1. 研究背景、动机、主要贡献
传统的扩散模型大多采用U-Net作为主干网络,LDM ( High-Resolution Image Synthesis with Latent Diffusion Models ) 也只是通过交叉注意力机制增强其底层 UNet 主干网 ,而本文提出的DiT模型替代了U-Net,是使用Transformer来操作图像的潜在表示。
2. 论文提出的新方法
Preliminaries
- Diffusion formulation.
- Classifier-free guidance.
- 条件扩散模型
- 反向扩散过程变为:
- 反向扩散过程变为:
- 无分类器引导的目标
- 无分类器引导的主要目的是提升生成结果,使得模型能够生成与给定类别c相关的样本,同时避免直接依赖外部分类器。通过这种引导方式,采样过程会倾向于生成那些与条件信息(类别标签c)高度匹配的样本。
- 采样过程中的引导
- 可以利用
的梯度来引导模型朝着更符合类别条件 c 的方向生成图像。扩散模型的输出可以被解释为一个得分函数,通过调整生成图像的梯度,来优化生成样本的类别匹配度。 - s>1是引导的强度参数,当 s=1时,恢复为标准的采样过程;当 s>1时,引导力度加强,生成图像更倾向于符合类别条件c。
- 为了避免对外部分类器的依赖,模型会在训练过程中随机丢弃条件 c
,用一个学到的“空”嵌入符号"null"
替代。这种方法通过让模型在有和没有条件的情况下都进行学习,从而在测试时能够灵活地处理带条件和不带条件的情况。
- 可以利用
- 条件扩散模型
- Latent diffusion models.
Diffusion Transformer Design Space
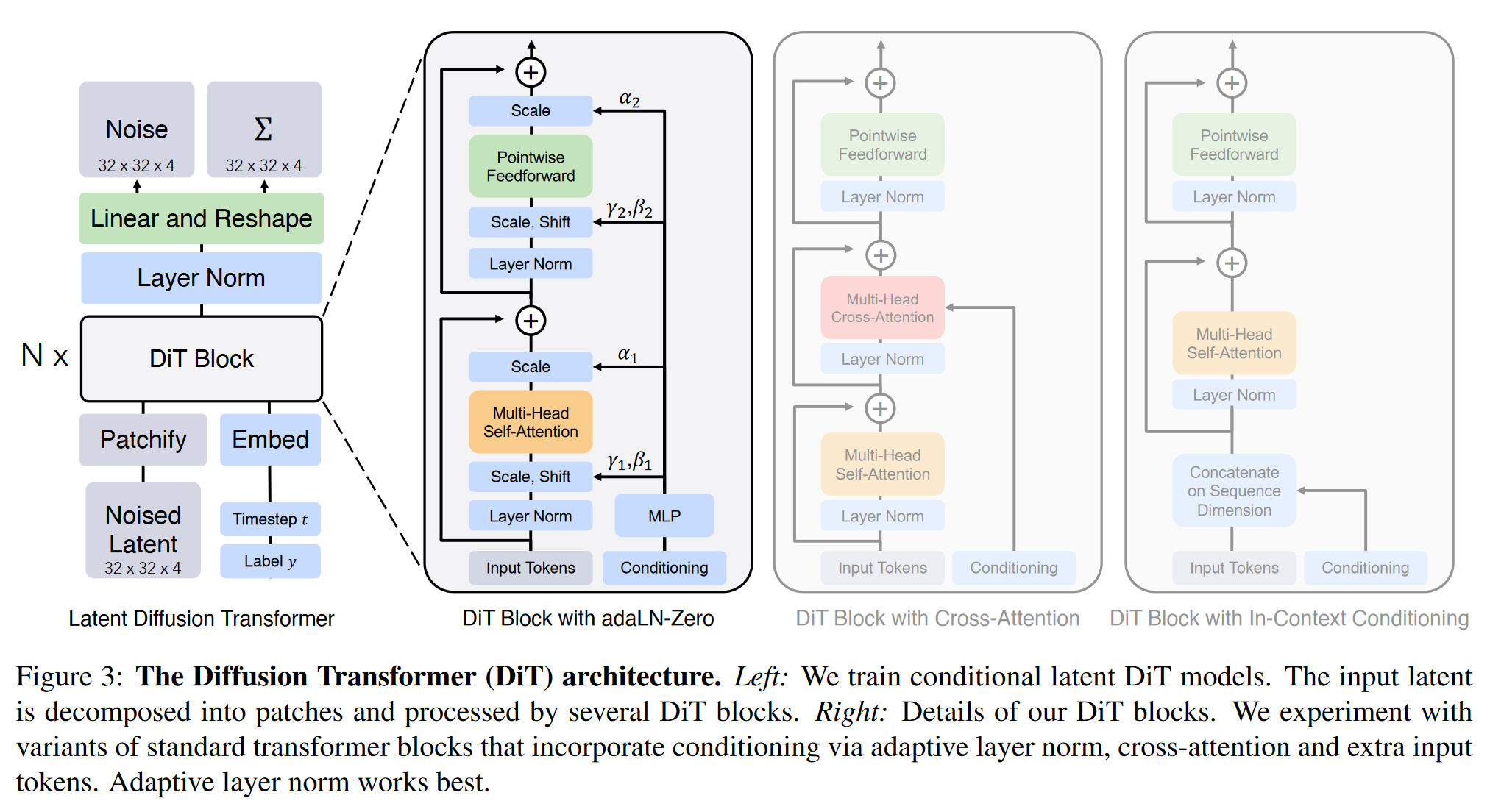
Diffusion Transformer 是一种基于Transformer的扩散模型架构,DiT 保留了 ViT 的许多最佳实践,保持Transformer的可扩展性,特别是用于图像生成任务。
Patchify.
