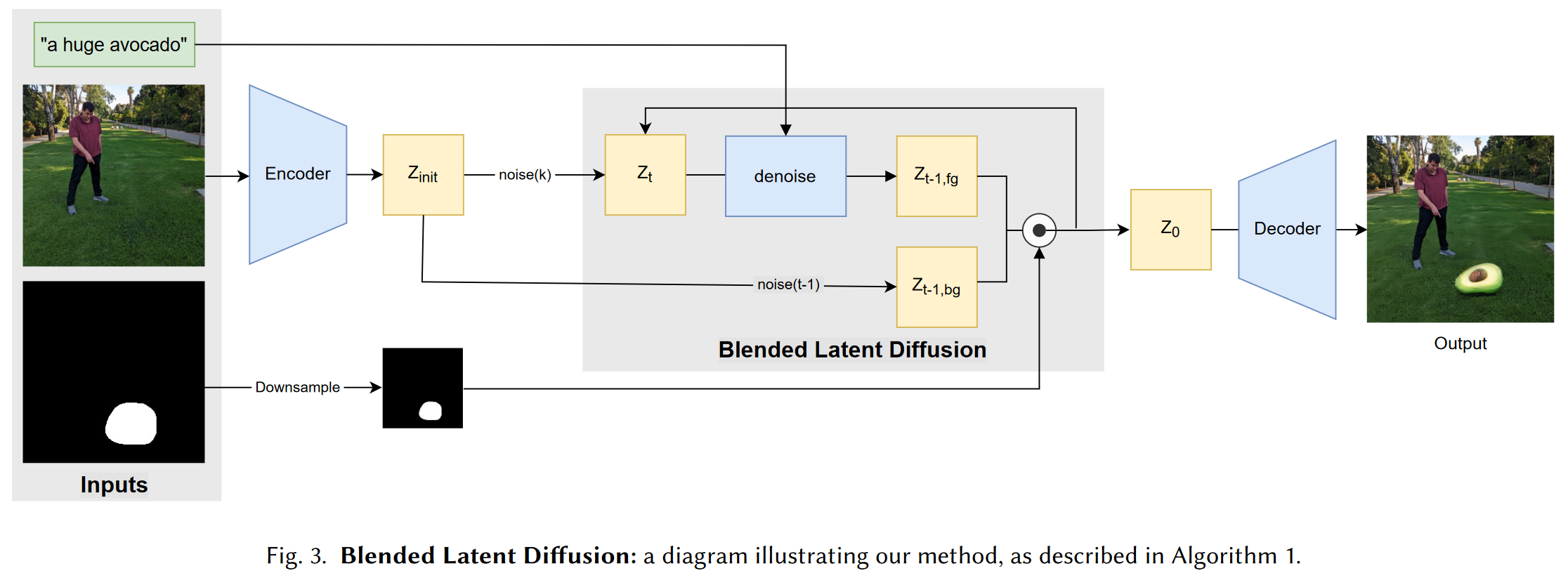
1 研究背景、动机、主要贡献 1.1 研究背景 GAN的崛起,扩散模型迅速发展,视觉-语言模型(如CLIP)的发展,Blended Diffusion 的提出。 1.2 存在问题(动机) 1.2.1 现有方案 Blende...
