1. 研究背景、动机(Why)
1.1 研究背景
LM 经常表现出一种倾向,即产生极其自信但错误的断言,通常被称为幻觉。这种现象严重阻碍了它们在事实准确性至关重要的领域的适用性。
1.2 存在问题(动机)
- 不确定性的指标在有限 API 访问的商业黑盒 LM中不可获取:幻觉可以通过捕捉不确定性的指标来检测输出序列。然而,这些指标需要访问令牌级别的日志概率,而这在 ChatGPT 或 Bard 等仅提供有限 API 访问的商业黑盒 LM 中不可用。
1.2.1 现有方案
- 基于采样的方法,通过建立置信度和自我一致性之间的联系来近似不确定性估计。
缺点:自我一致性并不一定能保证事实答案
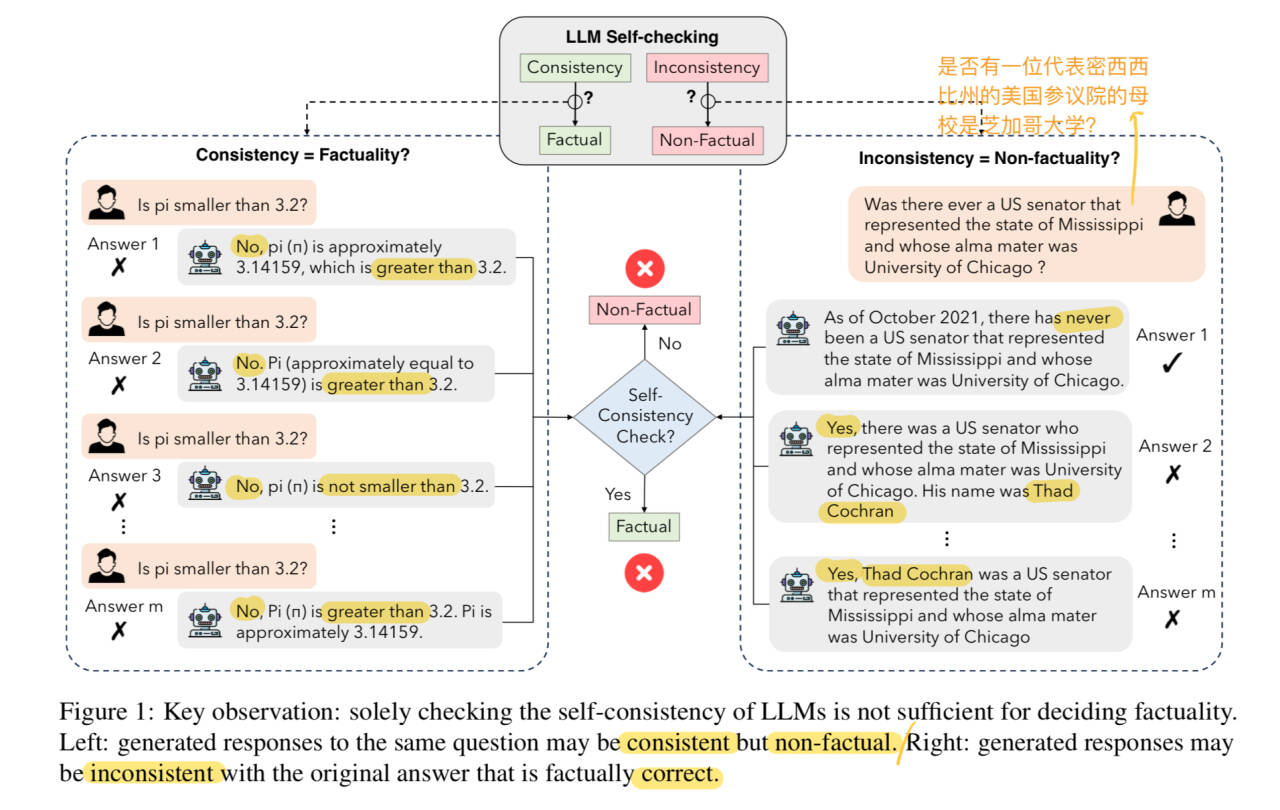
- 依赖外部资源,比如从外部数据库检索知识
2. 论文提出的新思路、新理论、或新方法(What)

