1 研究背景、动机、主要贡献
1.1 研究背景
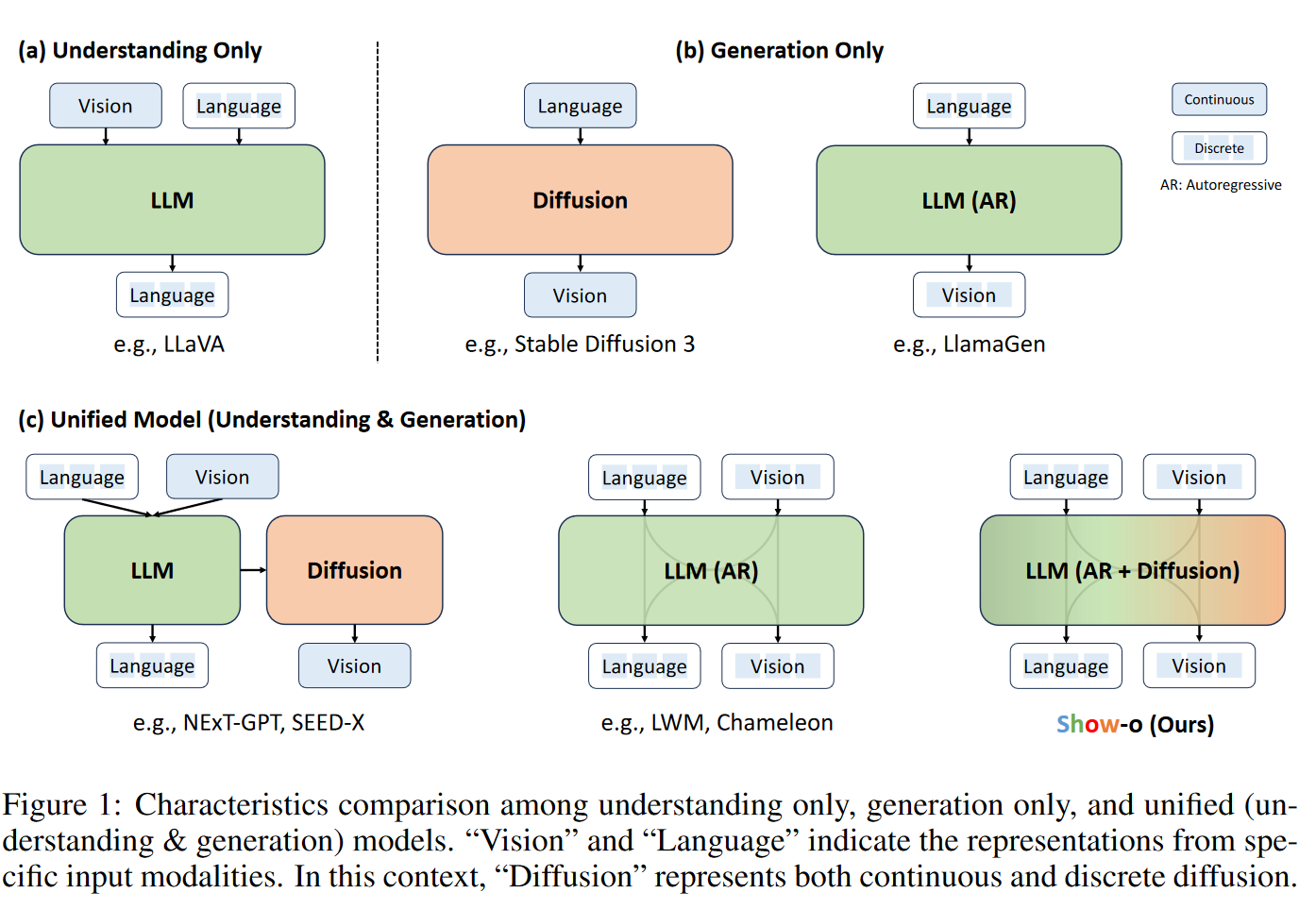
现有的尝试主要是独立地对待每个领域,并且通常涉及单独负责理解和生成的模型。
1.2 主要贡献
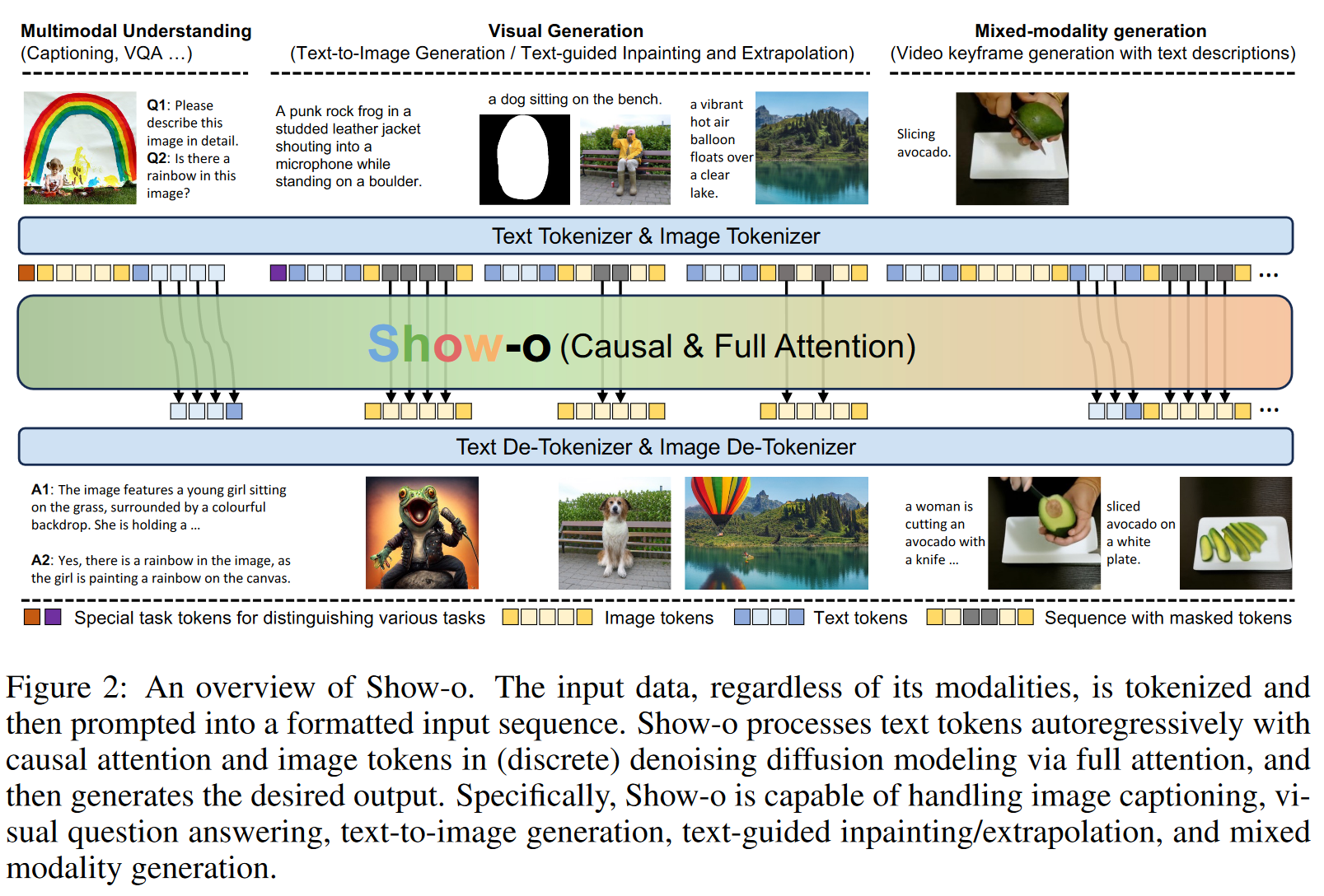
- 提出了Show-o,一个能够同时处理多模态理解和生成任务的统一Transformer模型。
- 创新地将自回归和离散扩散建模统一到一个单一Transformer中,实现了文本和图像的有效处理。
- Show-o在多模态理解和生成基准测试中,表现出与参数量相当甚至更优于单一模型的性能。
- Show-o无需额外微调即可支持文本引导的图像修复、扩展等下游任务,并展示了混合模态生成的潜力。
- 探讨了不同图像表示(离散和连续)对多模态理解的影响,为未来统一模型的设计提供了有价值的见解。
RELATED WORK
MULTIMODAL UNDERSTANDING
LLMs 的显著进展推动了多模态大型语言模 MLLMs 的发展。许多方法使模型能够在Transformer结构内整合和处理不同模态的数据。但大多数模型的训练仍然基于自回归生成范式,且侧重理解任务。
VISUAL GENERATION
- Autoregressive models
- Diffusion models
- 本文采用离散扩散模型
UNIFIED VISION-LANGUAGE FOUNDATION MODEL
与现有工作相比,同样采用离散标记来表示所有模态。不同的是,本文使用离散扩散过程而不是自回归建模来进行视觉生成。
PRELIMINARIES
- Show-o模型基于MaskGIT(简化的离散扩散方法)
2 论文提出的新方法
作者提出四个核心问题 - 如何定义模型的输入/输出空间? - 如何统一不同模态的输入数据? - 如何在一个单一的 Transformer 中同时结合自回归和扩散建模? - 如何有效地训练这样一个统一的模型?
