1. 研究背景、动机、主要贡献(Why)
1.1 研究背景
- 医疗问答方面
- 系统能相应各种问题格式
- 是/否
- 多选
- 提取
- 生成
- 对医学查询生成流畅且有意义的响应(预训练语言模型的引入)
- 系统能相应各种问题格式
- 大语言模型在生成式问答中展现出前景。
1.2 存在问题(动机)
- “幻觉”问题,即模型生成听起来合理但不忠实或无意义的信息
- 在医疗领域
- 幻觉信息可能会对患者护理产生严重后果
- 不常见的专业概念使医学 GQA 任务变得复杂
- 目前对LLMs产生的医学答案中幻觉程度的理解仍不明朗
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法
它的目标是在保持 MQA 速度的同时实现 MHA 的质量。
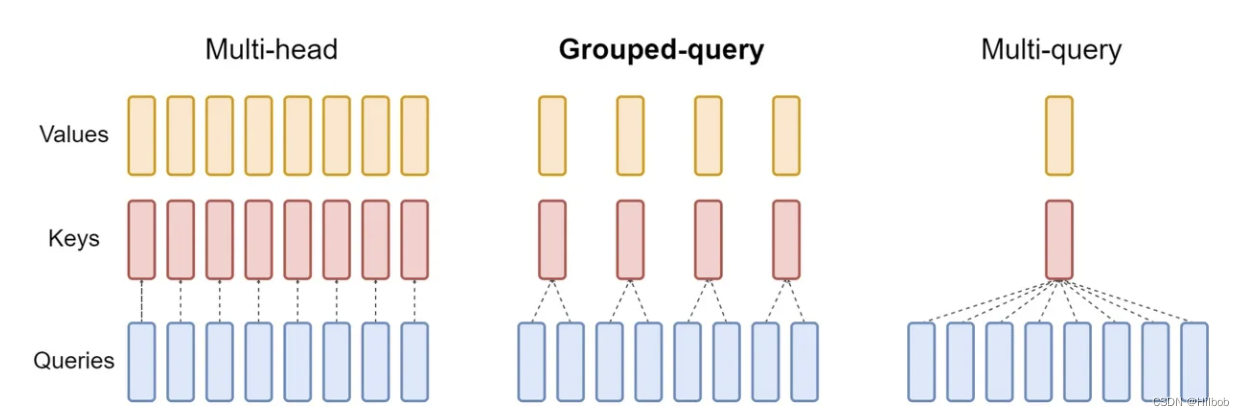
1.2.1 现有方案
| 名称 | 会议名称 | 年份 | 方法 |
|---|---|---|---|
| Addressing Semantic Drift in Generative Question Answering with Auxiliary Extraction 使用辅助提取解决生成问答中的语义漂移 |
ACL-IJCNLP 2021 | 2021 | 在编码器上添加一个提取任务,以获得答案的基本原理,根据提取的基本原理和原始输入,解码器预计会生成高置信度的答案。 |
| Read before Generate! Faithful Long Form Question Answering with Machine Reading 在生成之前阅读!通过机器阅读进行忠实的长篇问答 |
