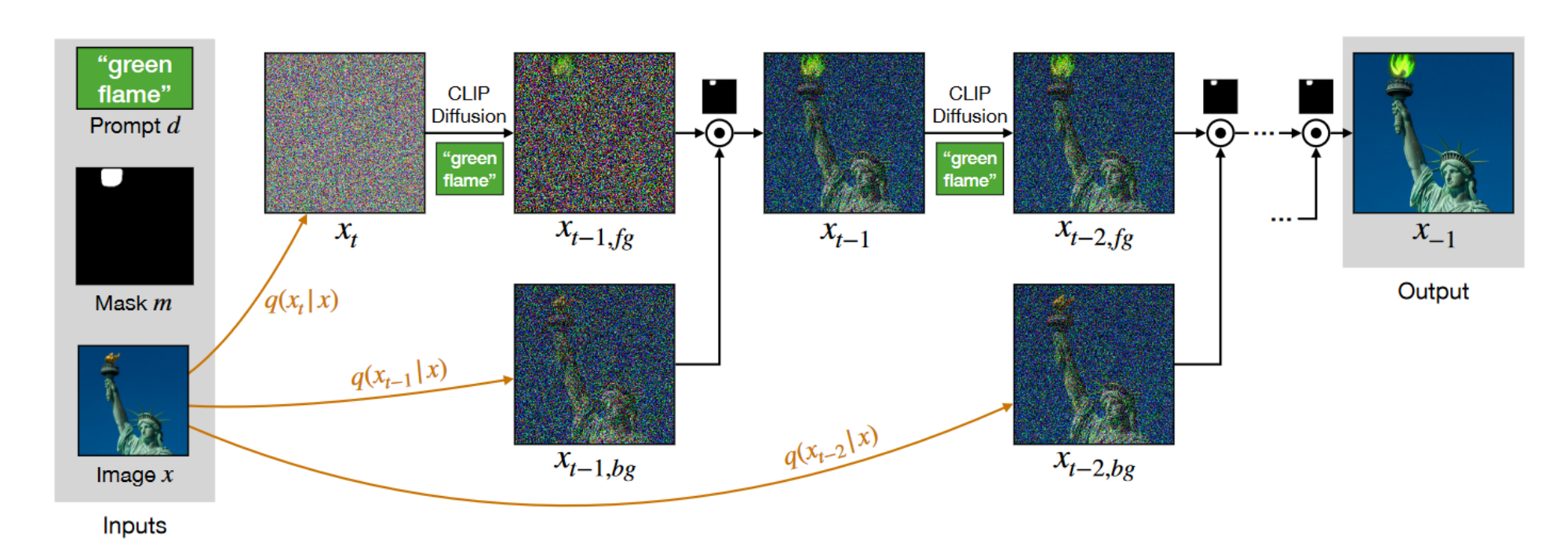
Blended Diffusion for Text-driven Editing of Natural Images
1 研究背景、动机、主要贡献 1.1 研究背景 文本生成图像的进展使得通过自然语言生成和编辑图像变得可行。特别是,基于 GAN 的方法在文本驱动的图像生成上取得了显著效果。 1.2 存在问题(动机) 1.2.1 现有方案 ...
