1 研究背景、动机、主要贡献
主要贡献
Transfusion方法的提出:通过将离散文本标记的预测和连续图像的扩散过程完全整合,Transfusion能够同时处理这两种模态,无信息损失。
多模态训练框架:论文展示了如何在一个统一的模型中,利用不同的目标函数(如文本的下一词预测和图像的扩散)进行训练,从而实现对两种模态的无缝生成。
模型架构的创新:引入了特定的编码和解码层,使得模型能够高效地处理和生成文本与图像,同时压缩图像到较小的表示。
优越的性能表现:实验表明,Transfusion在文本到图像和图像到文本生成任务中,超越了现有的方案,且在计算效率和生成质量上表现优秀。
Related Work
许多现有的多模态模型采用将多个模态特定的架构组合在一起的方式来处理不同的数据类型。这通常包括预训练各个模态的组件,然后将它们连接起来。例如,在图像和视频生成任务中,通常使用大型的预训练文本编码器(如Transformer架构)将输入文本表示为潜在空间中的向量,然后再通过这些表示去引导(condition)扩散模型进行生成。这类方法的特点是利用了多种现成的编码器来提升性能。
许多视觉-语言模型(Vision-Language Models)使用预训练语言模型作为主要结构,并通过投影层与其他模态特定的编码器/解码器相连接。代表性的模型包括:
- Flamingo(视觉理解)
- LLaVA(视觉理解)
- GILL(视觉生成模型)
- DreamLLM(用于视觉理解和生成)
Transfusion模型采用了一个统一的、端到端(end-to-end)的架构,可以同时处理文本和图像的理解与生成。
尽管最近的研究(如Li等人和Gat等人的工作)尝试将扩散模型推广到离散文本生成上,但其在生成质量和模型规模上仍然无法与标准的自回归语言模型相媲美。
2 论文提出的新方法
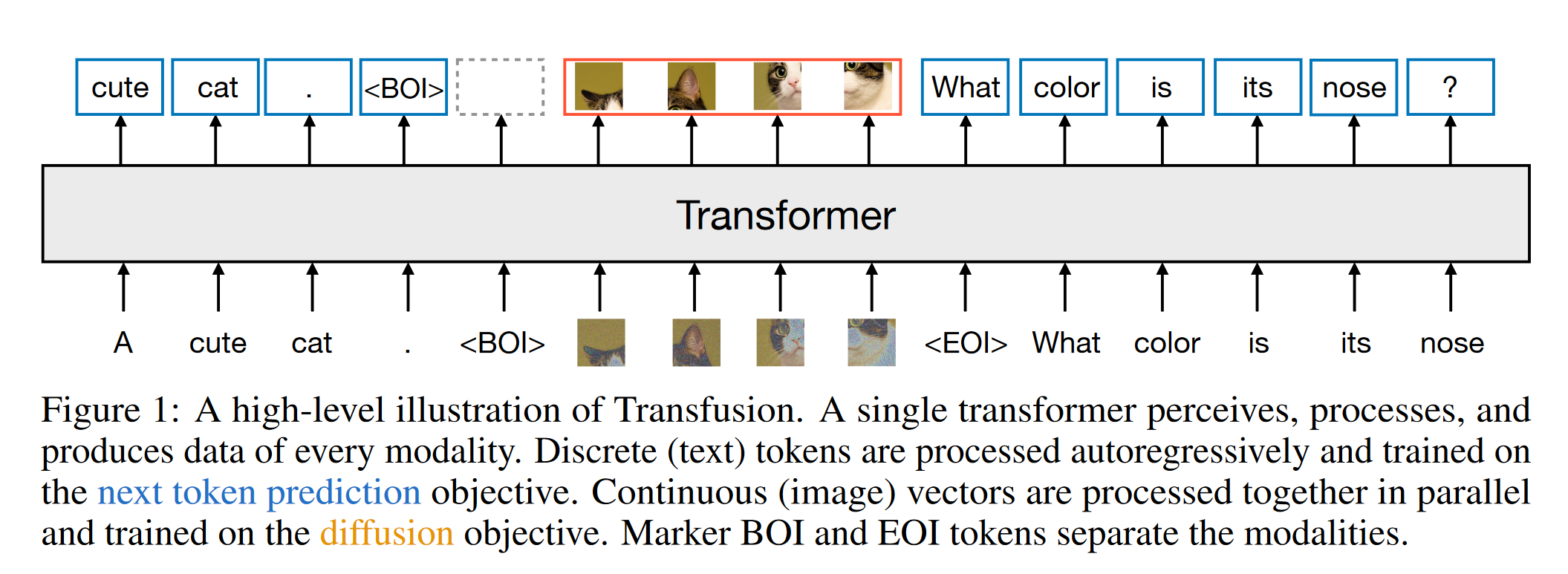
Transfusion 是一种训练单一统一模型以理解和生成离散和连续模态的方法。主要创新在于证明可以对不同模态使用单独的损失函数——对文本使用语言建模,对图像使用扩散——并在共享数据和参数上进行训练。
Data Representation
- 离散文本
- 每个文本字符串被分词成固定词汇表中的离散标记序列,每个标记被表示为一个整数。
- 连续图像。