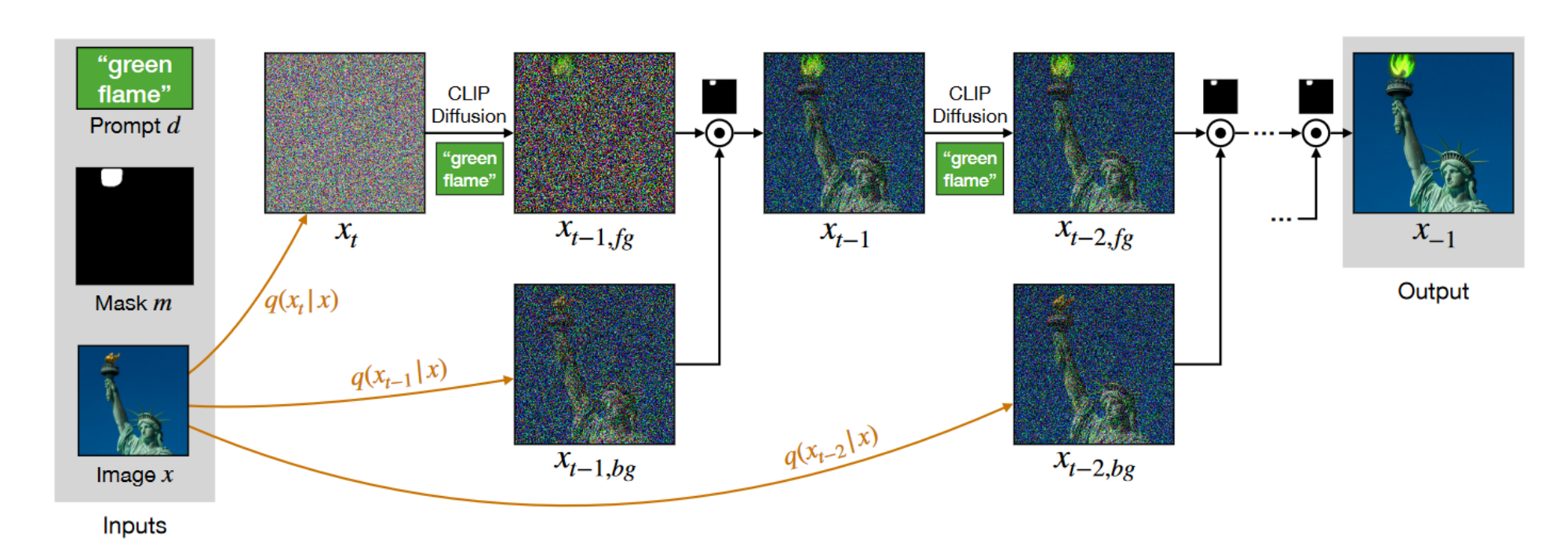
Blended Diffusion for Text-driven Editing of Natural Images
1 研究背景、动机、主要贡献 1.1 研究背景 文本生成图像的进展使得通过自然语言生成和编辑图像变得可行。特别是,基于 GAN 的方法在文本驱动的图像生成上取得了显著效果。 1.2 存在问题(动机) 1.2.1 现有方案 ...
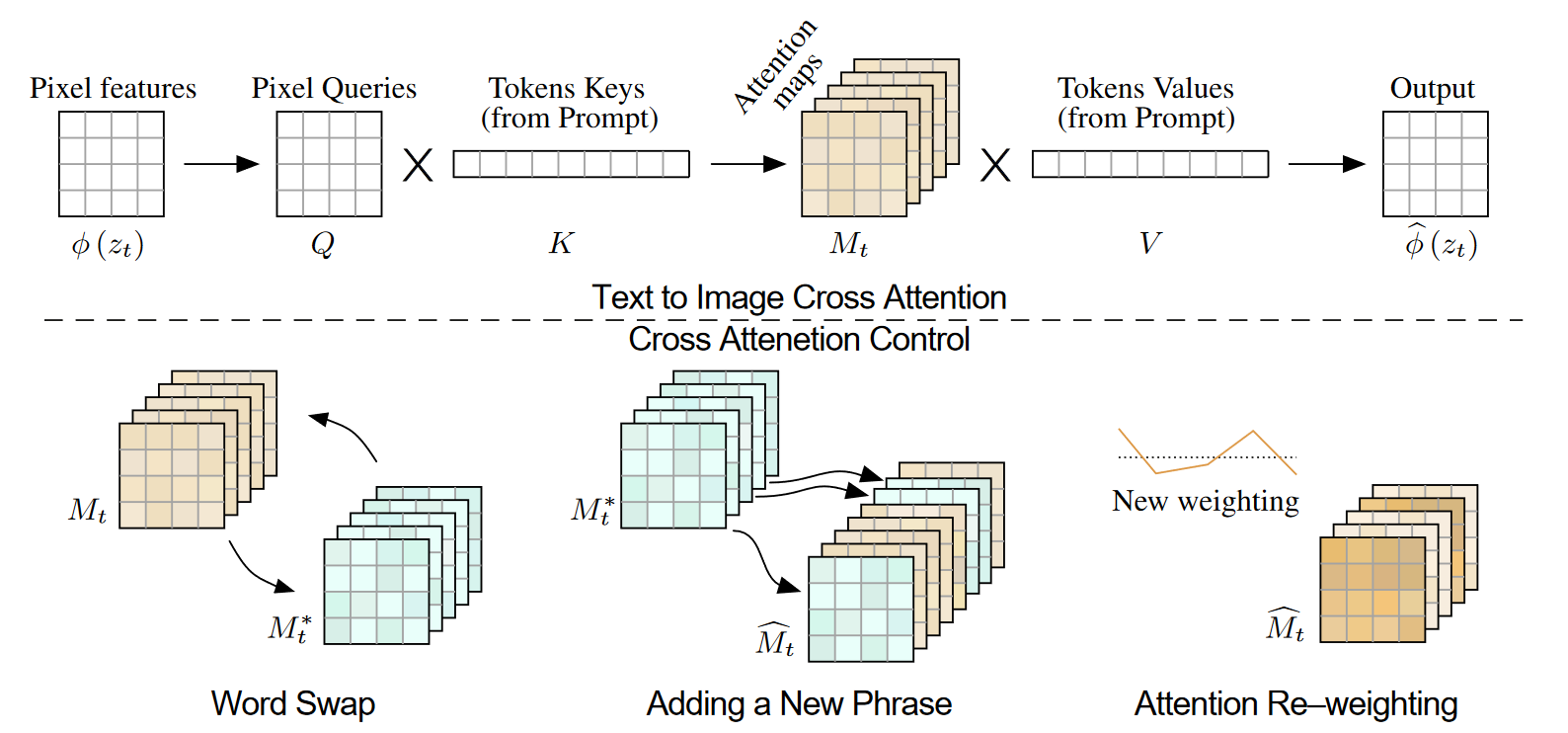
Prompt-to-Prompt Image Editing with Cross Attention Control