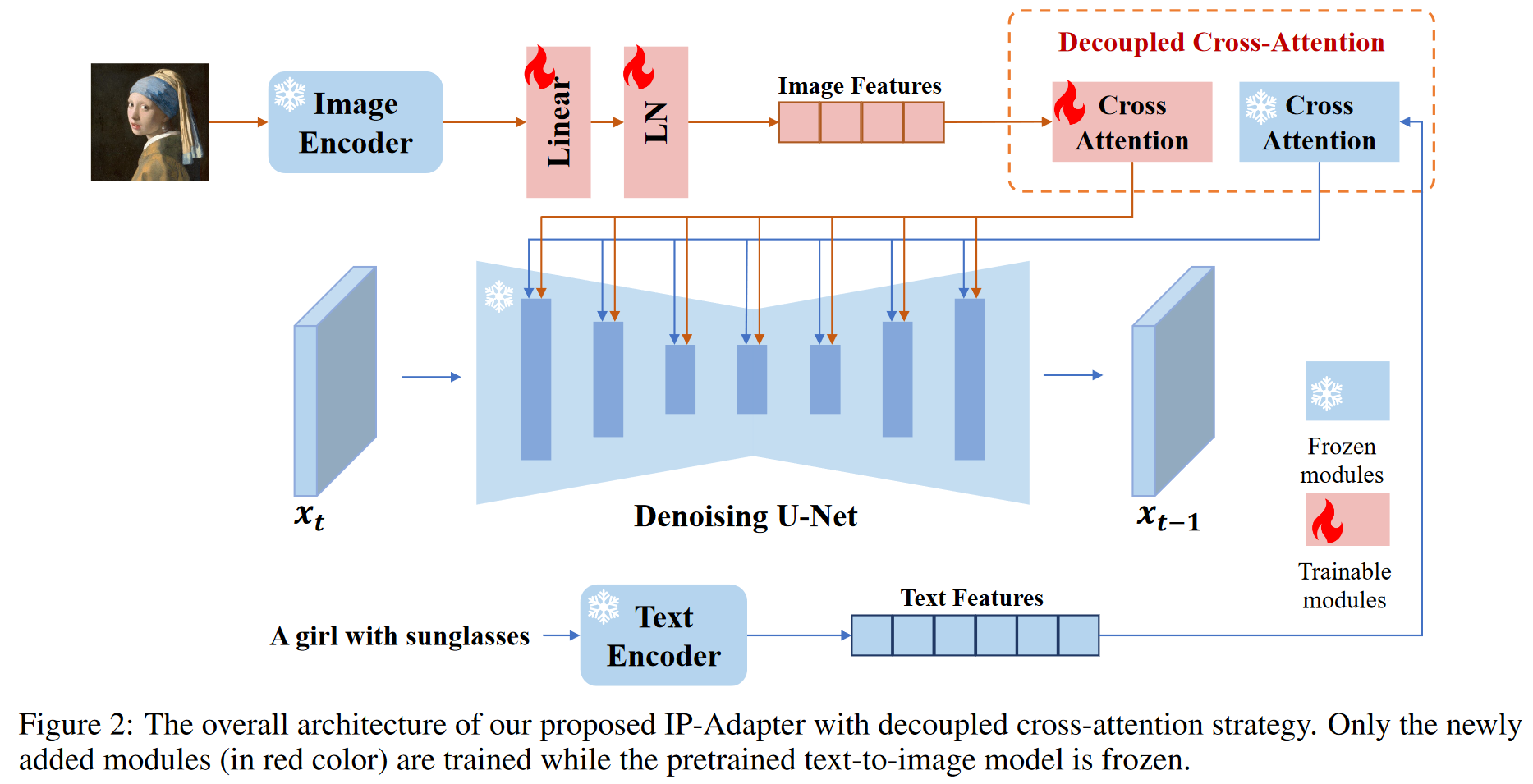
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
1 研究背景、动机、主要贡献1.1 研究背景近年来,大型文本生成图像扩散模型(如GLIDE、DALL-E 2、Stable Diffusion等)取得了显著进展,能够根据文本提示生成高保真图像。然而,生成理想的图像通常需要复杂的提示词...