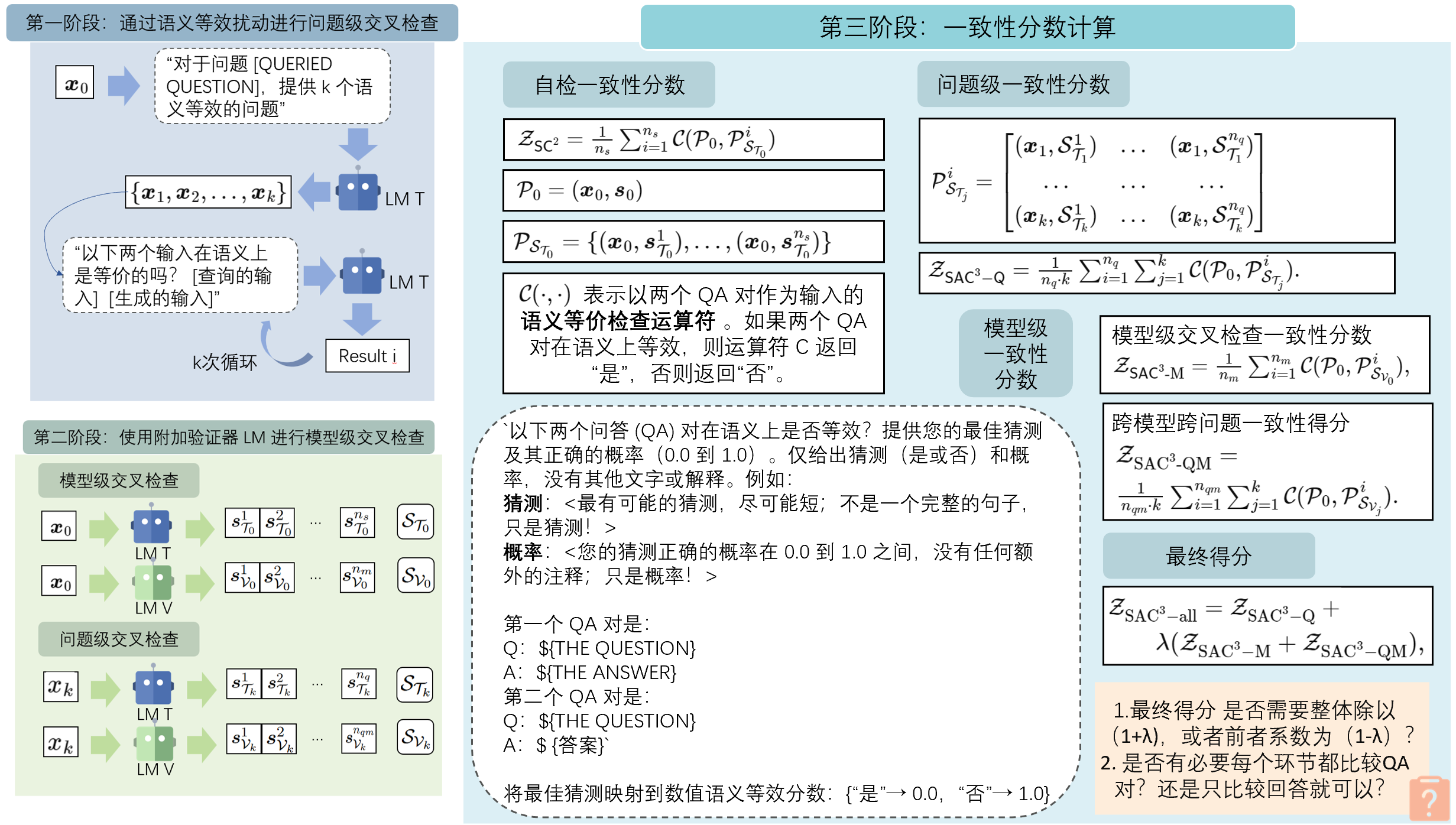
2.1 第一阶段:通过语义等效扰动进行问题级交叉检查
通过生成保留语义等价的替代输入来重新表述输入查询,即语义上等效的输入扰动。
1. 根据查询输入
2.2 第二阶段:使用附加验证器 LM 进行模型级交叉检查
- 让
表示来自基于给定查询 的目标 LM 的原始响应。 - 检测
是否出现幻觉。引入了一个额外的验证器 LM,表示为 ,用于模型级交叉检查 - 两个语言模型
、 分别回答第一阶段生成的 k 个问题的回答定义为 - 从目标LM的回答中,抽取
个样本 - 从验证LM的回答中,抽取
个样本
- 两个语言模型
- 问题级交叉检查 对于
- 目标LM生成
个样本响应序列 - 验证LM生成
个样本响应序列
- 目标LM生成
- 结合自检和交叉检查中抽取的所有样本。收集总样本集
