1 研究背景、动机、主要贡献
1.1 研究背景
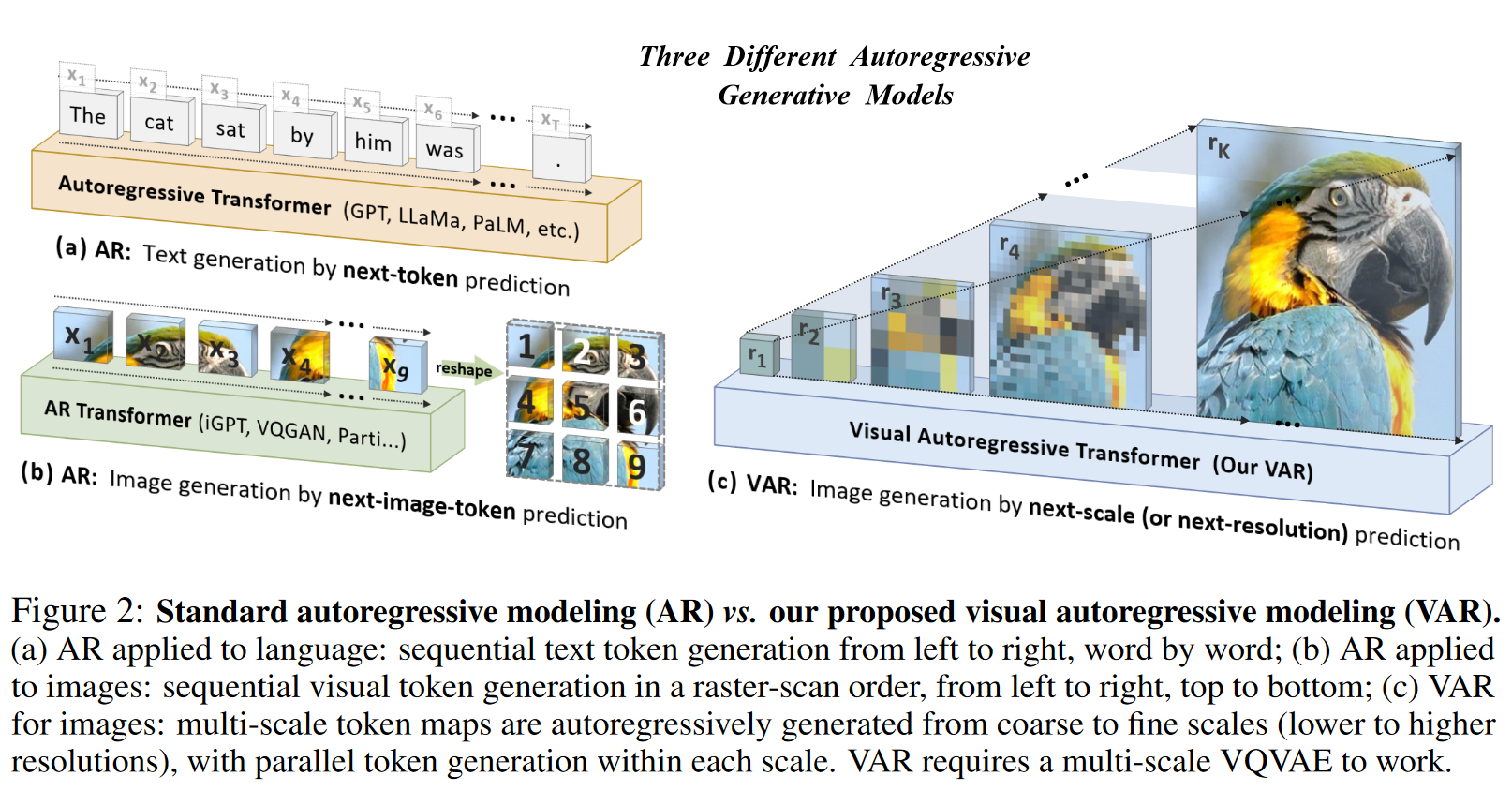
标准自回归模型 vs. VAR
- AR在文本中的应用:按顺序从左到右逐个生成文本标记。
- AR在图像中的应用:以类似的方式,从左到右、从上到下逐行生成图像的视觉标记,类似于在文本生成中一行一行地产生像素。
- VAR的图像建模:采用多尺度的方式,从粗略到精细的分辨率生成图像。每个尺度的标记是并行生成的。这种生成方式需要多尺度的VQ-VAE来支持。
related work
- Properties of large autoregressive language models
- Scaling laws
- 能够直接从较小的模型预测较大模型的性能
- Zero-shot generalization.