ACL | 2022 | 首先使用检索器从大型外部知识源中搜索相关信息。然后阅读器和生成模块将多个检索到的文档与问题一起作为输入来生成答案。 具体来说,阅读器模块采用机器阅读理解(MRC)模型为每个文档中的每个句子生成证据分数,而生成器采用大型预训练的Seq2Seq语言模型,将句子证据分数融合到其生成过程中。 |
Seq2Seq(Sequence to Sequence),即序列到序列模型,就是一种能够根据给定的序列,通过特定的生成方法生成另一个序列的方法,同时这两个序列可以不等长。这种结构又叫Encoder-Decoder模型,即编码-解码模型,其是RNN的一个变种,为了解决RNN要求序列等长的问题。
1.3 主要贡献
- 对医学 GQA 系统中的幻觉现象进行了全面检查。特别是在五个医学 GQA 数据集中应用五个LLMs。
- 提出了一种交互式自我反思方法,迭代生成答案,直到达到令人满意的水平。
- 实验结果展示了LLMs无需对特定数据集进行明确培训即可提供有意义的见解的能力。
2. 幻觉分析
2.1 模型
- Vicuna
- 通过在 ShareGPT 的用户共享对话上微调 LLaMA 进行训练
- AlpacaLoRA
- 采用低秩适应(LoRA)来复制斯坦福大学 Alpaca 模型的结果
- ChatGPT
- 使用人类反馈强化学习(RLHF)来解释提示并提供全面的响应
- MedAlpaca
- 建立在 LLaMA 框架之上,并在指令调整格式的医学对话和 QA 文本上进行了微调
- Robin-medical
- 使用 LMFlow 在医疗领域微调的 LLaMA