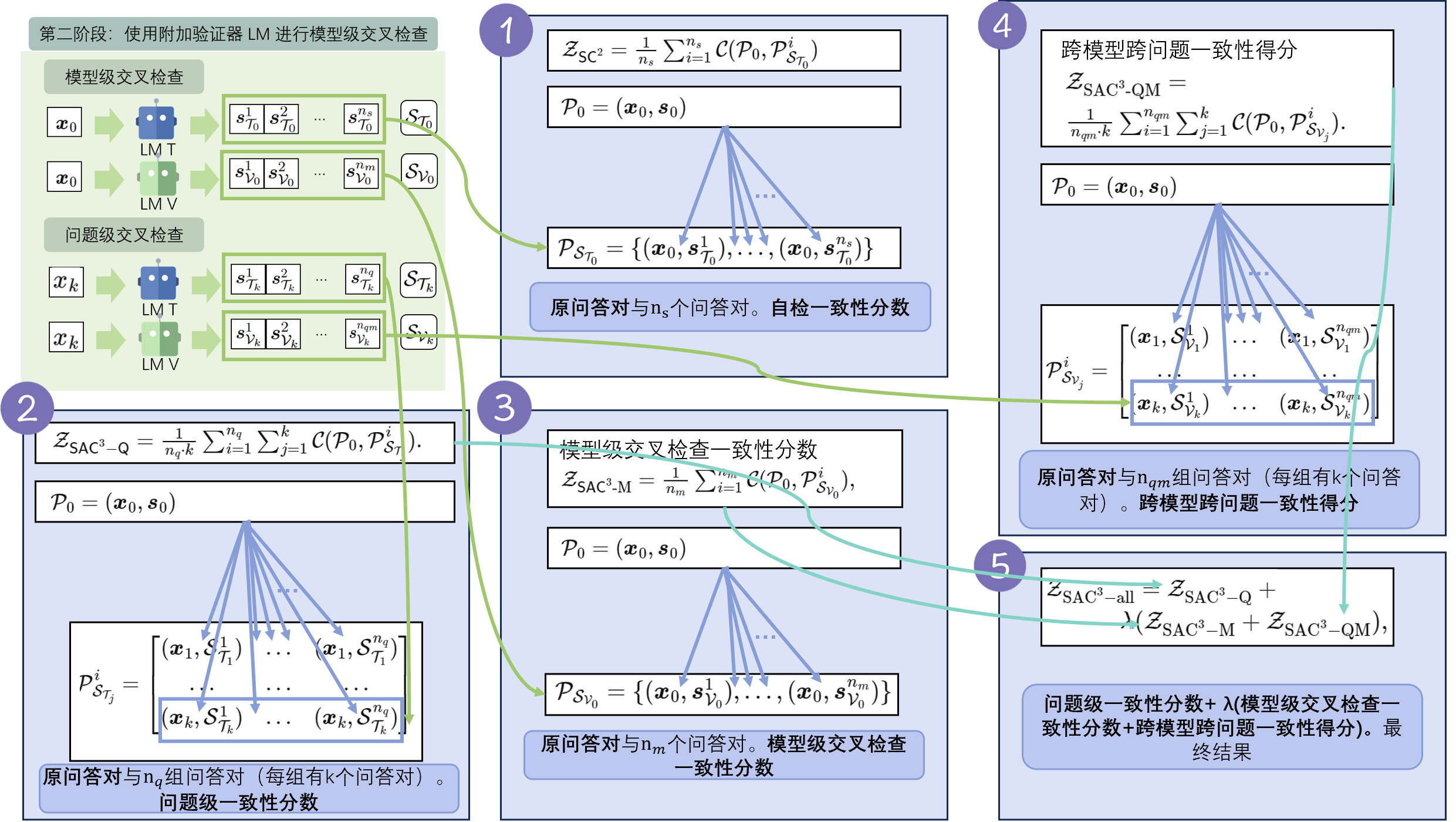
2.3 第三阶段:一致性分数计算
- QA 对的语义感知一致性检查
- 同一问题的表述方式不同,答案(例如“否”和“是”)在词汇上可能不等效。但 QA 对作为一个整体在语义上可能是等效的
- 自检一致性
分数 表示以两个 QA 对作为输入的语义等价检查运算符 。如果两个 QA 对在语义上等效,则运算符 C 返回“Yes”,否则返回“No”。 - 利用提示来使用 LM 实现检查运算符:“以下两个问答 (QA) 对在语义上是否等效?[QA 对 1] [QA 对 2] ”
- 将最佳猜测映射到数值语义等效分数:{“Yes”→ 0.0,“No”→ 1.0}
- 用
来表示原始 QA 对,目标LM 的自检分数 可计算为 其中 >[!question] >在此处是否有必要比较QA对?还是只比较回答就可以?