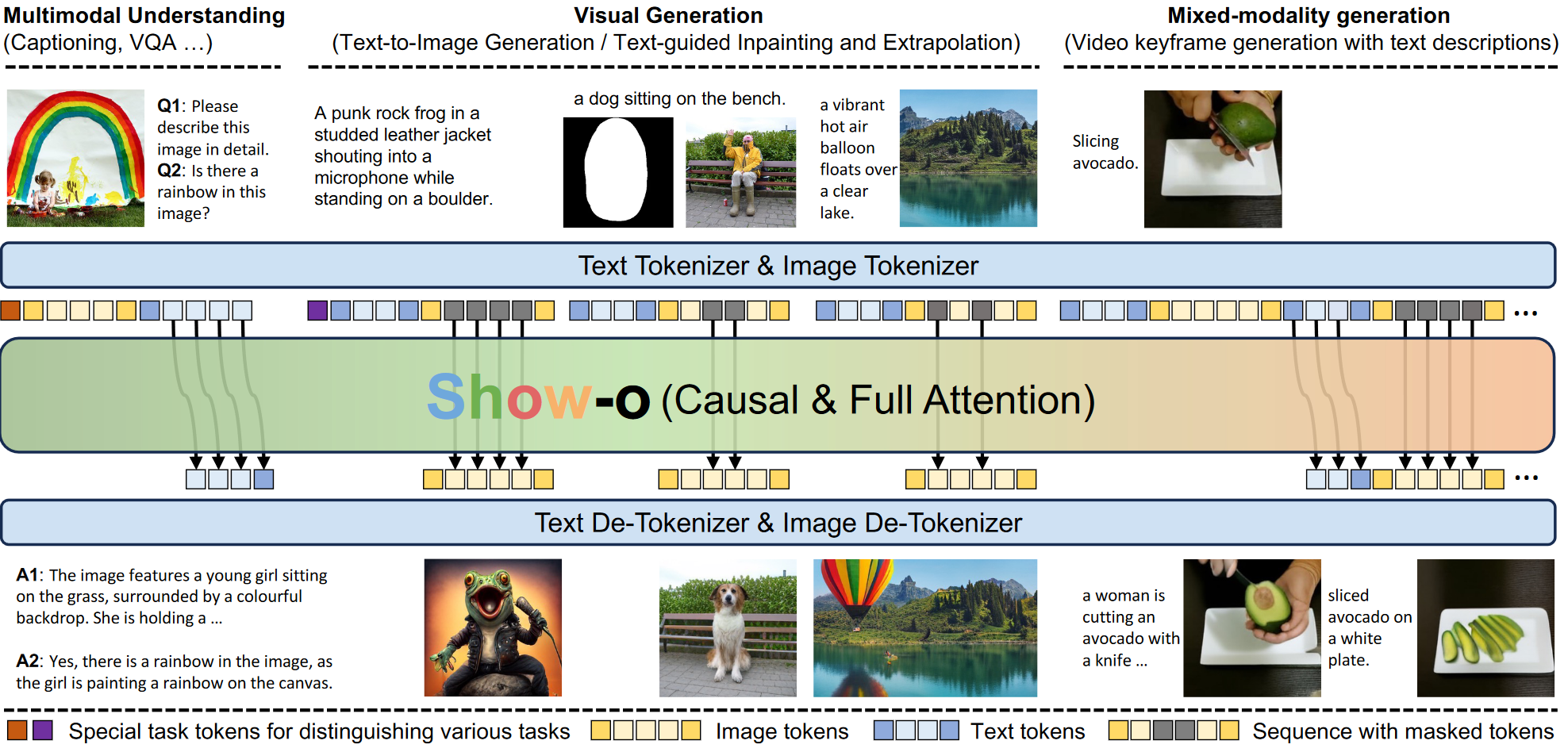
SHOW-O: ONE SINGLE TRANSFORMER TO UNIFYMULTIMODAL UNDERSTANDING AND GENERATION
1 研究背景、动机、主要贡献 1.1 研究背景 现有的尝试主要是独立地对待每个领域,并且通常涉及单独负责理解和生成的模型。 1.2 主要贡献 提出了Show-o,一个能够同时处理多模态理解和生成任务的统一Transfo...