2.2 数据集
- PubMedQA
- 1k 个专家标记的实例
- 问题来自研究文章的标题
- 内容来自摘要
- 长回答来自摘要结论
- 简洁的yes/no/maybe答案
- 1k 个专家标记的实例
- MedQuAD
- 包含来自美国国立卫生研究院网站的 47,457 个 QA 对
- MEDIQA2019
- 将挑战赛中得分3和4的答案视为黄金答案
- LiveMedQA2017
- MASH-QA
- 包括来自消费者健康领域的 34k QA 对
2.3 结果与讨论
问题分类(本文认为前两个是幻觉问题。)
- 事实不一致
- 模型回答问题时未能正确回忆相关知识
- 查询不一致
- 既没有回答问题也没有适当地调用相关知识
- 离题
- 提供与主题相关的信息但不直接解决问题的答案。
- 模型没有进一步处理掌握的知识(例如归纳、演绎和逻辑推理)
应对这些挑战需要模型能够回忆事实知识、情境理解和推理能力

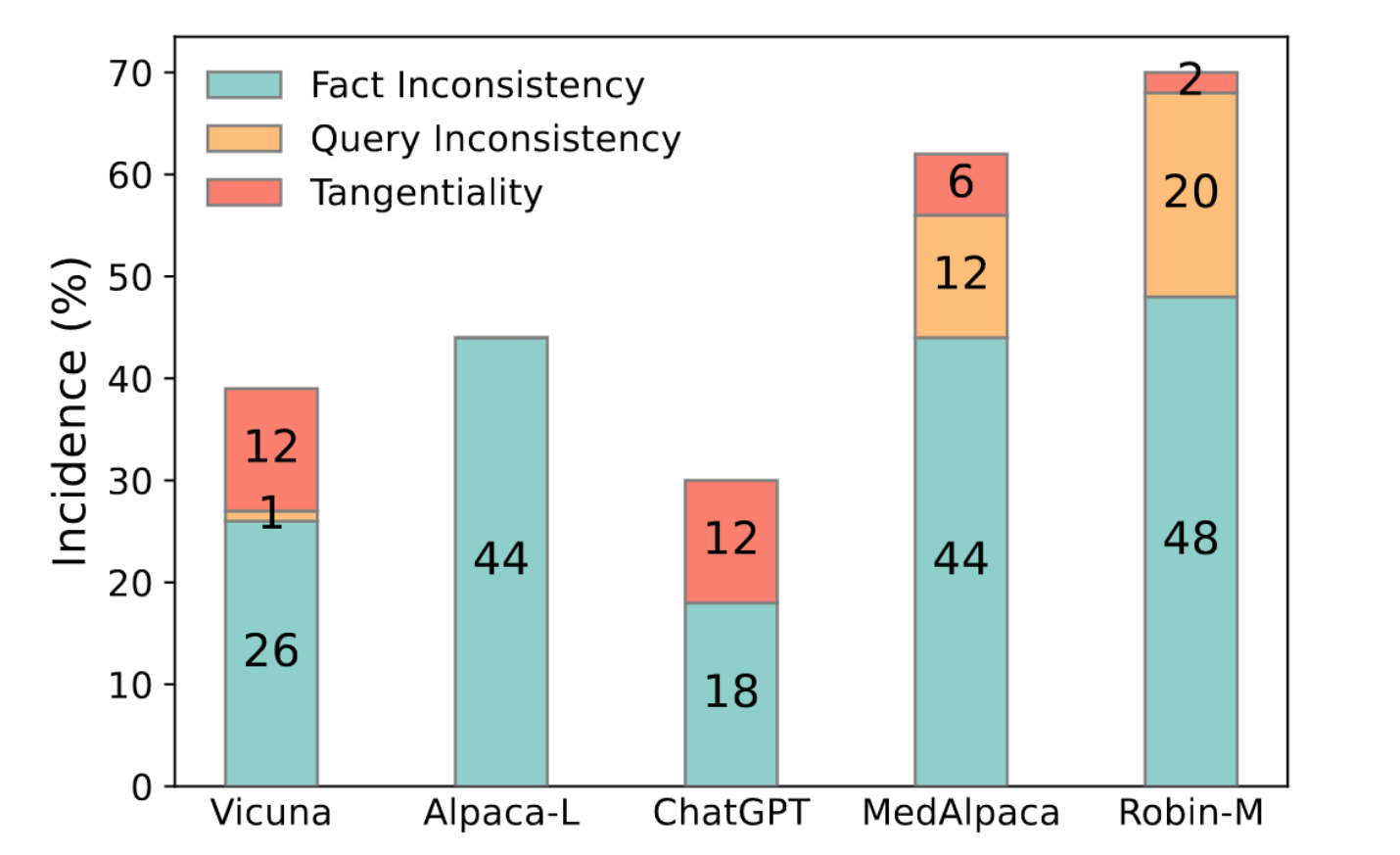
微调对医学领域的影响
[!note]+ why
MedAplpaca 和 Robin-medical 之间的差异表明,指令学习比非指令调整更适合LLMs。
频率的测量
- 随机选择通用模型生成的 100 个样本
- 确定问题的关键词或主题,通常是疾病名称
- 采用 1950-2019 年之间这些关键词的平均频率。(数据来源是Google Ngram Viewer,将其作为自然世界中文本分布和预训练语料库的代理)
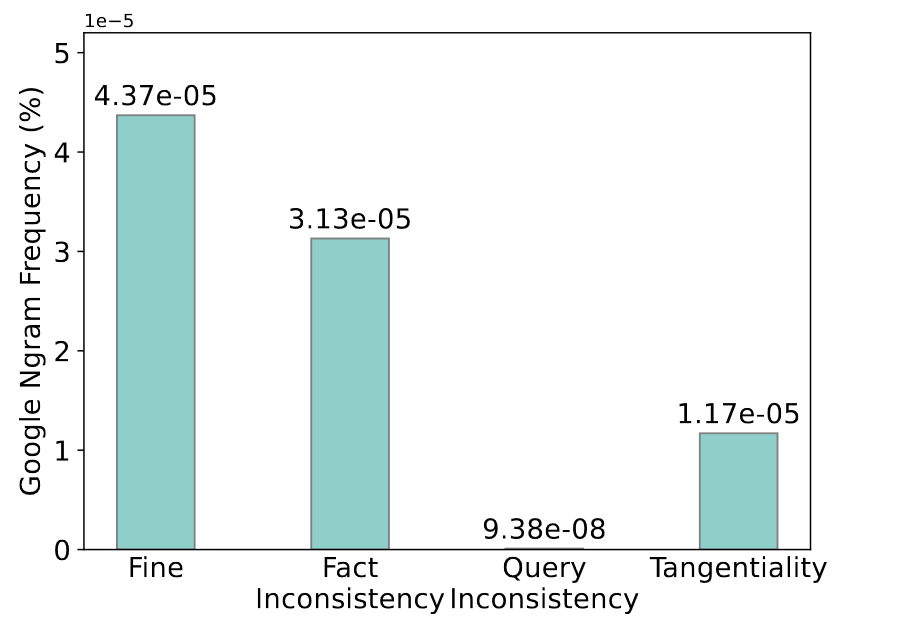
对于有问题的回答,其关键词的平均频率低于好的回答。低频可能是产生幻觉的潜在原因