- 问题级一致性
分数 - 模型级一致性
分数 - 模型级交叉检查一致性得分
跨模型跨问题一致性得分
- 模型级交叉检查一致性得分
- 最终得分
λ 是验证者 LM 的权重因子。除非另有说明,在本实验中默认使用 λ = 1 >[!question]+ >是否需要整体除以(1+λ),或者前者系数为(1-λ)?
- 每个组件并行计算
- 将最终得分与预设阈值进行比较来做出检测预测
3. 论文方法的理论分析或实验评估方法与效果(How)
3.1 分类QA任务中的效果
50% 幻觉样本和 50% 事实样本情况下,在分类QA任务上比较 SC2 和 SAC3-Q
的表现 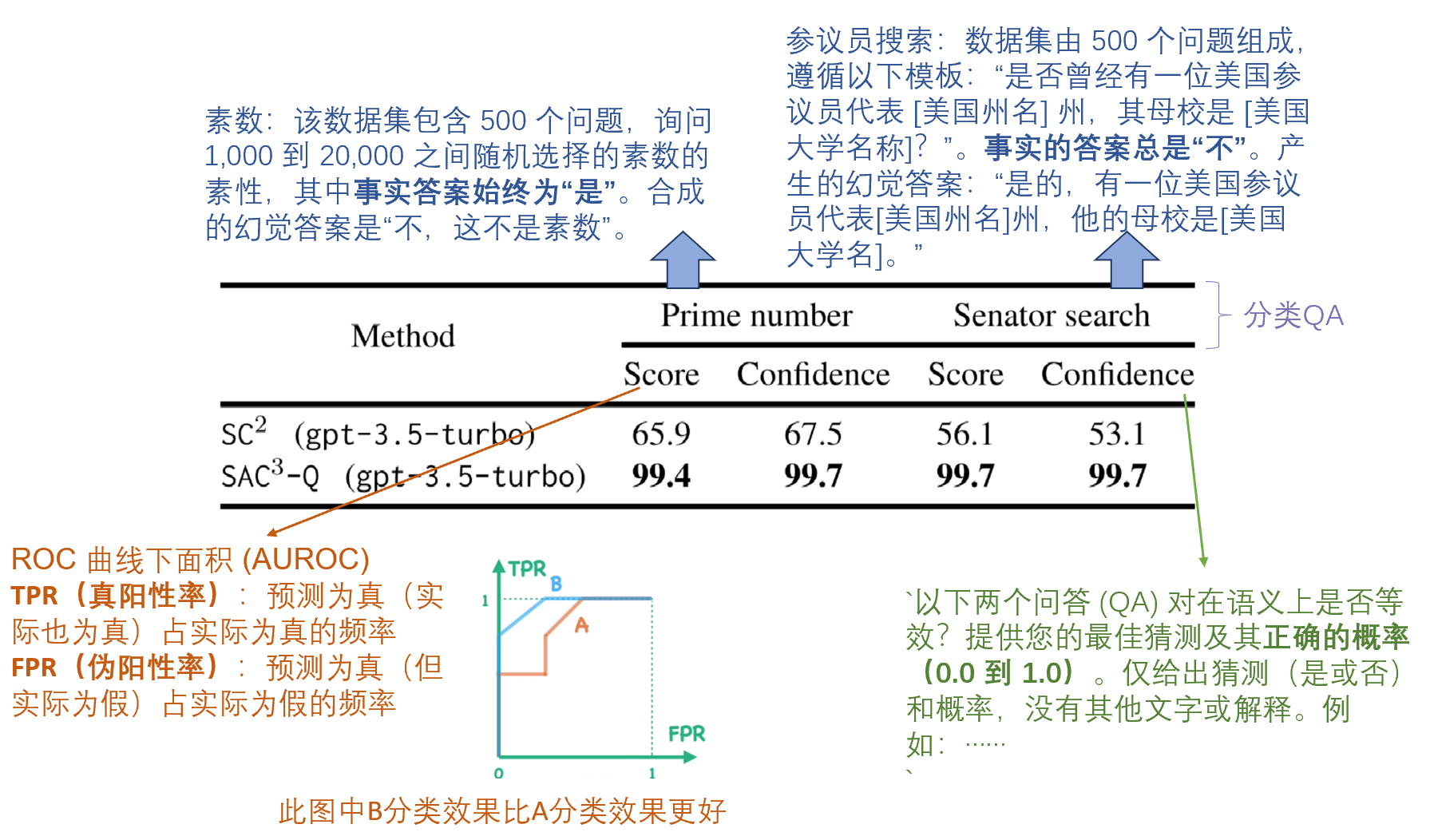
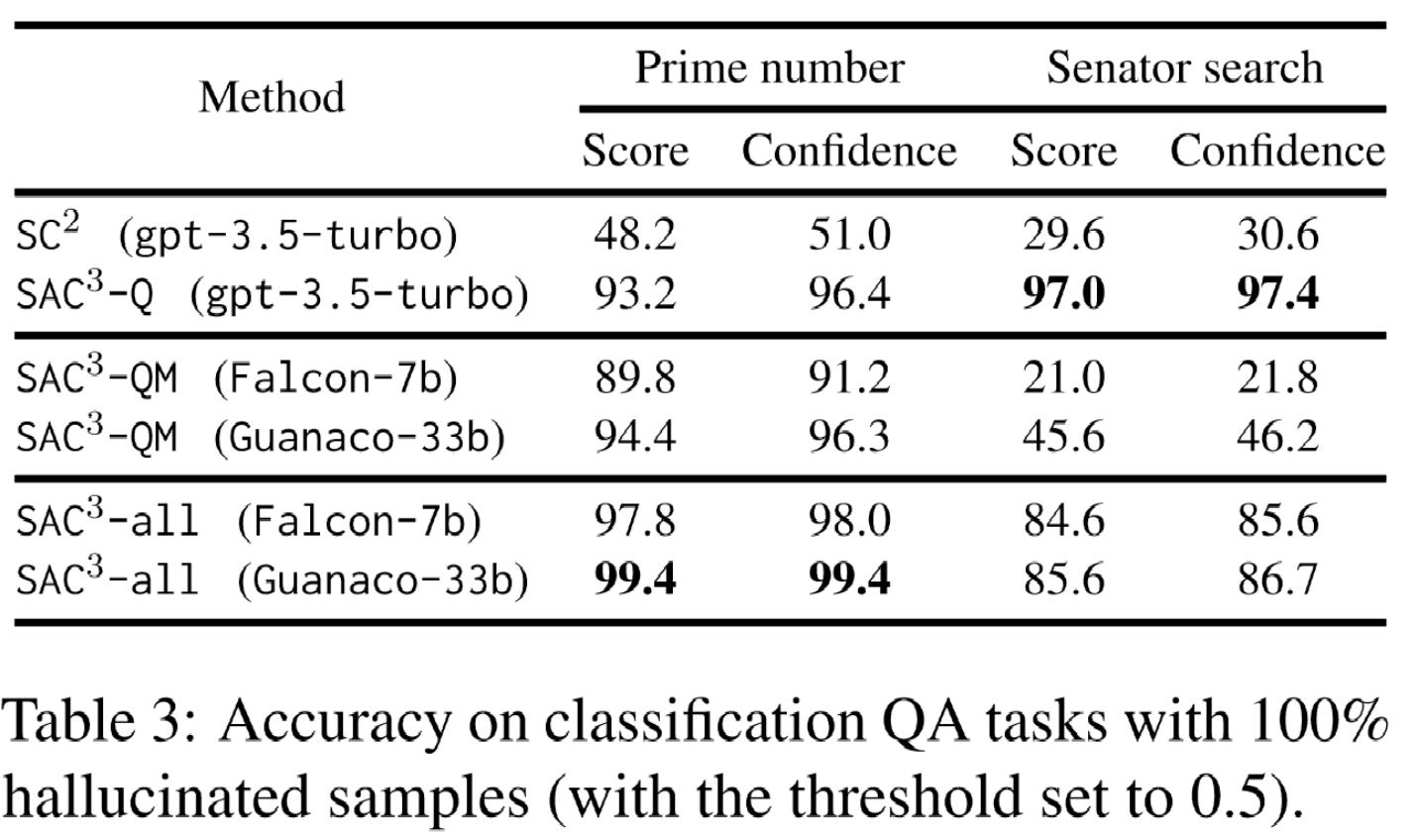