2.1 TOKENIZATION
将文本和图像转化为离散的 token,使用同样的学习目标来预测这些离散的 token。
- Text Tokenization:基于预训练的语言模型,利用相同的 tokenizer 。
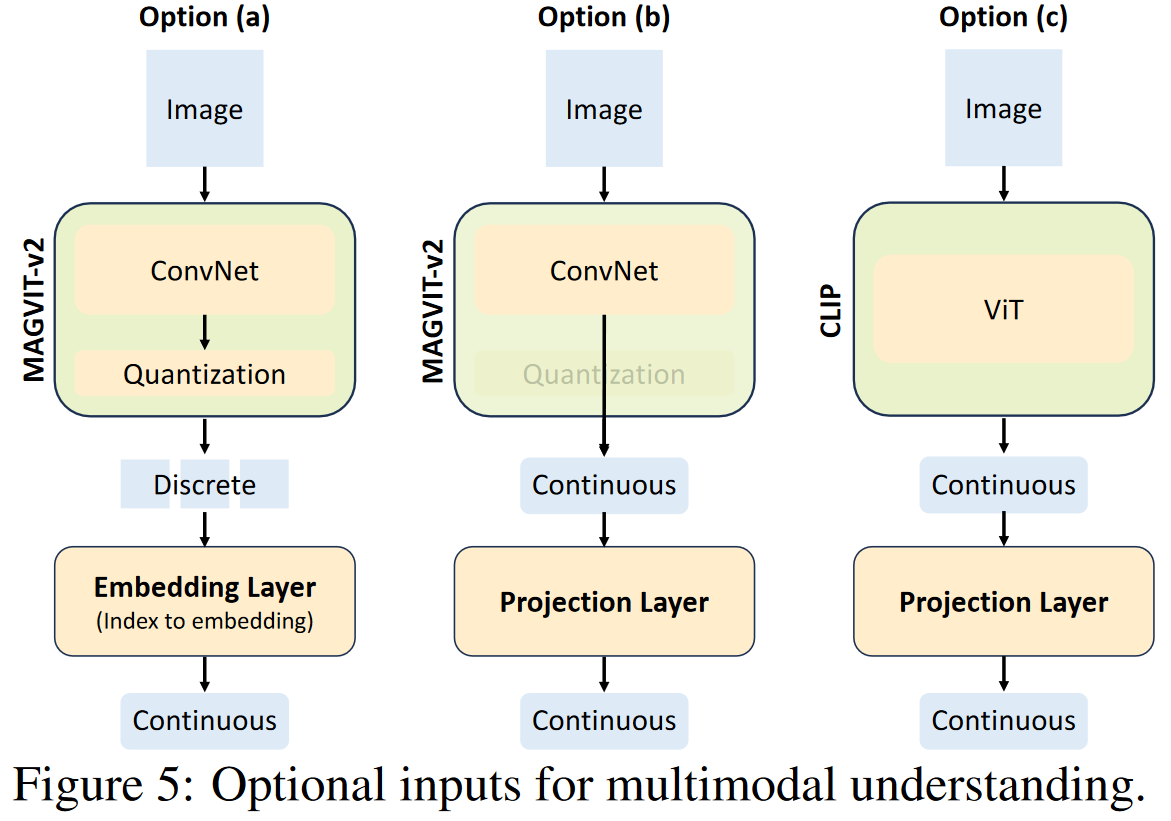
- Image Tokenization:借鉴 MAGVIT-v2 模型,将分辨率为 256×256 的图像编码为 16x16 的离散 token,保持一个 8192 大小的词汇表。
2.2 ARCHITECTURE