3. 缓解幻觉的方法(What)
- 提出了一个迭代的自我反思过程,该过程利用LLMs生成和完善响应的能力
- 方法包括三个循环
- 事实知识获取循环
- 知识一致回答循环
- 问题蕴涵回答循环
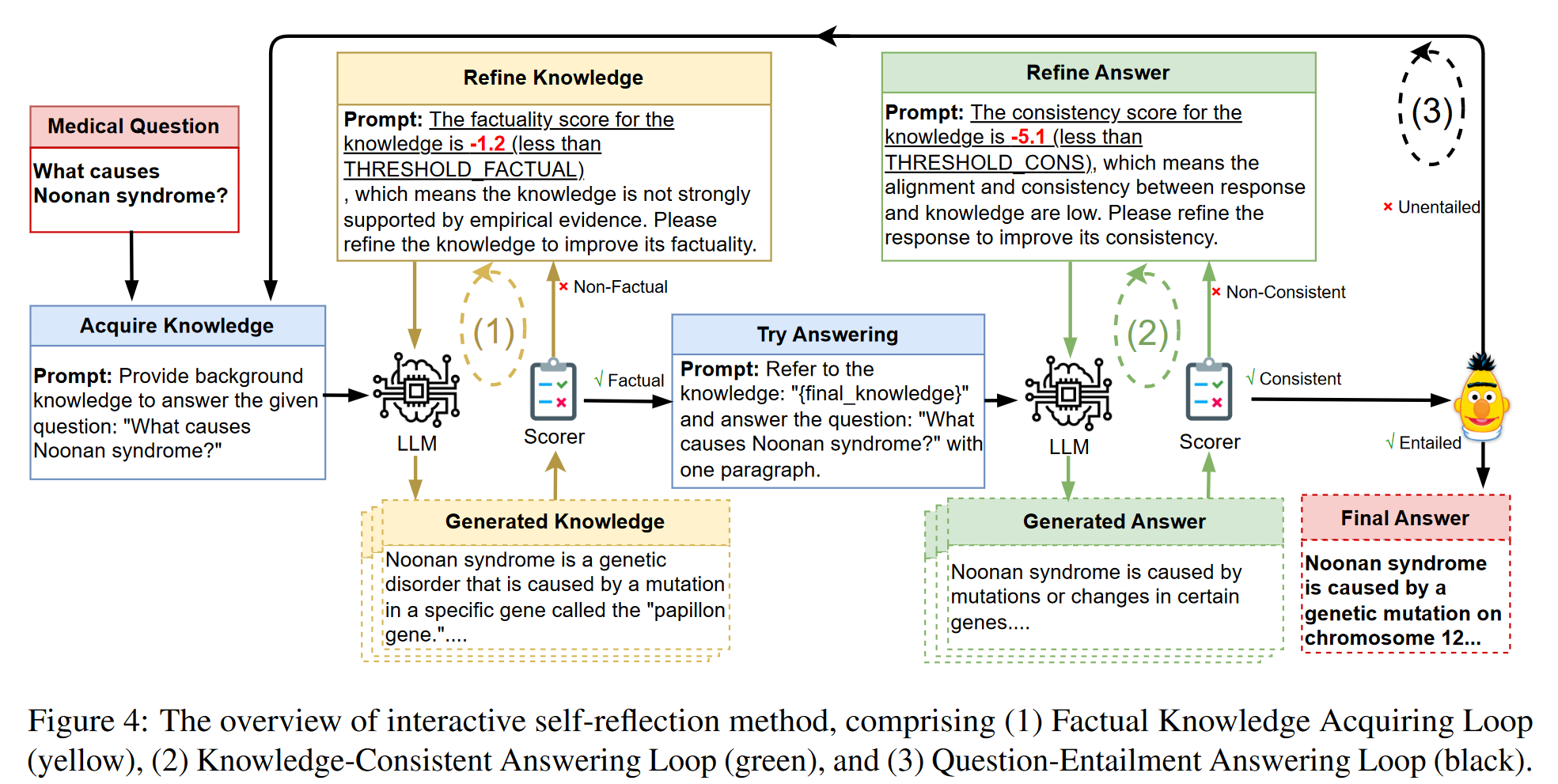
3.1 事实知识获取循环
- 模型基于所提供的问题生成背景知识
- 使用定制的无参考评分器对生成的知识进行事实性评估
待评估的知识为k = {k1, k2, …, km}。 D 是带注释示例的小样本演示,Q 是给定的问题。 T(·)是提示模板,包括事实性的定义和任务描述:“根据问题,请生成事实性知识。为此,请考虑以下因素:可验证性、客观性和来源的可靠性。请注意,此评估应基于现有的最佳医学知识。\n\n问题:…\n知识:…”
- 如果事实性得分低于评估阶段设定的阈值,指示模型自我反思并精炼知识,并提示:“The factuality score for the knowledge is XXX (less than THRESHOLD_FACTUAL), which means the knowledge is not strongly supported by empirical evidence. Please refine the knowledge to improve its factuality.”(“该知识的事实性得分为 XXX(低于 THRESHOLD_FACTUAL),这意味着该知识没有得到经验证据的有力支持。请完善知识以提高其真实性。”)
- 这种生成-评分-优化策略会交互重复,直到生成的知识达到令人满意的事实水平。
