- 1 研究背景、动机、主要贡献
- 2 论文提出的新方法
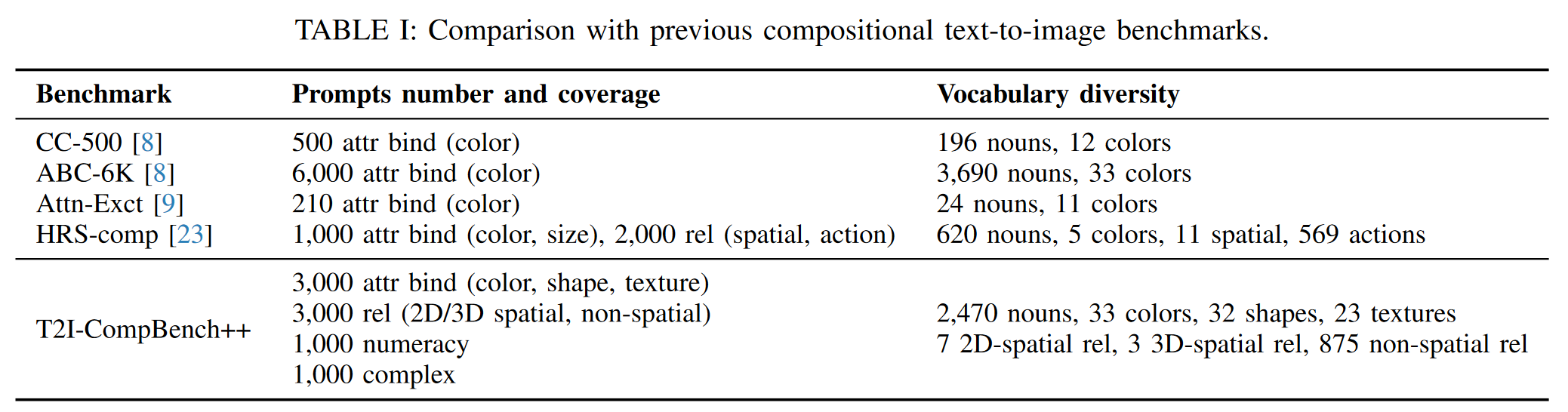
- 2.2 T2I-COMPBENCH++
- 2.2 EVALUATION METRICS
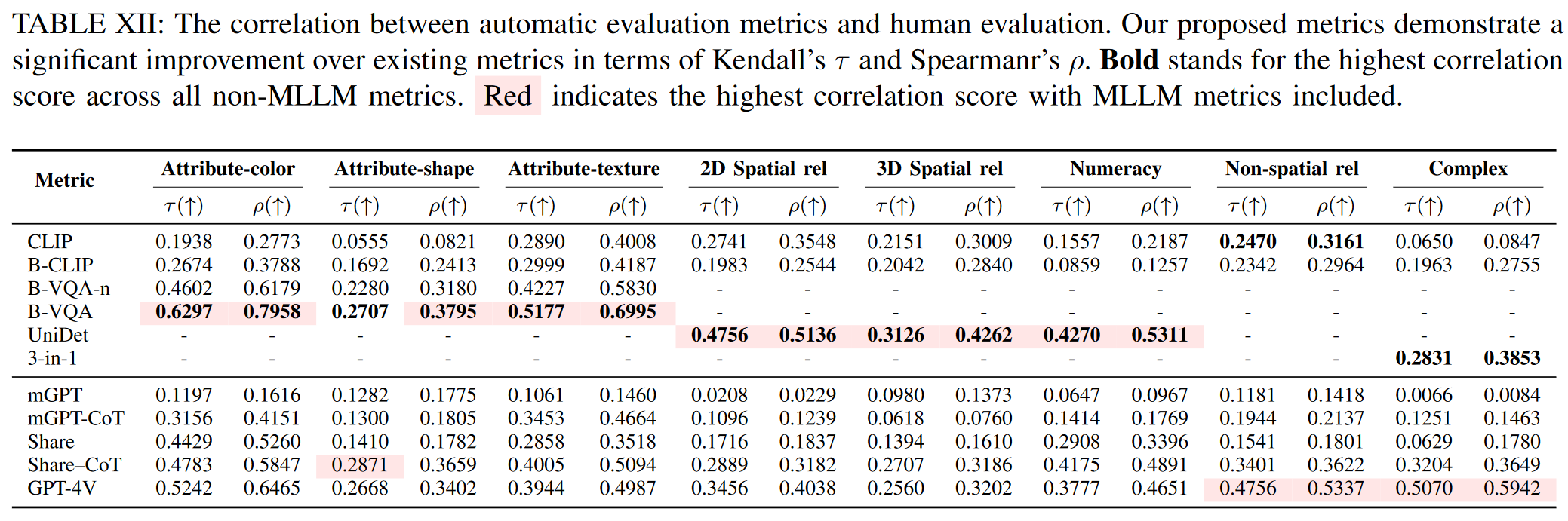
- 3 论文实验评估方法与效果
1 研究背景、动机、主要贡献
1.1 研究背景
文本到图像生成领域的最新进展展示了基于自然语言提示创建多样化和高保真图像的卓越能力。然而,即使是最先进的文本到图像模型也常常无法将具有不同属性和关系的多个对象组合成一个复杂且连贯的场景。

1.2 存在问题(动机)
现有研究主要从概念结合、属性绑定和空间关系等单一角度探索这一领域,但缺乏全面的基准和统一的评估标准。
对于 t2i 模型,当前主要评估方法包括图像-文本相似性(CLIPScore)和文本-文本相似性(BLIP)。然而,由于组合视觉语言理解的模糊性和困难,这两个指标对于组合性评估都表现不佳。
HRS-Bench 是一个通用基准测试,可通过 45,000 个提示评估 13 项技能。组合能力只是 13 项评估技能之一,尚未得到广泛研究。本文提出了第一个开放世界合成文本到图像生成的综合基准。
1.3 主要贡献
- 扩大了组合文本到图像生成的问题定义和类别。BenchMark更全面。
- 引入更多的评估指标并深入讨论 MLLM 作为评估指标。