- DiT的输入是空间表示z,对于256×256×3的图像,z的形状为32×32×4。每个图像被划分为多个小补丁(patch),每个补丁的特征维度是4。
- DiT 第一层是“patchify”,它通过线性嵌入将每个补丁转换为一个维度为d的token序列。这一步骤使得模型可以处理输入图像的局部特征。
- 在patchify之后,DiT使用标准 ViT 基于频率的位置嵌入(sine-cosine version),为所有输入token添加位置信息。
- 生成的token数量T由补丁大小超参数p决定。如果将p减半,T将增加四倍,从而使
transformer
Gflops至少增加四倍。然而,改变p对模型的参数总数没有实质性影响。
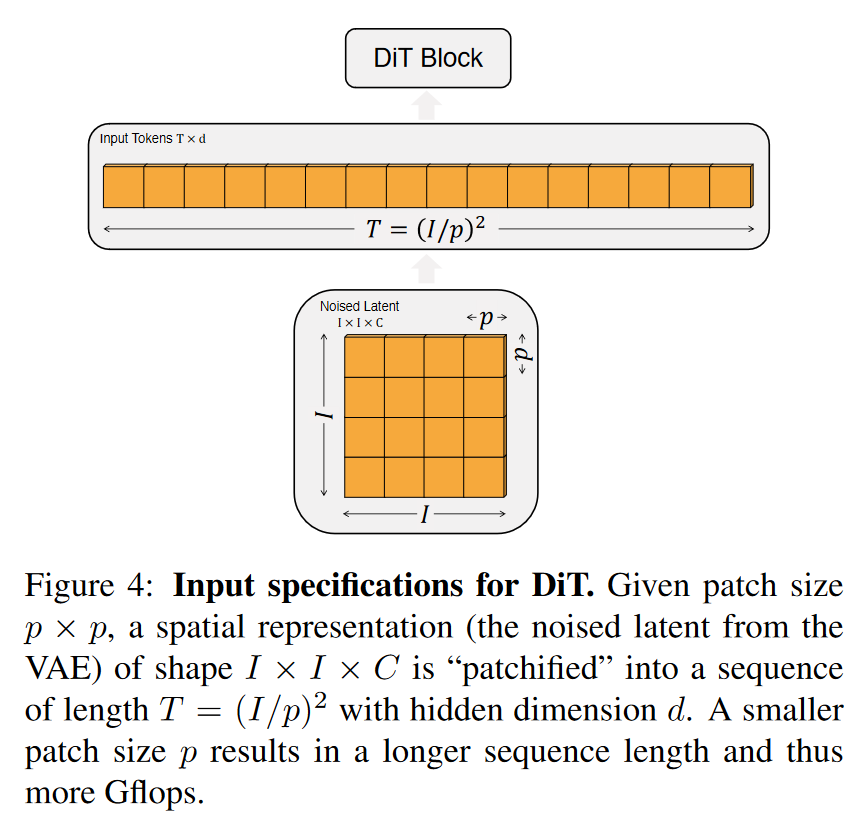
- 在DiT的设计空间中,考虑了p=2、4、8三种补丁大小。
DiT block design.
在 patchify 之后,输入token会通过一系列变换器块进行处理。除了噪声图像输入外,扩散模型还可能处理其他条件信息,如噪声时间步 t 、类别标签 c 、自然语言等。
针对条件输入,本文提出了四种不同的变换器块设计,每种设计对标准ViT块进行了小但重要的修改
- 上下文条件(In-context conditioning):将 t 和 c
的向量嵌入作为两个额外的token直接添加到输入序列中,与图像token没有区别。这种方法不需要修改标准的ViT块(类似于
ViT 中的
clstokens),并在最终块后移除条件token,几乎不增加 Gflops。 - 交叉注意力块(Cross-attention block):将 t 和 c 的嵌入合并为一个长度为2的序列,与图像token序列分开。该transformer块在自注意力层之后增加了一个多头交叉注意力层。这种设计会显著增加Gflops,约15%的计算开销。
- 自适应层归一化块(Adaptive layer norm (adaLN) block):将标准层归一化替换为adaLN。该层通过对 t 和 c 的嵌入向量的和进行回归,学习维度缩放和偏移参数。与其他块设计相比,adaLN在增加Gflops方面最小,因此在计算上最有效,也是唯一一个对所有token应用相同功能的机制。
- adaLN-Zero块:借鉴ResNet的研究,发现将每个残差块初始化为恒等函数是有益的。该设计在adaLN基础上进行修改,在任何残差连接之前也回归维度缩放参数
。初始化多层感知机以对所有 都输出零向量,这会将完整的 DiT 块初始化为恒等函数。这意味着在训练初期,adaLN-Zero块不会对输入施加任何变换。与标准的adaLN块一样,adaLN-Zero 向模型添加了可以忽略不计的 Gflops。
- 上下文条件(In-context conditioning):将 t 和 c
的向量嵌入作为两个额外的token直接添加到输入序列中,与图像token没有区别。这种方法不需要修改标准的ViT块(类似于
ViT 中的
Model size.