1. 研究背景、动机、主要贡献 1.1 研究背景 像Imagen、DALL·E 2和Parti等LLI模型,展示了出色的语义生成和组合能力,但它们在图像编辑方面存在控制力不足的问题。即使是对文本提示的轻微修改,生成的图像也可能完...
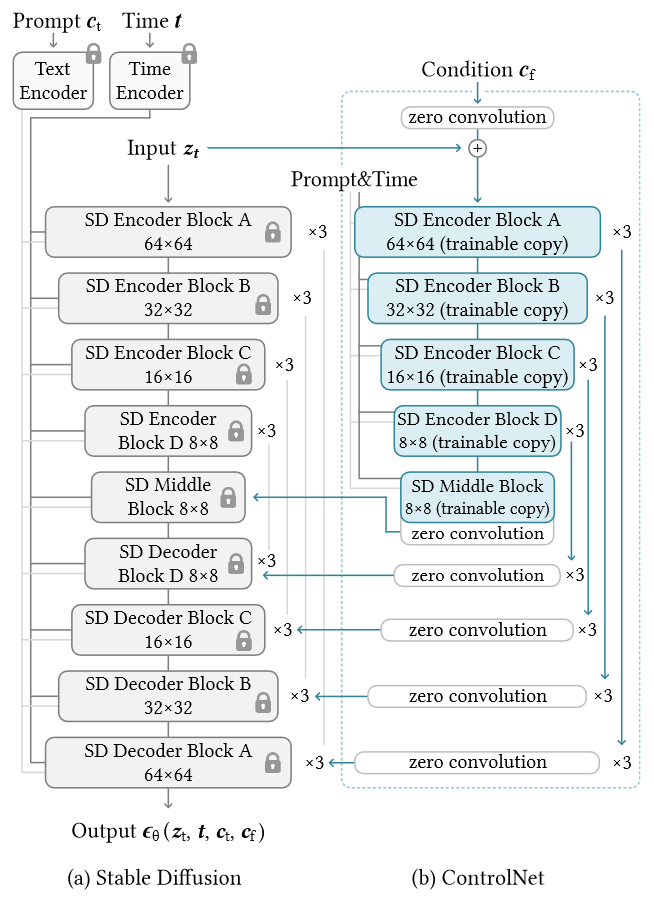
Adding Conditional Control to Text-to-Image Diffusion Models
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 文本到图像模型在对图像的空间组成提供的控制方面受到限制。仅通过文本提示来精确表达复杂的布局、姿势、形状和形式可能很困难。生成与我们的心理想象准确匹配的图像通常需要多次反...