- 每张图像通过 VAE 编码为 latent patches ,其中每个 patch 被表示为一个连续向量;补丁按从左到右、从上到下的顺序排列,形成一系列补丁向量。
- 对于混合模态示例,在每个图像序列的前后加上特殊的“图像开始”(BOI)和“图像结束”(EOI)标记,然后将其插入到文本序列中;因此,得到一个单一的序列,其中可能包含离散元素(表示文本标记的整数)和连续元素(表示图像补丁的向量)。
Model Architecture
大多数模型参数集中在一个单一的 transformer 上,该 transformer 处理每个序列,无论其模态如何。
transformer 接受高维向量的序列作为输入,并产生类似的向量作为输出。为了将数据转换为该空间,我们使用轻量级的模态特定组件,且不共享参数。
对于文本,这些是嵌入矩阵,将每个输入整数转换为向量空间,将每个输出向量转换为词汇表上的离散分布。
对于图像,我们实验了两种压缩局部窗口(k×k补丁向量)为单个变换器向量的替代方案(反之亦然): (1)简单的线性层 (2)U-Net的上下采样块。
Transfusion Attention
语言模型通常使用因果掩码,以便在一次前向和反向传播中有效计算整个序列的损失和梯度,而不泄漏未来标记的信息。
图像并不是自然顺序的;图像中的每个部分(像素或图像块)可以在没有特定顺序的情况下相互影响。通常使用无约束(双向)注意力进行建模。
Transfusion 通过对序列中的每个元素应用因果注意力,而在每个图像的元素内应用双向注意力,结合了这两种注意力模式。 这使得每个图像补丁可以关注同一图像内的其他补丁,但只能关注序列中先前出现的文本或其他图像的补丁。 启用图像内部的注意力显著提升了模型性能。

Training Objective
用于文本的预测。模型的目标是最大化文本序列中每个词的概率。损失是针对每个文本 token 计算的。 用于图像的预测。损失是针对每个图像计算的,可能跨越序列中的多个元素(图像补丁)。 - 生成一个被噪声污染的图像
后。在进行图像块划分之前计算图像级别的扩散损失。 - 损失函数
。 - 未来的工作可能会探讨更复杂的损失组合,例如用流匹配(flow matching)替代 diffusion 。
推理
解码算法在两种模式之间切换:LM和扩散。
- 在LM模式下,算法按照标准做法逐个从预测的分布中采样生成文本令牌(token)。当我们采样到BOI标记时,解码算法切换到扩散模式.