Unified Prompting
Show-o 基于预训练的 LLM 架构,唯一的改动是在每一层注意力机制前加入了 QK-Norm 操作。与扩散模型不同,Show-o 不需要额外的文本编码器,因为它已经内置了文本条件编码功能。
为了解决不同任务中的多模态学习问题,Show-o
设计了一个统一的提示策略,将文本
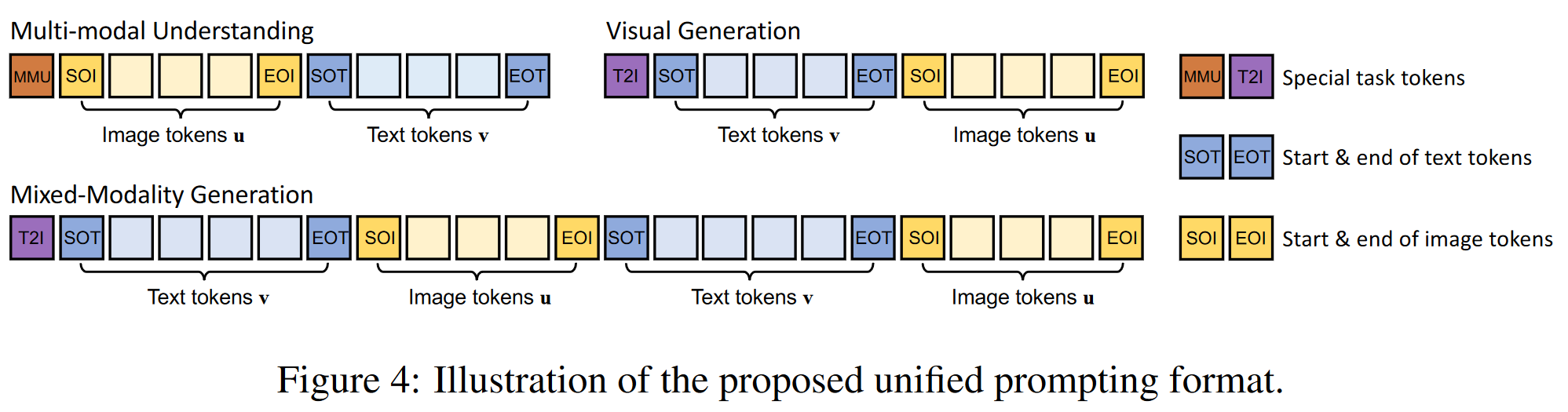
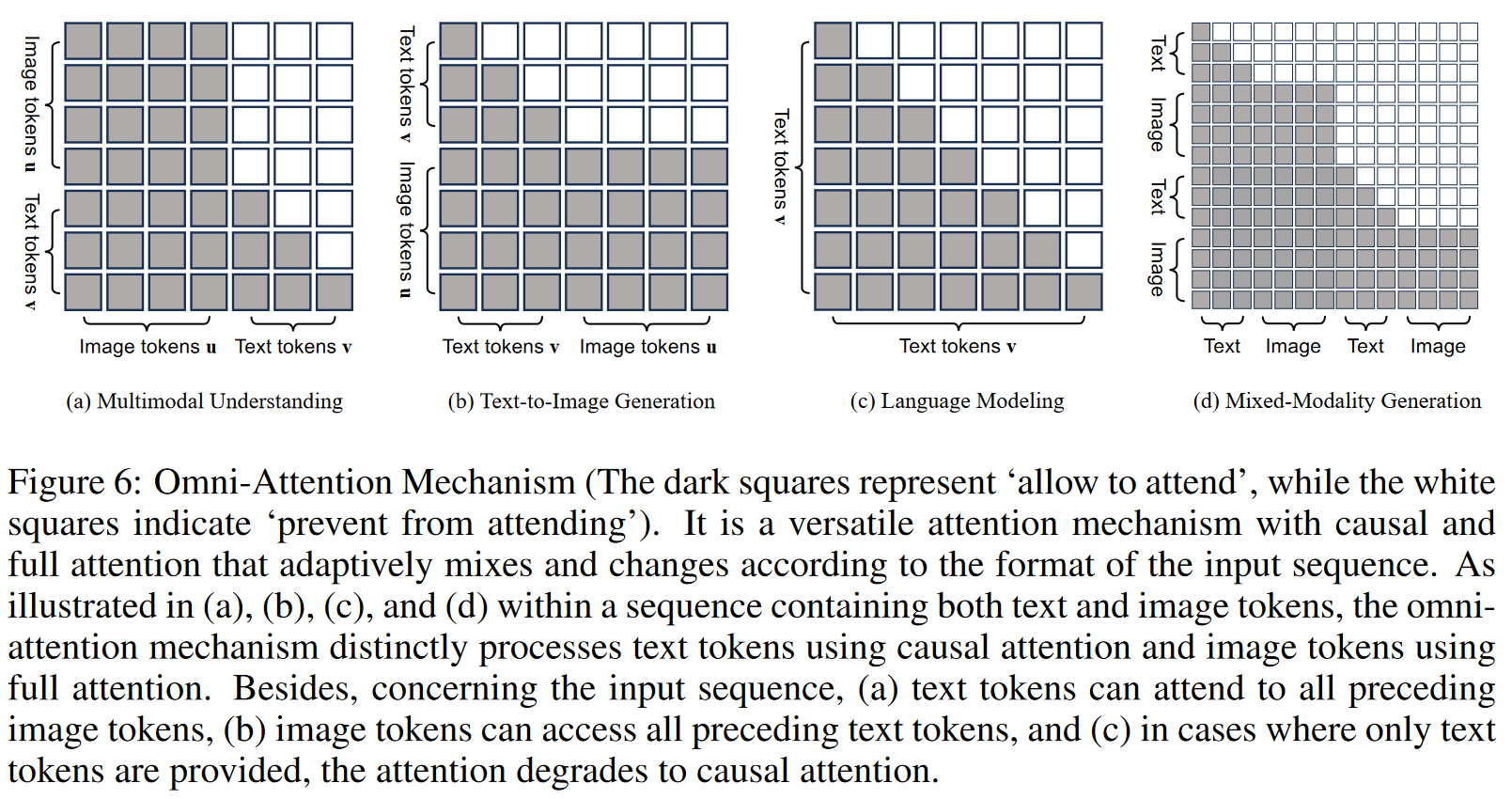
Omni-Attention Mechanism.