- Scaling laws
- Visual generation
- Raster-scan autoregressive models
- VQGAN和VQVAE
- Masked-prediction model.
- Diffusion models
- Raster-scan autoregressive models
1.2 主要贡献
- 传统自回归模型逐标记生成图像,而VAR认为人类感知图像是从全局结构到局部细节的层次化过程,因此采用从粗到细、从低分辨率到高分辨率的方式生成图像。每个分辨率内的标记是并行生成的,而非依赖逐行逐列生成。
- VAR在性能上首次超越了 DiT ,使得GPT式自回归方法在图像合成中首次超越强扩散模型。在多个维度(包括图像质量、推理速度、数据效率和可扩展性)上表现更优。
- 开源代码套件
2 论文提出的新方法
2.1 Preliminary: autoregressive modeling via next-token prediction
next-token prediction
- 要将next-token prediction应用于图像生成,必须先将图像标记化(将图像转换为离散的标记)并将2D图像标记序列化为1D序列。
将特征图
转换为离散标记 . 量化过程
会将每个特征向量 映射到欧几里德意义上最接近的 code 的code index (相当于就是把连续的、无限的化为离散的有限的) 由重建误差、特征误差、感知损失、判别损失组成
图像的标记需要排列为 1D 序列,常用的方法是光栅扫描、螺旋顺序或 Z 曲线顺序。
Discussion on the weakness of vanilla autoregressive models.
- Mathematical premise violation.
- 在 VQVAEs 中,编码器生成的图像特征图 f 是一个包含多个特征向量
的二维矩阵,这些特征向量之间是相互依赖的。在对这些特征进行量化和扁平化后,生成的令牌序列(如 )保留了二维特征向量之间的双向相关性。这与自回归模型的单向依赖假设相矛盾。 - 这一点导致了自回归模型在处理图像时的基本假设被破坏,使得模型的预测和生成能力受到限制。
- 在 VQVAEs 中,编码器生成的图像特征图 f 是一个包含多个特征向量
- Inability to perform some zero-shot generalization.
- 自回归模型的单向特性限制了其在需要双向推理的任务中的泛化能力。例如,它无法在给定底部的情况下预测图像的顶部。
- Structural degradation
- 在特征图中,像素(或令牌)之间的空间局部性很重要。例如,令牌
与其四个相邻令牌 在空间上是相关的。而扁平化过程破坏了这种空间局部性。
- 在特征图中,像素(或令牌)之间的空间局部性很重要。例如,令牌
- Inefficiency