- 更全面的基准测试和分析。
2 论文提出的新方法
2.2 T2I-COMPBENCH++
- 为了提供问题的清晰定义并建立基准,根据不同的组合任务将其划分为四大类和八个子类。
- 属性绑定(Attribute Binding)
- 颜色
- 形状
- 纹理
- 物体关系(Object Relationships)
- 二维空间关系
- 三维空间关系
- 非空间关系
- 数字生成(Generative Numeracy)
- 复杂组合(Complex Compositions):包括两个或以上的物体具有多个属性/混合属性的任务。
- 属性绑定(Attribute Binding)
- 为了更好地评估模型的泛化能力,部分提示通过 ChatGPT 生成,并故意包括一些不符合物理规律的场景。
2.2 EVALUATION METRICS
- 属性绑定(Attribute Binding)
- 颜色
- 形状
- 纹理
- 物体关系(Object Relationships)
- 二维空间关系
- 三维空间关系
- 非空间关系
- 数字生成(Generative Numeracy)
- 复杂组合(Complex Compositions)
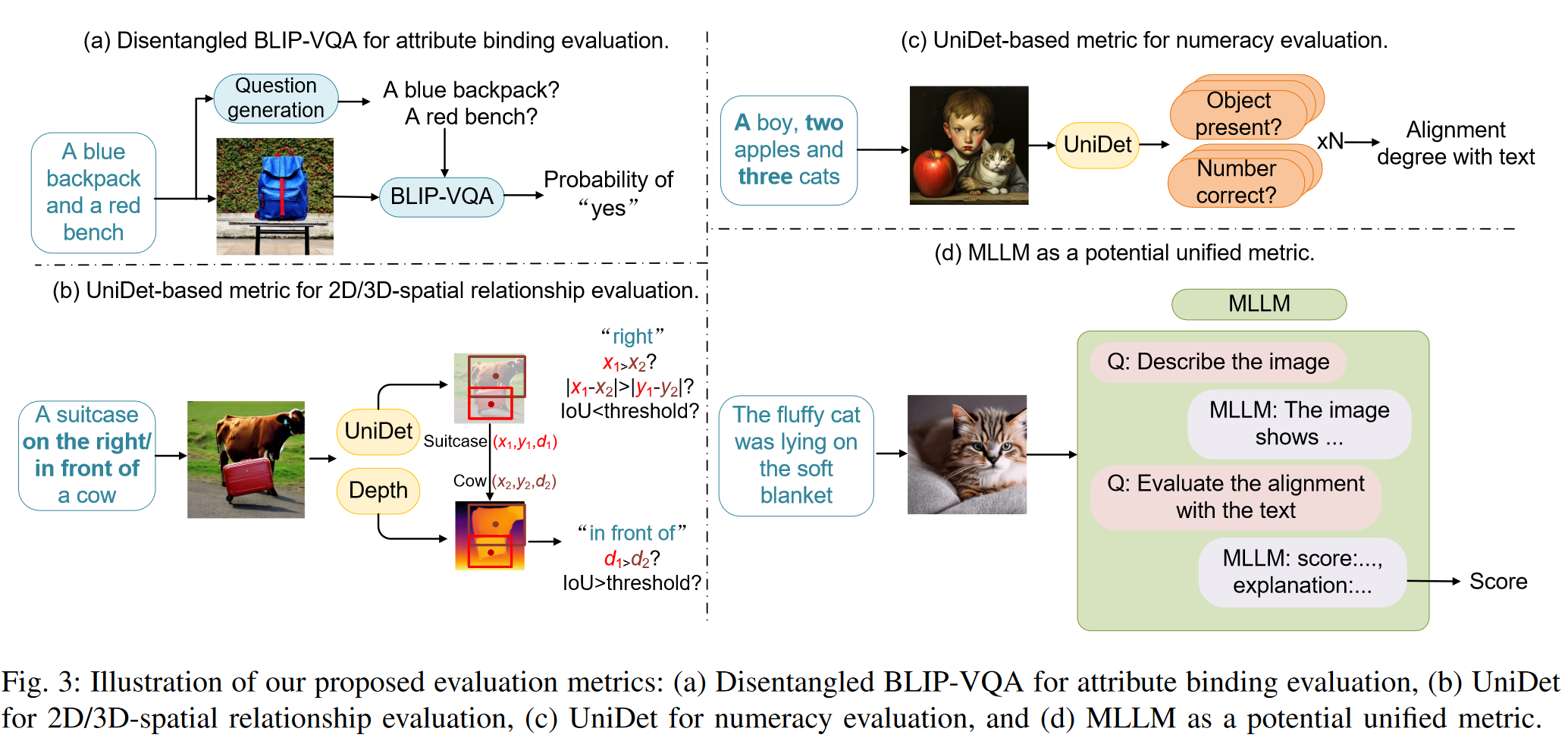
2.2.1 Disentangled BLIP-VQA for Attribute Binding Evaluation
BLIP-CLIP 评估的主要限制在于 BLIP captioning models 并不总是描述每个对象的详细属性。
- BLIP 字幕模型可能会将图像描述为
A room with a table, a chair, and curtains。 - 生成此图像的文本提示是
A room with yellow curtains and a blue chair。
明确比较文本之间的相似性可能会造成歧义和混淆。
利用 BLIP 的视觉问答 (VQA) 功能来评估属性绑定。
例如,给定使用文本提示 a green bench and a red car
生成的图像,我们分别提出两个问题:“a green bench?”和“a red car?”。通过将复杂的文本提示分解为两个独立的问题,每个问题只包含一个对象-属性对,避免了
BLIP-VQA 的混淆。 BLIP-VQA
模型将生成的图像和几个问题作为输入,将回答“yes”的概率作为问题的分数。我们通过将每个问题回答“yes”的概率相乘来计算总分。
解耦 BLIP-VQA 用于评估颜色、形状和纹理的属性绑定。
2.2.2 UniDet-based Metric for Spatial Relationships and Numeracy Evaluation
2D-spatial relationships.