3.2 知识一致的应答循环
- 模型会根据所提供的问题和最终知识,使用模板生成答案:“Refer to the knowledge: “final_knowledge” and answer the question: XXX with one paragraph.”(“参考知识:“final_knowledge”并用一段话回答问题:XXX。”)
- 使用CTRLEval 对生成的答案进行一致性评估
- 如果生成的答案的一致性得分降低了阈值,则提示模型进行内省、自我更正,并用 “The consistency score for the knowledge is XXX (less than THRESHOLD_CONS), which means the alignment and consistency between response and knowledge are low. Please refine the response to improve its consistency.”(“知识的一致性得分为 XXX(低于 THRESHOLD_CONS),这意味着响应和知识之间的一致性和一致性较低。请完善回复以提高其一致性。”)
- 重复这种生成-评分-优化策略,直到生成的答案达到一致性级别。
3.3 问题-蕴涵回答循环
- 通过Sentence-BERT嵌入相似性来评估生成的答案的蕴涵
- SBERT 在孪生/三元组网络架构中对 BERT 进行了微调。在质量和性能上都有提高。
- 如果生成的答案不满足满意的蕴含水平,则过程返回到框架的初始阶段,并且重复整个循环,迭代上述阶段。
4. 论文方法的理论分析或实验评估方法与效果(How)
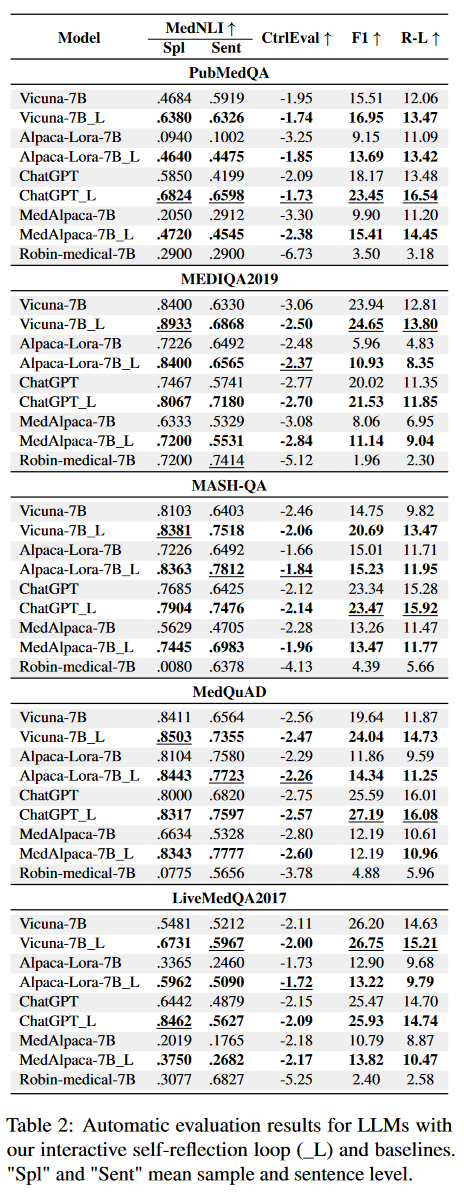
4.1 自动评估
- 指标:
- F1(词语级别)
- ROUGE-L(需要考虑顺序)
广泛使用的 n-gram 相似性度量通常无法区分幻觉/不正确的答案,并且与人类判断的相关性较弱
- 进一步引入 Med-NLI(医学自然语言推理)来评估生成的答案与所提供的上下文或参考答案的逻辑一致性/内涵。
- SciFive。一种在广泛的生物医学语料库上预训练的 T5 模型。
- 评估发生的级别
- 样本级别。评估生成的答案是否细节 (1)、中性 (0) 或与上下文或参考答案相矛盾 (-1)。
- 句子级别。除了评估生成的答案是否细节 (1)、中性 (0) 或与上下文或参考答案相矛盾 (-1) 外,还采用了CTRLEval 指标的一致性方面。
LCS(X,Y)是X和Y的最长公共子列的长度。m,n分别表示参考摘要(人工摘要)和候选摘要(机器生成的摘要)的长度
样本级别(Sample Level)评估可以提供对模型整体生成能力的宏观了解。
句子级别(Sentence Level)评估通常使用一些句子级别的度量标准来评估生成结果的准确性和流畅性[!NOTE]+ CTRLEval的一致性:
[!note]+ 在CTRLEval: An Unsupervised Reference-Free Metric for Evaluating Controlled Text Generation一文中,提到了CTRLEval的多个特性(Coherence,Consistency,Attribute Relevance),为何此处只使用一致性?