全局注意力机制(Omni-Attention Mechanism)
该方法与 Transfusion 相似
Training Objectives
- Next Token Prediction (NTP):用于文本和图像 token 的下一个 token
预测,最大化每个 token 的条件概率。
- Mask Token Prediction (MTP):离散扩散建模的一部分,通过随机替换图像
token 为 [MASK],并利用未被遮掩的部分进行重构,最大化重构的可能性。
也加入了 classifier-free guidance
最终的损失函数
2.3 Training Pipeline
Image Token Embedding and Pixel Dependency Learning
- 使用 RefinedWeb 数据集保持模型的语言建模能力。
- ImageNet-1K 数据集
- 类名作为文本输入,模型学习根据给定的类生成相应的图像。
- 35M 图像文本对
- 训练图像描述
- 此阶段主要涉及学习离散图像标记的新可学习嵌入、图像生成的像素依赖性以及图像字幕的图像和文本之间的对齐。
Image-Text Alignment for Multimodal Understanding and Generation
训练的重点是对齐图像和文本
基于预训练的权重,模型进一步在 35M 图像-文本配对数据上进行训练。这一步的重点是增强图像和文本的对齐,以便更好地执行图像生成和图像标题生成任务。
High-Quality Data Fine-tuning
通过合并用于文本到图像生成的过滤高质量图像文本对以及用于多模态理解和混合模态生成的指导数据,进一步完善了预训练的 Show-o 模型。
2.4 Inference
- 在多模态理解中,使用自回归方式预测文本 token。
- 在图像生成过程中,预测每个 [MASK] 标记的 logit
。保留具有较高置信度的预测图像标记,同时用 [MASK] 标记替换那些具有较低置信度的图像标记
3 实验评估方法与效果
定量实验在某些指标上也并不是最优的。
定性结果上,SDXL LlamaGen LWM SEED-X Show-o (Ours) 五者。Show-o结果与SDXL相近,其余三者效果差一些。
ABLATION STUDIES
图像编码器对多模态理解的影响
- CLIP-ViT的连续表示在多模态理解方面比MAGVIT-v2具有明显更好的性能
- 原因
- CLIP-ViT的预训练数据量(400M)比MAGVIT-v2(35M)大得多;
- CLIP-ViT使用图像-文本匹配作为判别性目标,而MAGVIT-v2的目标是图像重建,使得CLIP-ViT提取的表示更适合于多模态理解。
各种表示对多模态理解的影响:连续表示比离散表示结果更好。
统一预训练对多模式理解的影响:
- 对于CLIP-ViT的连续表示,统一预训练在一定程度上带来了负面影响。
- 对于MAGVIT-v2的连续表示,统一预训练带来了性能提升,说明统一预训练通过预训练期间的多种多模态交互增强了主干的多模态理解和推理能力。
- 对于MAGVIT-v2的离散token,统一预训练效果最好,说明统一的预训练学习了与大规模数据更好的跨模态对齐,并增强了主干的多模式理解能力。
采样步骤的影响:采样步数越多生成效果越好。与其他模型相比,Show-o仅需很少的采样步数便能生成高质量图像。
无分类器指导的影响:引导系数增加时,生成图像的色彩和内容更加多样,更符合文本提示。
4 论文方法局限性
- 文本识别/生成
- 对象计数
原文链接:SHOW-O: ONE SINGLE TRANSFORMER TO UNIFYMULTIMODAL UNDERSTANDING AND GENERATION