首先使用 UniDet 检测生成的图像中的物体。然后,通过比较两个边界框中心的相对位置 + 两个边界框之间的交并比 (IoU) 来确定两个物体之间的空间关系。
Denote the center of the two objects as (x1, y1) and (x2, y2), respectively. The first object is on the left of the second object if x1 < x2, |x1 − x2| > |y1 −y2|, and the intersection-over-union (IoU) between the two bounding boxes is below the threshold of 0.1. Other spatial relationships “right”, “top”, and “bottom” are evaluated similarly.
通过将两个物体中心之间的距离与阈值进行比较来评估 “next to”, “near”, and “on the side of”。
3D-spatial relationships.
利用深度估计结合基于检测的度量。让 d1 和 d2 表示对应于两个物体的深度图的平均值。具体而言,如果 d1 > d2 且 IoU 度量超过预定阈值 0.5,则推断第一个物体位于第二个物体的前面。其他 3D 空间关系“后面”、“隐藏”的评估方式类似。
Numeracy
首先从提示中提取物体的名称及其相应的数量。利用 UniDet 检测图像中的物体。 n 表示给定提示中引用的不同对象类别的数量。
- 对象识别正确,得 1/(2n) 分。
- 此外,生成的数量与指定类别准确匹配,则再得 1/(2n) 分。
2.2.3 3-in-1 Metric for Complex Compositions Evaluation
解耦 BLIP-VQA 最适合属性绑定评估,基于 UniDet 的指标最适合 2D/3D 空间关系和计算能力评估,而 CLIPScore 最适合非空间关系评估。因此,计算 CLIPScore、Disentangled BLIP-VQA 和 UniDet 的平均分,作为复杂组合的评估指标。
2.2.4 MLLM-based Evaluation Metric
本文分析了三种类型的 MLLM 的能力,即 MiniGPT-4、ShareGPT4V 和 GPT-4V ,重点关注它们在组合问题中的表现。
Evaluation methods of MLLMs.
通过将预训练的视觉编码器与冻结的大型语言模型对齐,多模态大型语言模型(如 MiniGPT-4)已表现出强大的视觉-语言跨模态理解能力。
将生成的图像提交给模型,并评估它们与提供的文本提示的对齐情况。此评估涉及征求对图文对齐分数的预测。
Prompt template for MLLM evaluation.
- 属性绑定(Attribute Binding)
- 颜色
- 形状
- 纹理
- 物体关系(Object Relationships)
- 二维空间关系
- 三维空间关系
- 非空间关系
- 数字生成(Generative Numeracy)
- 复杂组合(Complex Compositions)
利用 MLLM 作为评估指标,将生成的图像输入模型,并使用 Chain-ofThought 提出两个问题:
- “
describe the image” - “
predict the image text alignment score”。
对于 5 个子类别,按顺序提出上面两个问题。
对于 GPT-4V ,省略describe the image的提示。


对于没有 Chain-of-Thought 的 MLLM ,使用预定义的提示。
- 对于属性绑定,使用提示模板,“
Is there {object} in the image? Give a score from 0 to 100. If {object} is not present or if {object} is not {color/shape/texture description}, give a lower score.” ,对文本中的每个名词短语都使用这个问题并计算平均分数。 - 对于空间关系、非空间关系和复杂构图,我们使用更通用的提示模板,例如“
Rate the overall alignment between the image and the text prompt {prompt}. Give a score from 0 to 100.”。
2.2.5 BOOSTING COMPOSITIONAL TEXT-TO-IMAGE GENERATION WITH GORS
Generative mOdel finetuning with Reward-driven Sample selection (GORS)
通过奖励驱动的样本选择进行生成模型微调。
具体来说,给定文本到图像模型
3 论文实验评估方法与效果

原文链接:T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to-image Generation