4.2 人工评估
- 指标
- 除了自动指标外,还使用 Amazon Mechanical Turk 进行人工评估
- 样本级别
- Query-Inconsistent(查询不一致):答案提供与查询无关的信息或者是无意义且无意义的。
- Tangential(离题):答案提供了与问题相关的信息,但不直接解决问题。
- Entailed(蕴含)答案直接解决了问题
- 句子级别
- Fact-Inconsistent(事实不一致):答案无法通过参考验证或与参考矛盾
- Fact-Consistent(事实一致):答案句子得到给定上下文或网站的支持
- Generic(通用):答案中的句子没有可供判断的陈述
“That’s an interesting question”,”There are some advice”
- 样本级别
- 除了自动指标外,还使用 Amazon Mechanical Turk 进行人工评估
4.3 结果
- 自动评估
- MedNLI 显着增加
- F1 和 Rouge-L 分数的提升有时相对较小
- 主要是由于这些指标对黄金答案准确性的固有依赖
- 方法在所有五个数据集上展示了其在不同的语言模型中的有效性
- 人工评估
- 降低了 Vicuna 和 ChatGPT 中查询不一致、离题和事实不一致的百分比
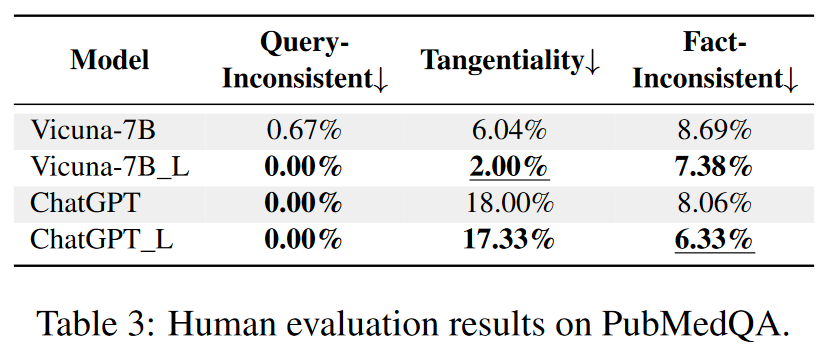
- 降低了 Vicuna 和 ChatGPT 中查询不一致、离题和事实不一致的百分比
4.4 消融实验
改进(Refinement)的影响
省略了评分和改进阶段,只进行生成阶段。
方面描述的影响
省略了提及需要细化的具体方面。通过使用更通用的指令来指示模型进行自我反思:“请完善知识/响应。”
分数的影响
省略了提供准确值。相反,只在说明中描述需要改进的方面:“该知识没有得到经验证据的有力支持。请完善知识以提高其真实性。” “反应和知识之间的一致性和一致性很低。请完善回复以提高其一致性。”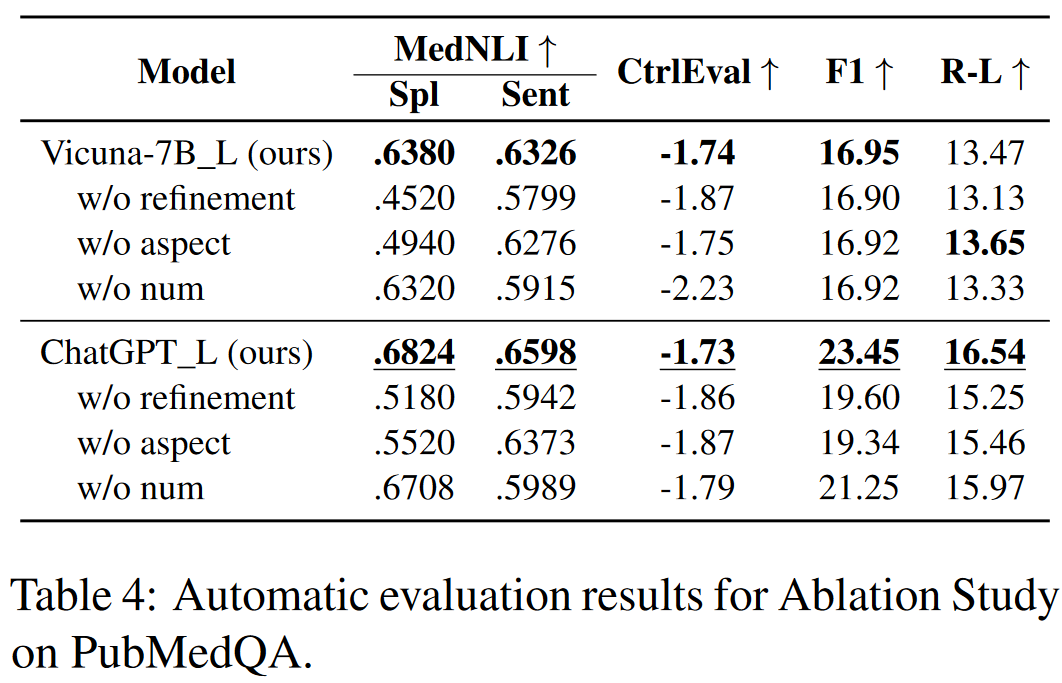
案例研究
证明了方法在解决事实和查询不一致方面的有效性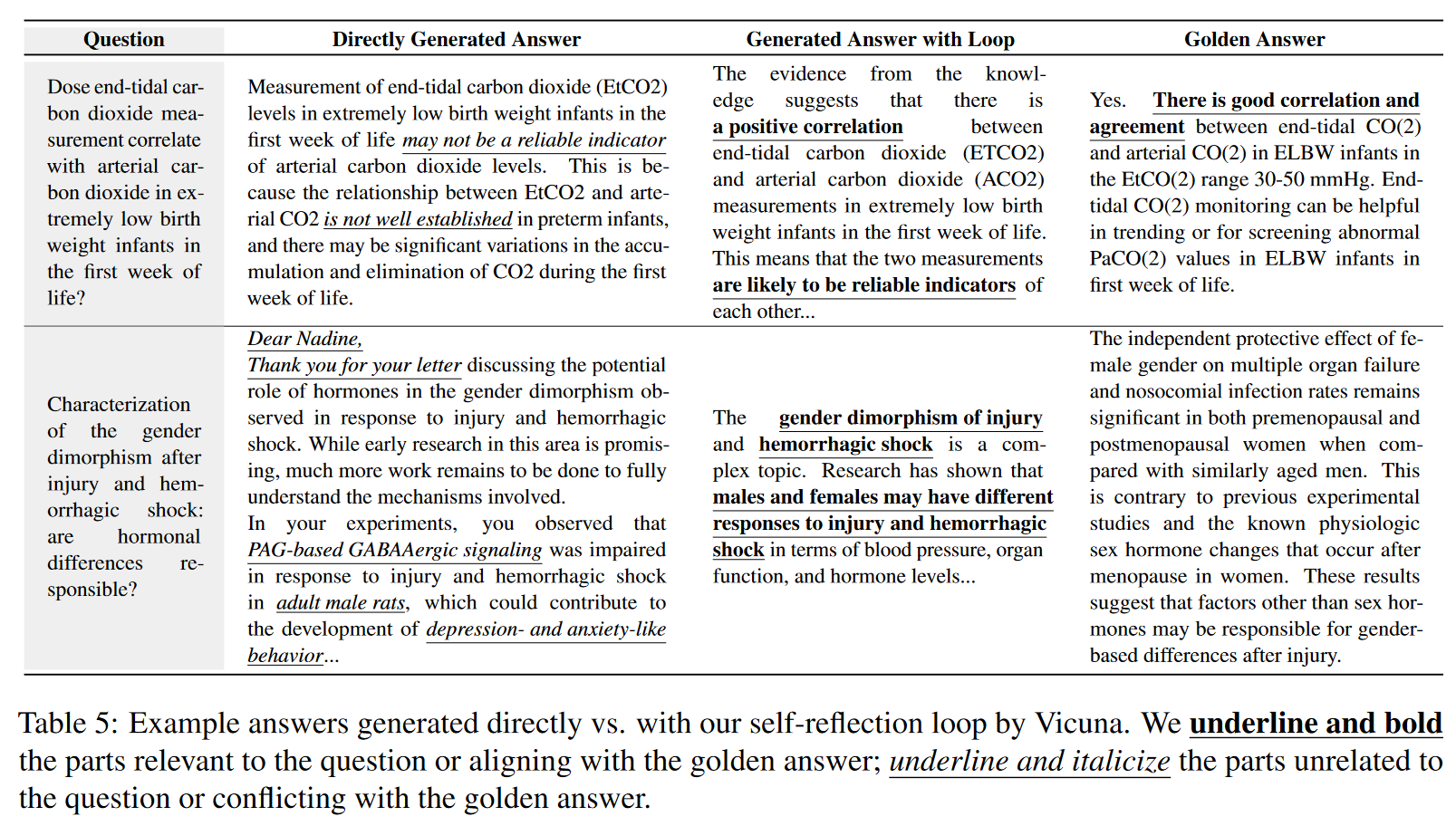
5. 论文优缺点、局限性、借鉴性
优点:
- 提出了一种缓解幻觉的方法,且方法在不同数据集和不同大模型之间均验证了有效性。
缺点:
- “我们的方法在所有五个数据集上展示了其在具有不同参数(包括 7B 和 175B)的语言模型中的有效性”,并未提及175B相关数据。
- 某些结论推导不严谨
- MedAlpaca (Han et al., 2023) is built upon the frameworks of LLaMA and fine-tuned on instruction-tuning formatted medical dialogue and QA texts.
- Robin-medical (Diao et al., 2023) is fine-tuned LLaMA in the medical domain using LMFlow.
- MedAplpaca 和 Robin-medical 之间的差异表明,在我们的任务中,指令学习比非指令调整更适合法学硕士。
- 迭代可能造成性能糟糕(TTL?)