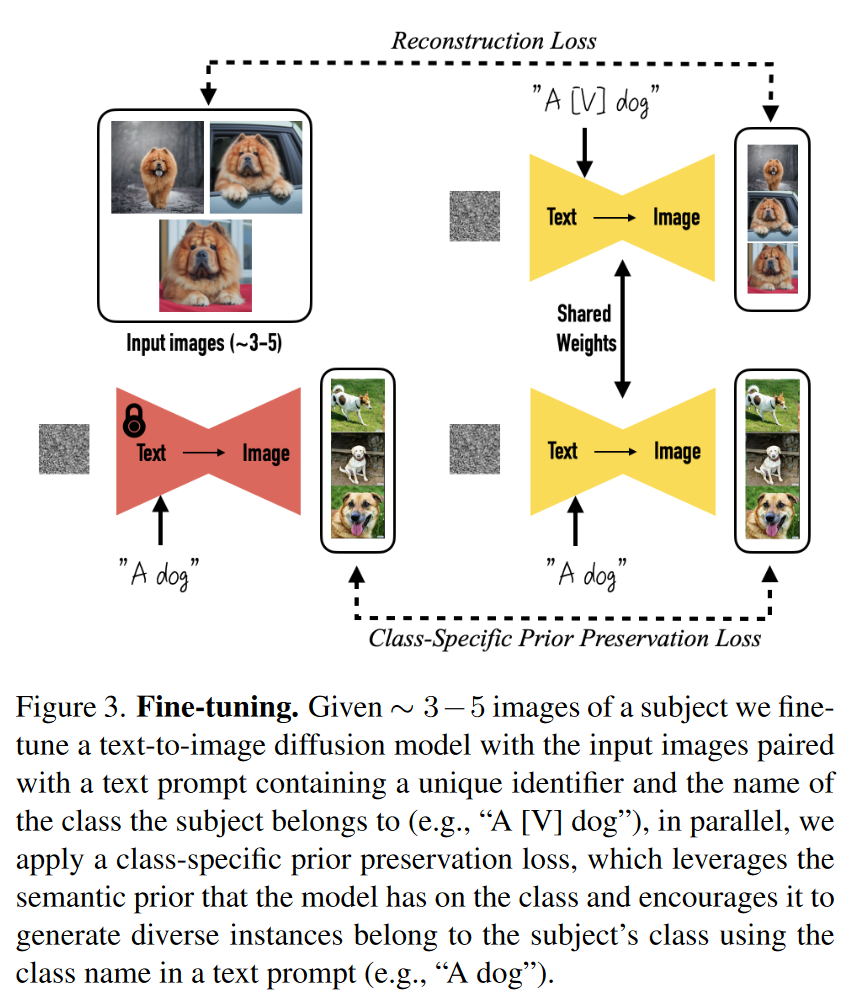
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 现有的文本到图像生成模型可以根据文本提示生成高质量和多样化的图像,但它们无法在不同的场景中一致地再现特定主体。 因为即使使用详细的文本描述,现有模型的输出域表达力有限,生...