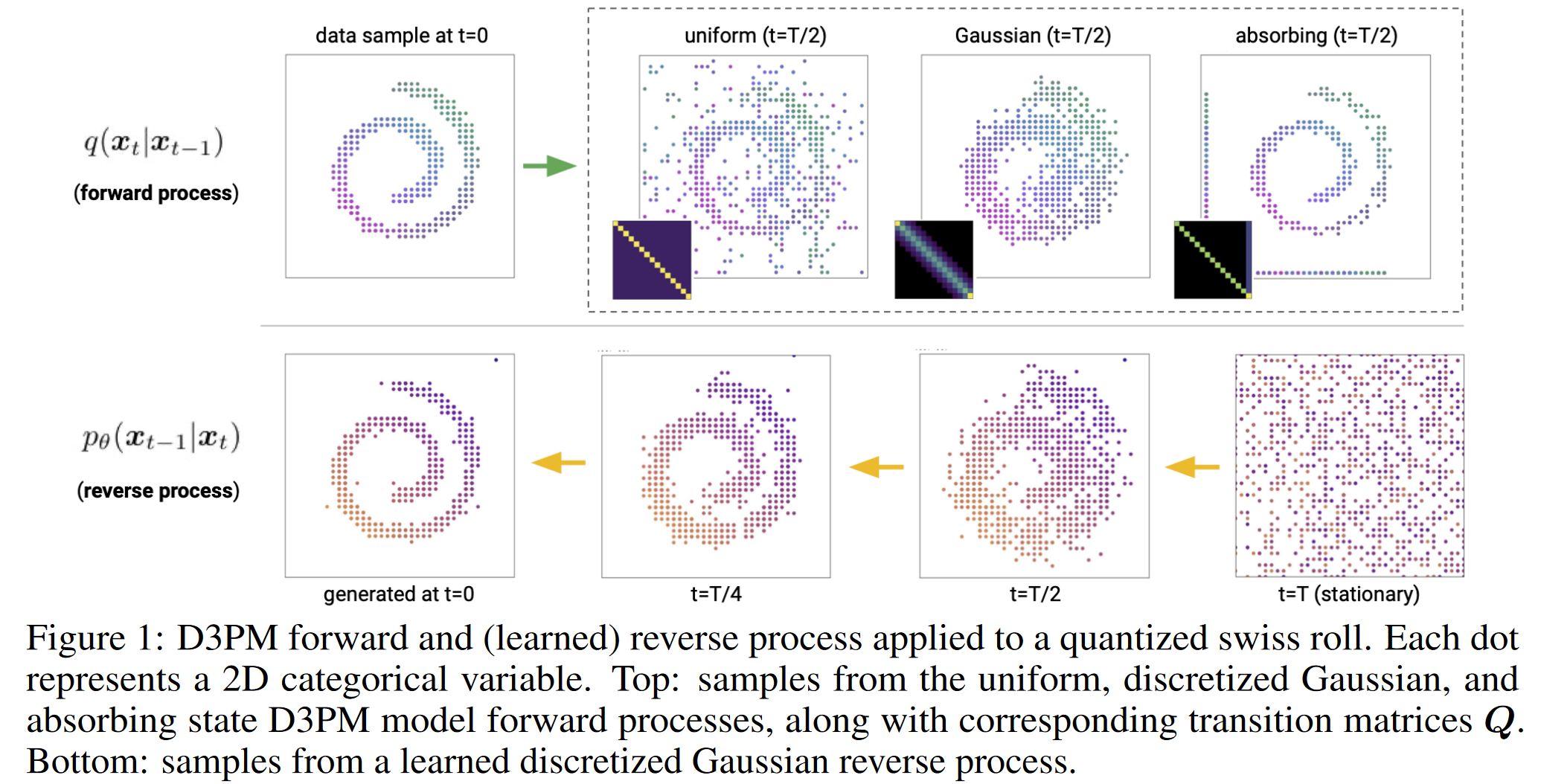
Structured Denoising Diffusion Models in Discrete State-Spaces
1 研究背景、动机、主要贡献 1.1 研究背景 尽管扩散模型在连续数据上表现良好,但在离散数据(如文本或量化后的图像)上的应用仍然有限。现有的离散扩散模型主要集中在文本和图像分割领域,尚未在大规模文本或图像生成任务上展示出竞争力。...