100% 幻觉样本、预设阈值 0.5情况下,在分类QA任务上比较 SC2 、SAC3-Q
、
阈值对检测精度的影响 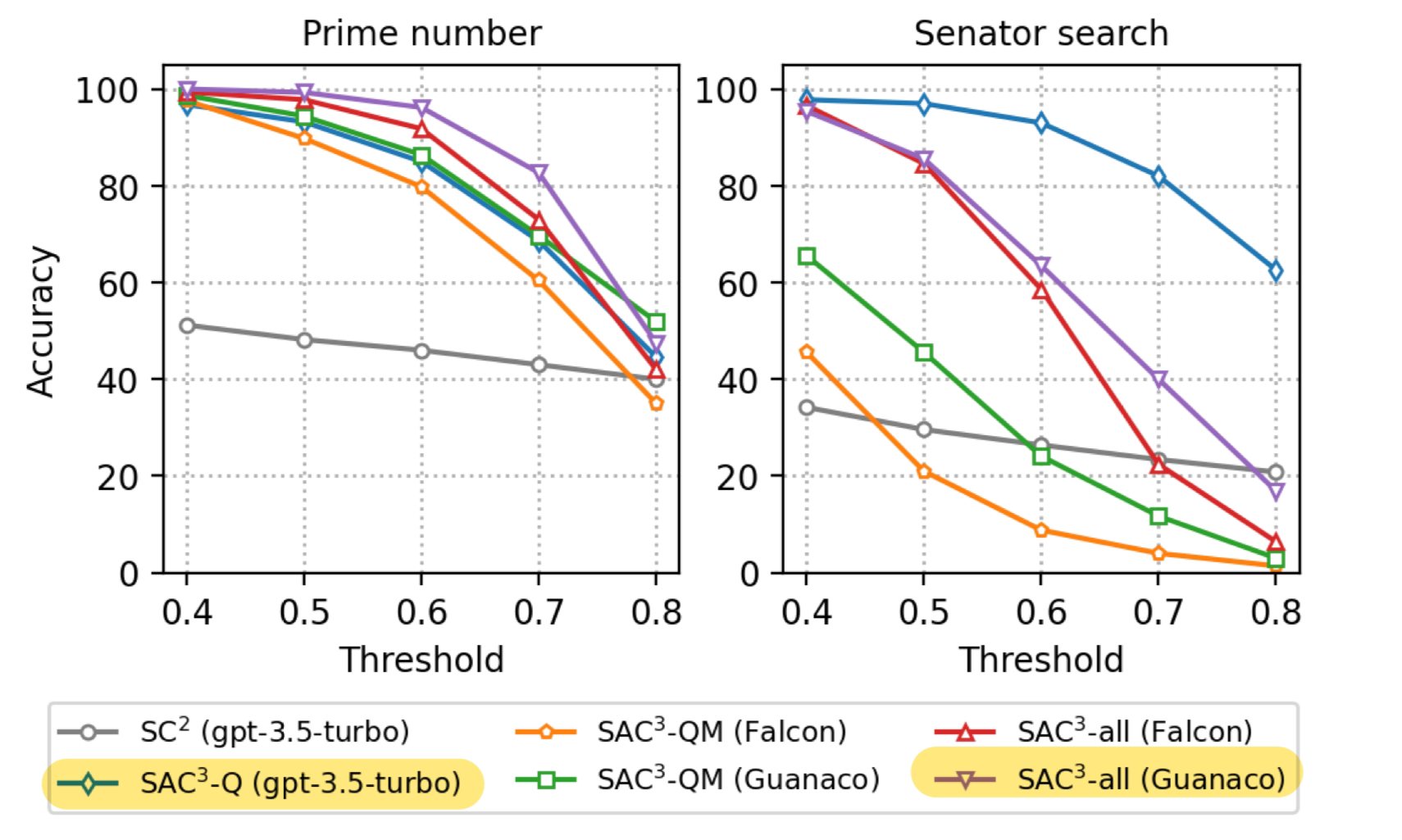
- 对于 SC2,很大一部分幻觉样本收到了高度一致的预测