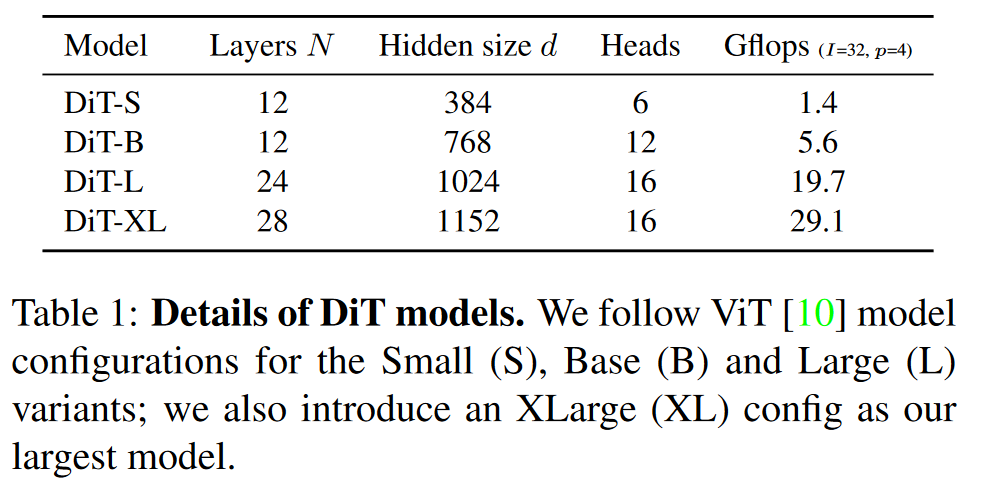
- 使用的一系列 N 个的DiT块,每个块的隐藏维度大小为 d 。
- 参考 ViT ,作者采用了标准的变换器配置,联合调整 N 、d 和注意力头,以实现不同规模的模型。
- 作者定义了四种模型配置:DiT-S、DiT-B、DiT-L和DiT-XL。这些配置覆盖了从0.3到118.6 Gflops 的一系列模型规模,使作者能够评估模型的扩展性能。
Transformer decoder.
- 在经过最后一个DiT块后,模型需要将图像token序列解码为两个输出:一个是噪声预测,另一个是对角协方差预测。这两个输出的形状与原始的空间输入相同。
- 为了解码这些token,使用了一个标准的线性解码器,将每个token的表示转化为所需的输出形状。
- 在解码之前,首先应用最后层归一化,(如果使用 adaLN 则为自适应)。
- 每个token被线性解码为一个形状为
的张量,其中 p 是补丁的大小,C 是 DiT 空间输入中的通道数。 - 最后,将解码后的tokens重新排列成原始的空间布局,使得模型的输出可以直接用于后续的任务或与原始图像进行比较,以获得预测的噪声和协方差。
3. 论文实验评估方法与效果
- DiT块设计
- 作者训练了四个DiT-XL/2模型,使用不同的块设计(in-context、cross-attention、adaLN、adaLN-zero)
- adaLN-Zero的初始化方式(将每个DiT块初始化为恒等函数)显著优于普通的adaLN
- 缩放模型大小和补丁大小
- 训练了12个DiT模型,变化模型配置(S、B、L、XL)和补丁大小(8、4、2)。
- 随着模型规模增加和补丁大小减小,FID显著改善。
- 增大模型的深度和宽度也有助于改进FID。
- DiT Gflops 对于提高性能至关重要
- 参数数量并不是唯一影响模型质量的因素。即使在保持模型规模不变时,总参数实际上没有改变,但是减少补丁大小会导致Gflops增加,从而提高性能。
- 较大的 DiT 模型的计算效率更高
- 可视化缩放
- 在训练400K步骤后,从每个DiT模型中采样图像,使用相同的起始噪声、采样噪声和类别标签,旨在直观地观察模型规模和token数量对生成图像质量的影响。
- 随着模型规模和处理token数量的增加,生成图像的质量有明显改善。
DiT-XL/2模型在图像生成任务上,相比现有最先进的扩散模型取得了显著的性能提升。
增加采样计算量(如增加采样步数)并不能弥补模型计算量的不足。即便较小的模型通过增加采样步数来提升图像质量,较大的模型仍然能够在更少的计算开销下生成更高质量的图像。