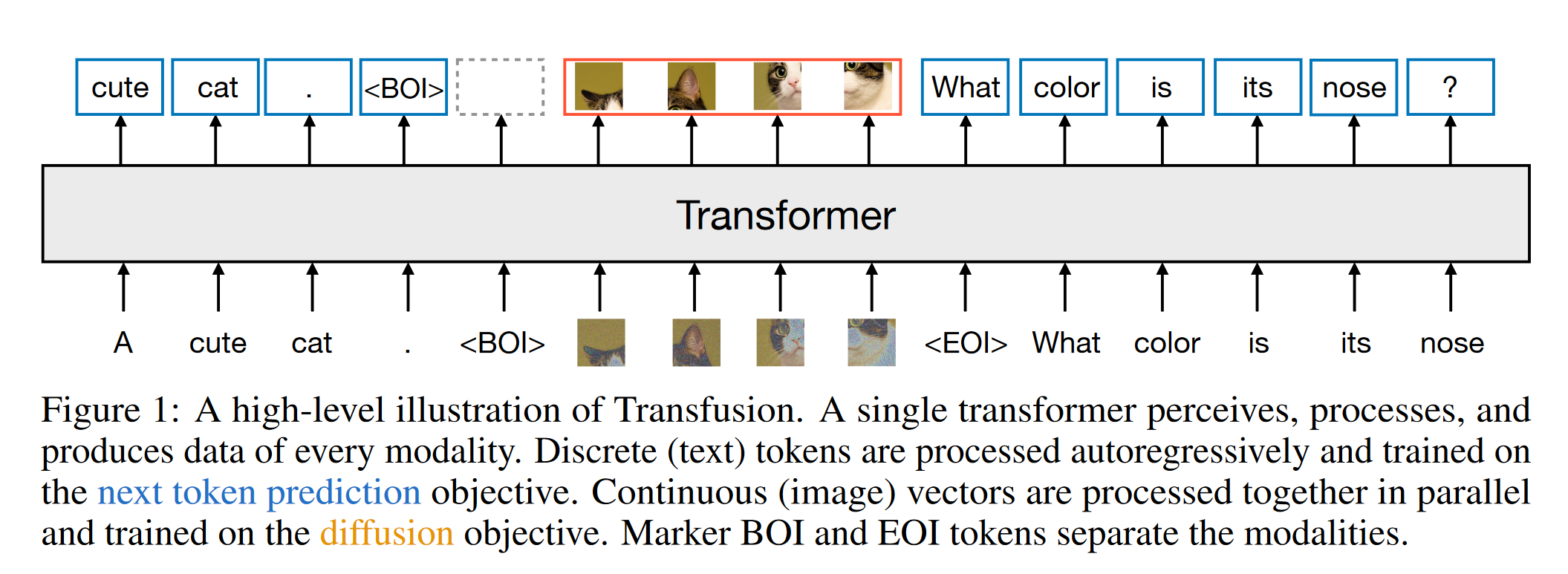
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
1 研究背景、动机、主要贡献 主要贡献 Transfusion方法的提出:通过将离散文本标记的预测和连续图像的扩散过程完全整合,Transfusion能够同时处理这两种模态,无信息损失。 多模态训练框架:论文展示了如何在一个统一...