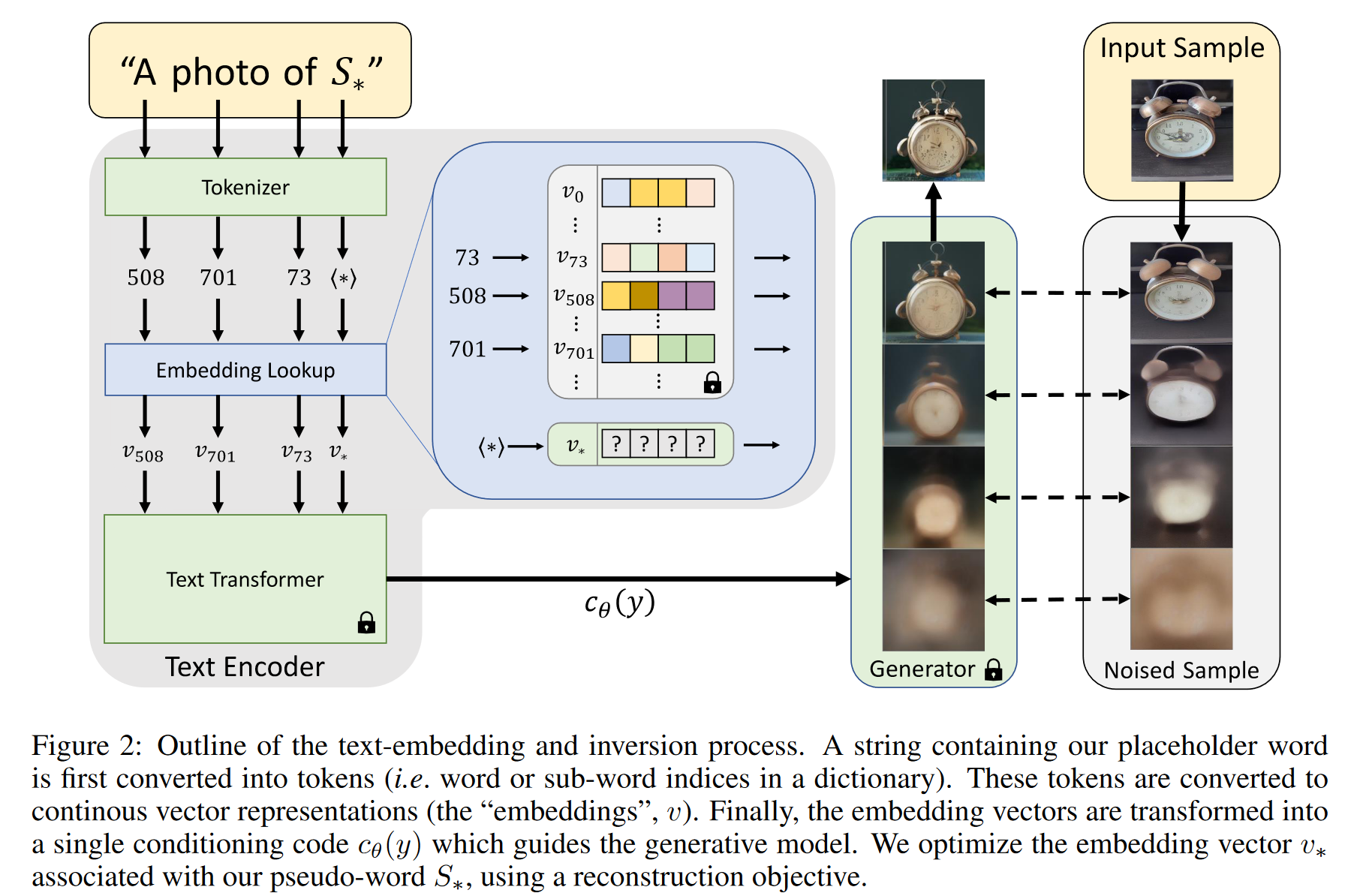
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
1. 研究背景、动机、主要贡献 引入新概念到大模型中往往是困难的。因为重新训练模型非常昂贵,而仅用少量示例进行微调通常会导致“灾难性遗忘”——模型忘记了先前学到的知识。尽管有些方法通过冻结模型并训练转换模块来适应新概念,但这些方法依...