- 在扩散模式下,我们遵循扩散模型的标准解码过程。具体而言,我们将纯噪声
以n个图像补丁的形式附加到输入序列中,并在T个步骤中去噪。在每一步t,我们获取噪声预测,并利用它生成 ,这将覆盖序列中的 ;即模型始终依赖于噪声图像的最后时间步,并且不能关注之前的时间步。 扩散过程结束后,我们将EOI标记附加到预测的图像上,并切换回LM模式。
3 论文方法的理论分析或实验评估方法与效果
Setup
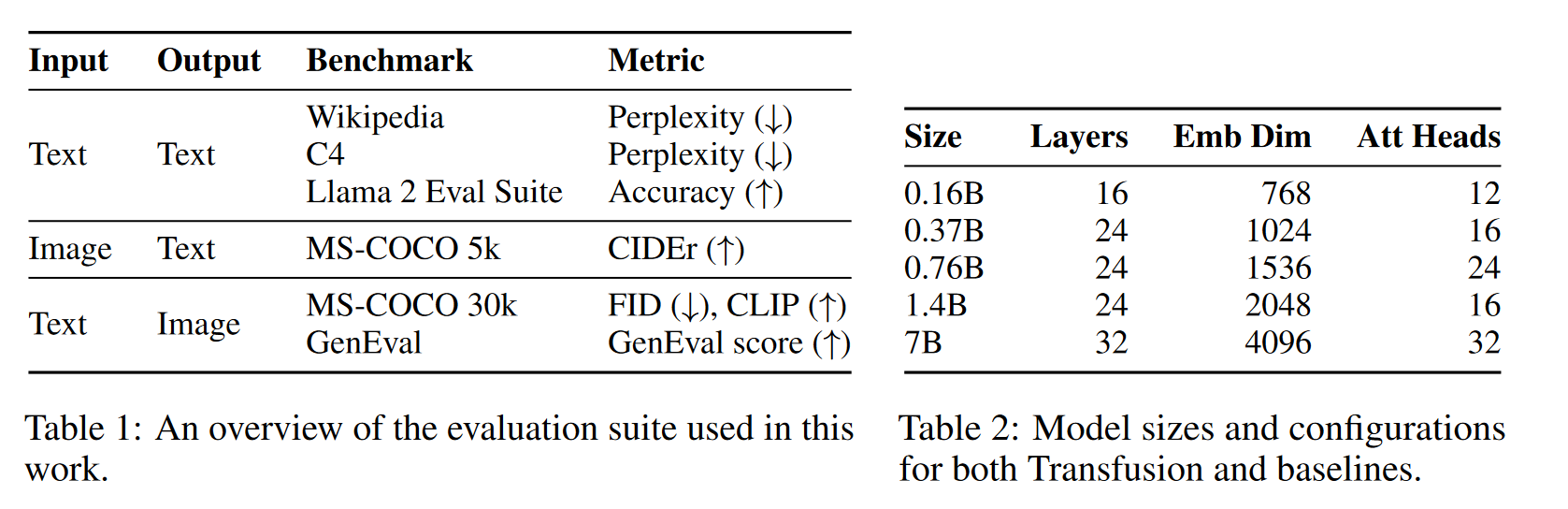
- AdamW优化器
- 随机初始化参数:所有模型参数都被随机初始化,这是一种常见的初始化方式,有助于避免模型陷入不理想的局部最小值。
- 它结合了Adam优化器的自适应学习率和L2正则化(权重衰减)。具体参数设置为:
- β1 = 0.9 和 β2 = 0.95:这两个参数控制一阶和二阶动量的指数衰减率,较高的值使得优化器能够更平滑地更新参数。
- ε = 1e-8:防止分母出现0值的常数。梯度的平方累积值接近 0 时,除以这些值可能导致数值不稳定。
- 学习率
- 学习率预热(warm-up):初始学习率设为0.0003,在训练的最初4000步中,学习率逐渐上升。有助于防止模型在初期更新时过快收敛到次优解。
- 余弦调度(cosine scheduler):学习率在训练的后期逐渐衰减至1.5e-5。平稳降低学习率,避免过度调整模型权重。
- 权重衰减防止过拟合
- 梯度裁剪防止梯度爆炸
Controlled Comparison with Chameleon
- 实验使用了模型大小(N)和token数量(D)作为对比的两个关键参数,以这两者的组合作为计算复杂度(FLOPs)的代理。
- 尽管Transfusion和Chameleon在文本建模中使用相同的方式,Transfusion依然在文本任务上表现更好。
- 一种假设是,这源于输出分布中文本和图像标记之间的竞争
- 或者,扩散可能在图像生成方面更有效并且需要更少的参数,从而允许 Transfusion 模型使用比 Chameleon 更多的容量来建模文本。
Architecture Ablations
- U-Net层带来的归纳偏置可能是其表现比简单的线性层好的原因。即便在较小的模型中加入这些归纳偏置,也能够提升模型在图像生成和描述任务上的表现。
- 通过调整扩散噪声的水平,图像描述任务中的性能有所改善。
- Transfusion模型不仅能处理文本和图像,还能执行图像编辑任务。
原文链接:Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model