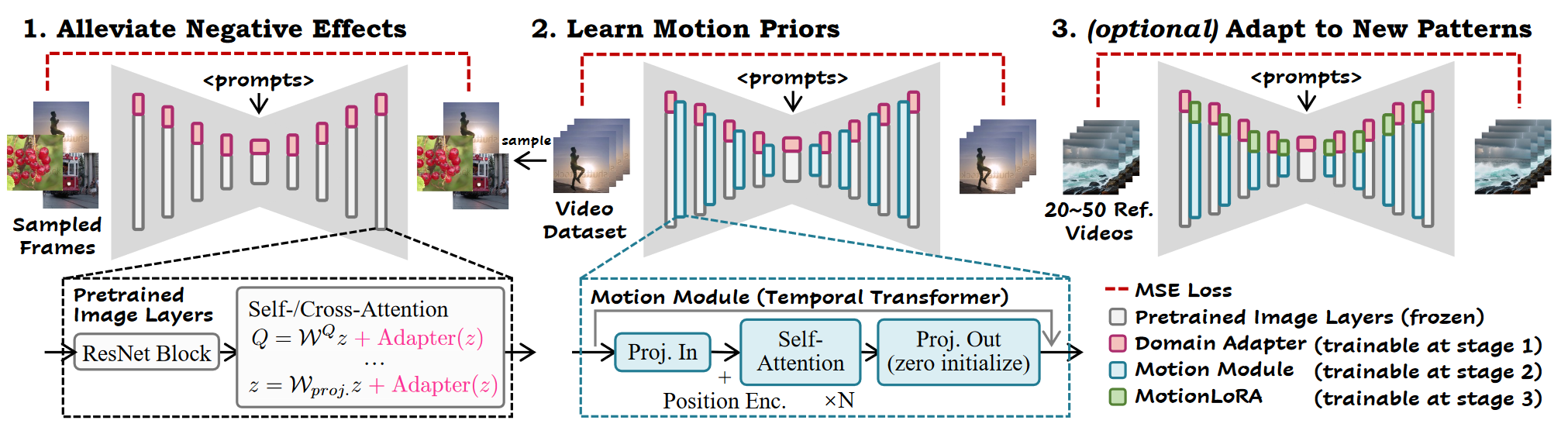
ANIMATEDIFF: ANIMATE YOUR PERSONALIZEDTEXT-TO-IMAGE DIFFUSION MODELS WITHOUT SPECIFIC TUNING
1. 研究背景、动机 在视频生成领域,通常通过时间结构来扩展预训练的T2I模型,但这些方法通常更新所有参数,修改原始T2I模型的特征空间,因此与个性化 T2I 模型不兼容。 预备知识 Stable Diffusion L...
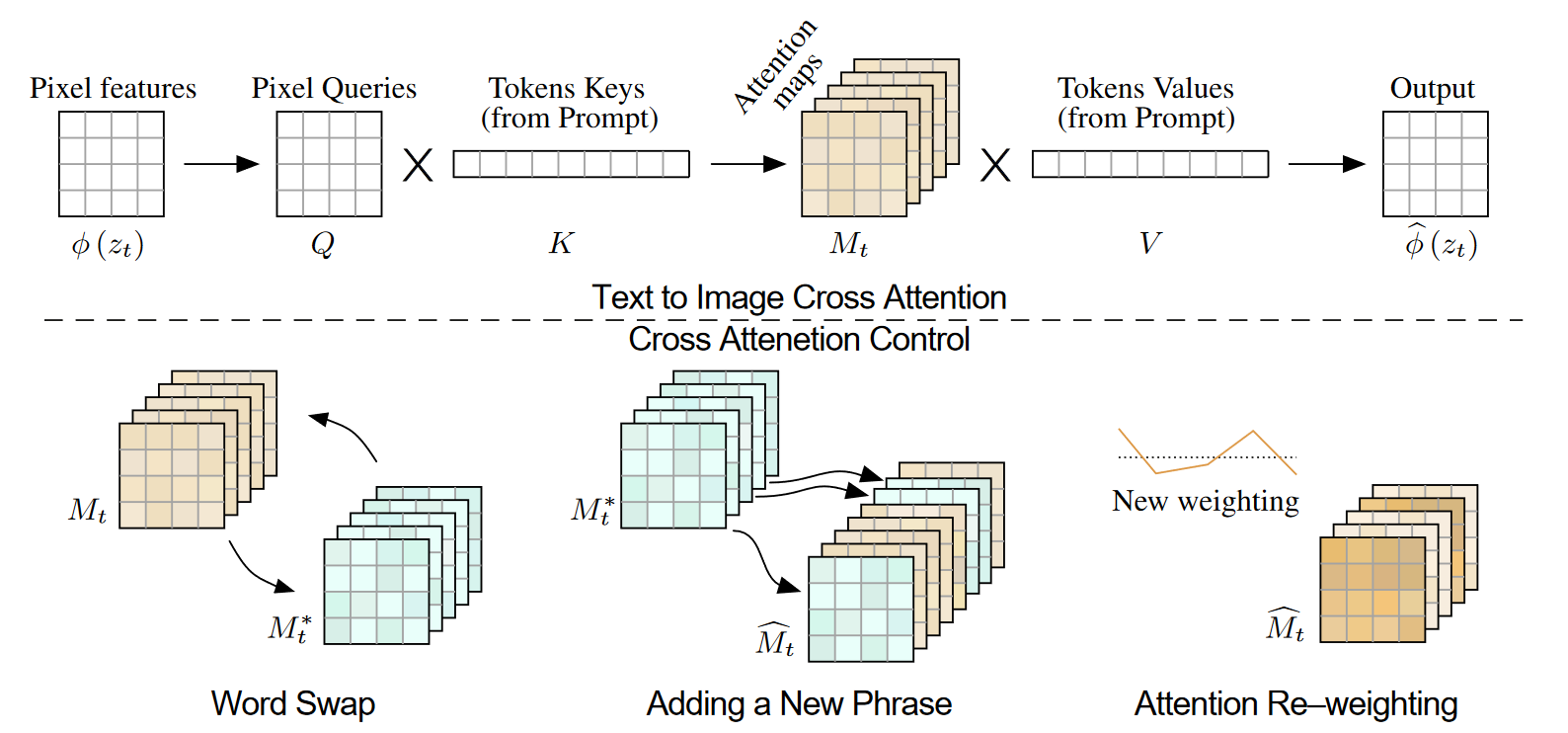
Prompt-to-Prompt Image Editing with Cross Attention Control