- 生成图像令牌序列
需要多次自回归步骤。传统自回归模型的计算复杂度为 的自回归步骤和 的计算成本,效率非常低。
- 生成图像令牌序列
2.2 Visual autoregressive modeling via next-scale prediction
Reformulation.
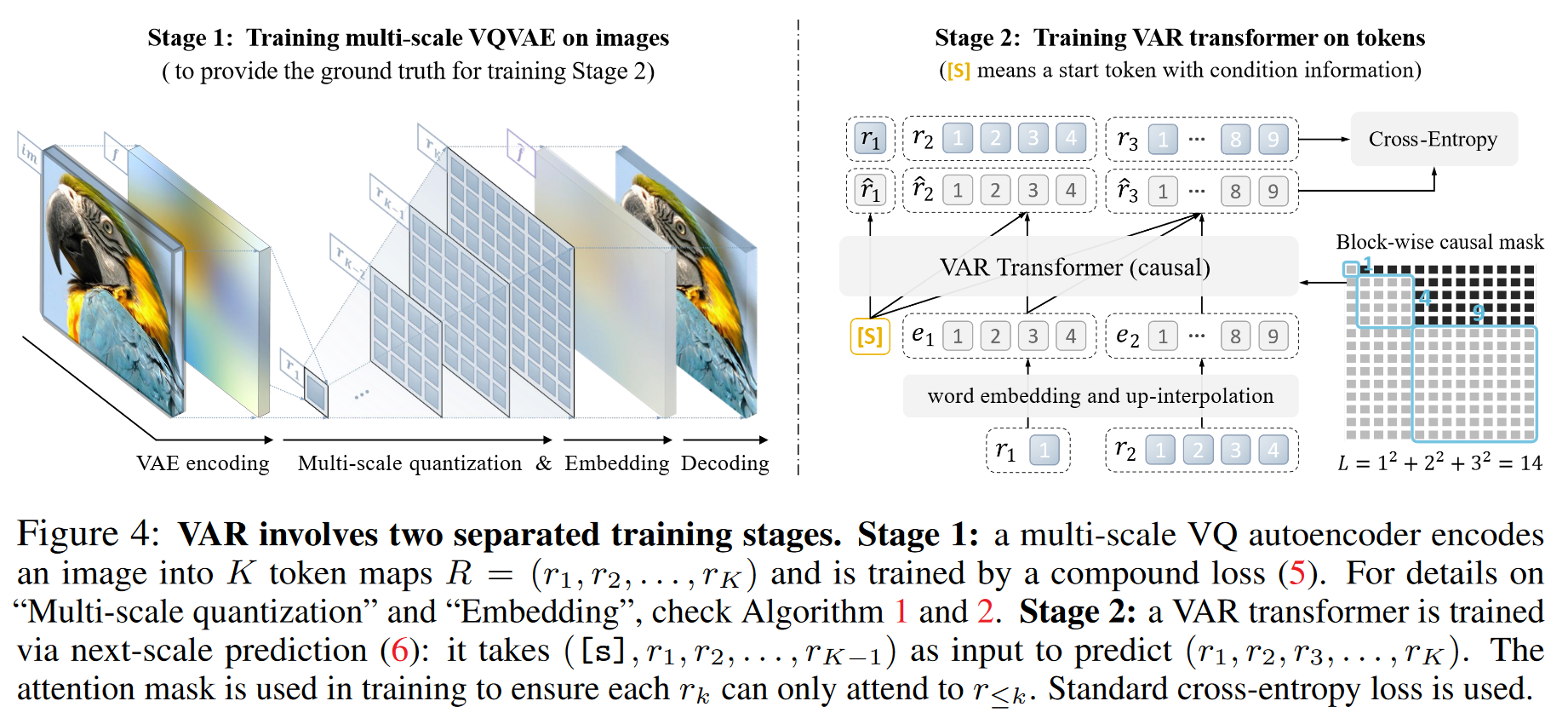
量化特征图 输入的特征图
。作者将其量化为 K 个多尺度令牌图, 每个令牌图的分辨率逐步提高,直到最后的 与原始特征图的分辨率相同。 自回归似然
。每个 的生成依赖于其之前的令牌图。 在第 k 步中,所有
中的 个令牌将被并行生成。 在VAR的训练中,使用块状因果注意力掩蔽,确保每个
只能关注其前缀 。 在推理阶段,可以使用 kv-caching ,提高效率。

- Multi-scale VQVAE Encoding
- transformer 根据特征图 f 预测更高的分辨率的令牌图,取 最接近的 code 的 code index 入队列
- transformer 根据 最接近的 code 的所有先前的令牌图预测更高的分辨率的令牌图
- f 减去已编码的特征,包含更细致的纹理和细节
- Multi-scale VQVAE Reconstruction
- R中 code index 出队列
- transformer 根据 最接近的 code 所有先前的令牌图预测更高的分辨率的令牌图
- f 每层循环都加上有更高分辨率的 code
Discussion.
VAR解决了传统自回归模型的一些问题:
- 数学前提的满足:
- 通过限制每个
只依赖于其前缀 ,确保了模型的数学假设得到满足。这种设计与人类视觉感知的“粗到细”特点相符。
- 通过限制每个
- 空间局部性的保留:
- VAR中没有平坦化操作,同时每个
中的令牌是完全相关的。更好地保留图像的空间结构。
- VAR中没有平坦化操作,同时每个
- 生成复杂度的降低:
- 生成一个
的图像序列的复杂度降低到了 。这种效率增益来自于每个 中的并行令牌生成。
- 生成一个
Tokenization.
开发了一种新的多尺度量化自编码器,该自编码器将图像编码为 K 个多尺度离散令牌图
。 使用与 VQGAN 相似的架构,但对多尺度量化层进行了修改。 在上采样
到 时使用了额外的卷积层来处理信息损失。
3 论文实验评估方法与效果
Power-law scaling laws
扩大自回归 (AR) 大语言模型 (LLM) 会导致测试损失 L 的可预测下降,因此可以根据较小模型的表现预测大模型的性能。
Zero-shot task generalization
4 论文局限性
- 对VQVAE架构进行改进
- 改进 VQVAE tokenizer
原文链接:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction