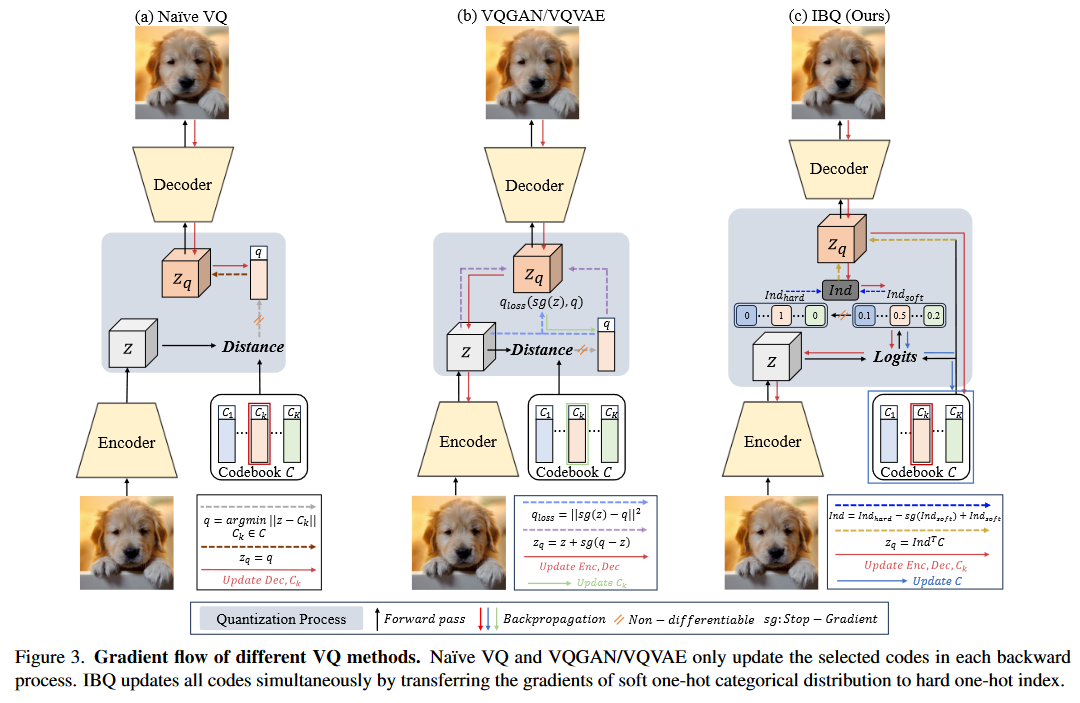
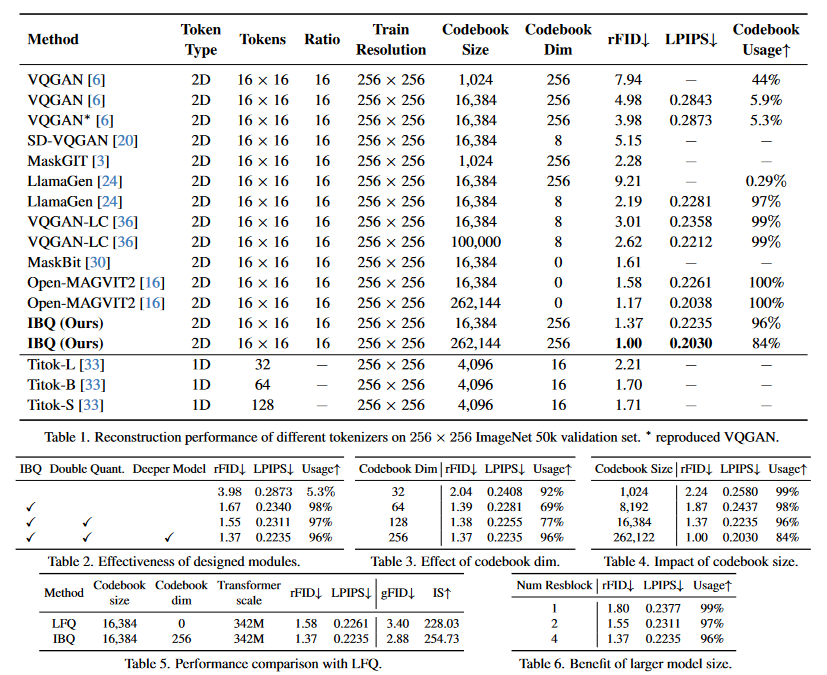
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| def forward(self, z, temp=None, return_logits=False):
# z: [b, d, h, w]
# embed.weight: [n, d]
logits = einsum('b d h w, n d -> b n h w', z, self.embedding.weight)
soft_one_hot = F.softmax(logits, dim=1)
dim = 1
ind = soft_one_hot.max(dim, keepdim=True)[1]
hard_one_hot = torch.zeros_like(logits, memory_format=torch.legacy_contiguous_format).scatter_(dim, ind, 1.0)
one_hot = hard_one_hot - soft_one_hot.detach() + soft_one_hot
z_q = einsum('b n h w, n d -> b d h w', one_hot, self.embedding.weight)
z_q_2 = einsum('b n h w, n d -> b d h w', hard_one_hot, self.embedding.weight)
quant_loss = torch.mean((z_q - z)**2) + torch.mean((z_q_2.detach()-z)**2) + self.beta * \
torch.mean((z_q_2 - z.detach()) ** 2)
diff = quant_loss
if self.use_entropy_loss:
sample_entropy, avg_entropy, entropy_loss= compute_entropy_loss(logits=logits.permute(0, 2, 3, 1).reshape(-1, self.n_e), temperature=self.entropy_temperature, sample_minimization_weight=self.sample_minimization_weight, batch_maximization_weight=self.batch_maximization_weight) # logits [b d h w] -> [b * h * w, n]
diff = (quant_loss, sample_entropy, avg_entropy, entropy_loss)
ind = torch.flatten(ind)
return z_q, diff, (None, None, ind)
|