1. 研究背景、动机、主要贡献 1.1 研究背景 像Imagen、DALL·E 2和Parti等LLI模型,展示了出色的语义生成和组合能力,但它们在图像编辑方面存在控制力不足的问题。即使是对文本提示的轻微修改,生成的图像也可能完...
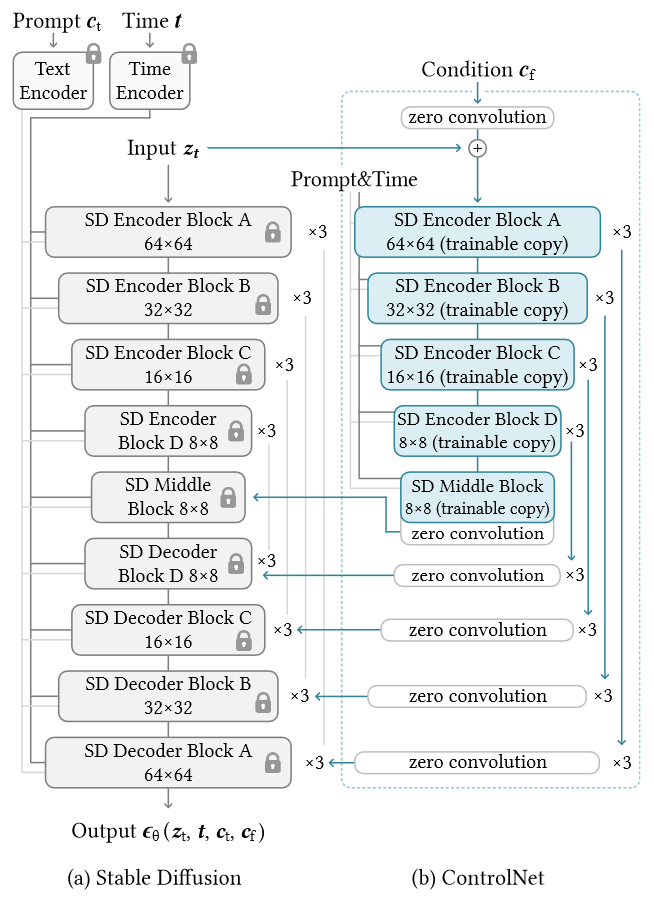
Adding Conditional Control to Text-to-Image Diffusion Models
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 文本到图像模型在对图像的空间组成提供的控制方面受到限制。仅通过文本提示来精确表达复杂的布局、姿势、形状和形式可能很困难。生成与我们的心理想象准确匹配的图像通常需要多次反...
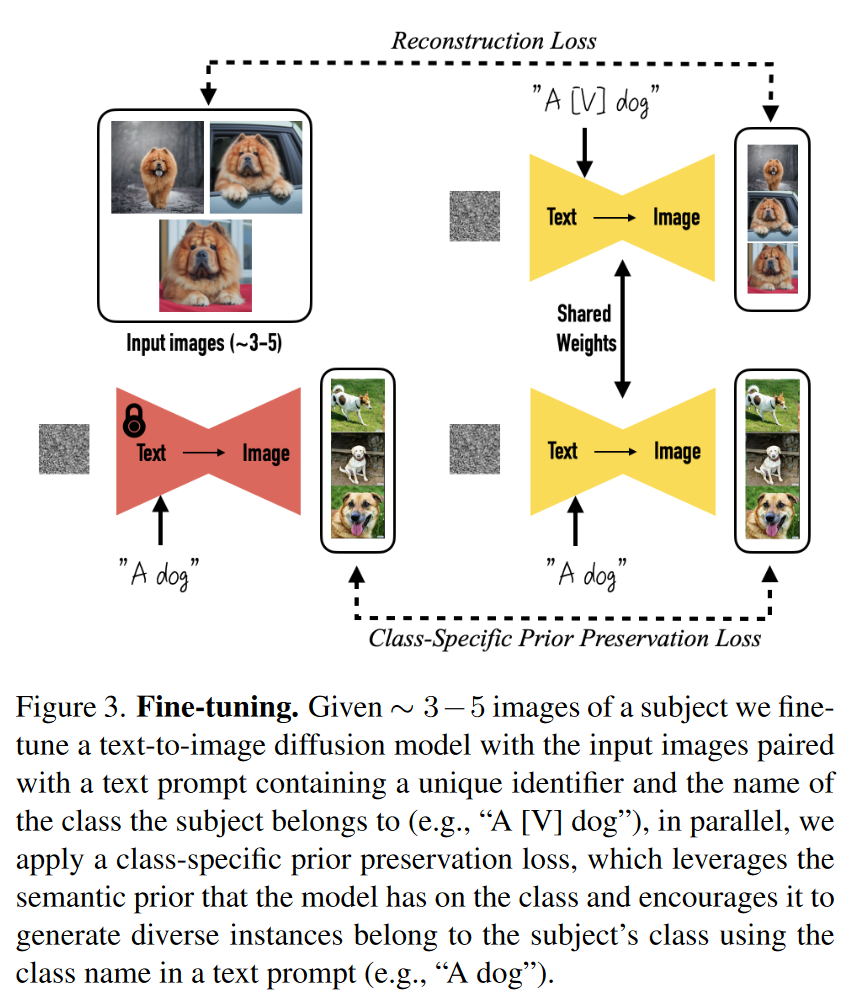
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 现有的文本到图像生成模型可以根据文本提示生成高质量和多样化的图像,但它们无法在不同的场景中一致地再现特定主体。 因为即使使用详细的文本描述,现有模型的输出域表达力有限,生...