- 受益于语义等效的问题扰动,SAC3-Q 的分数更加分散在不一致的区域中
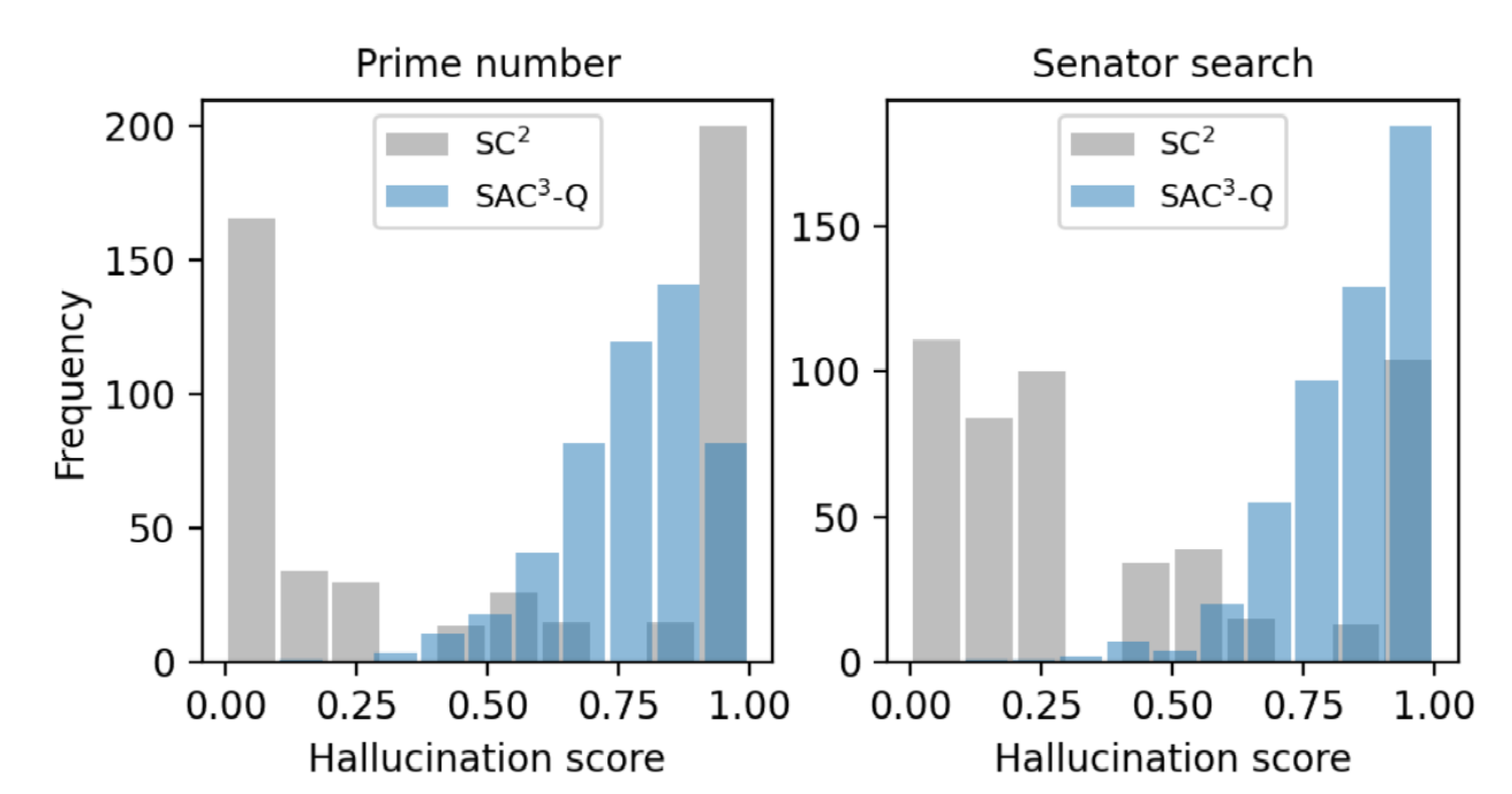
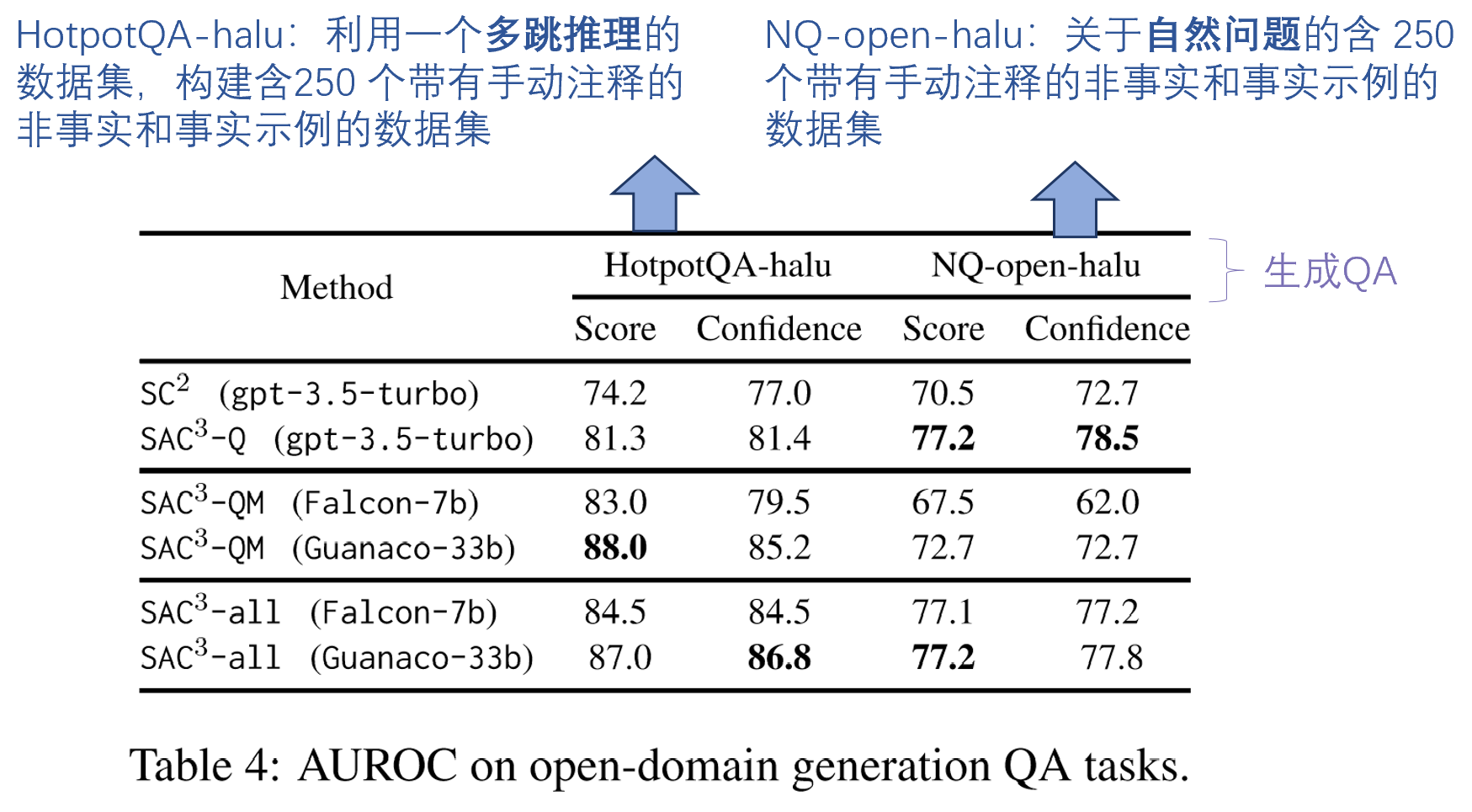
3.2 开放域生成QA任务中的效果
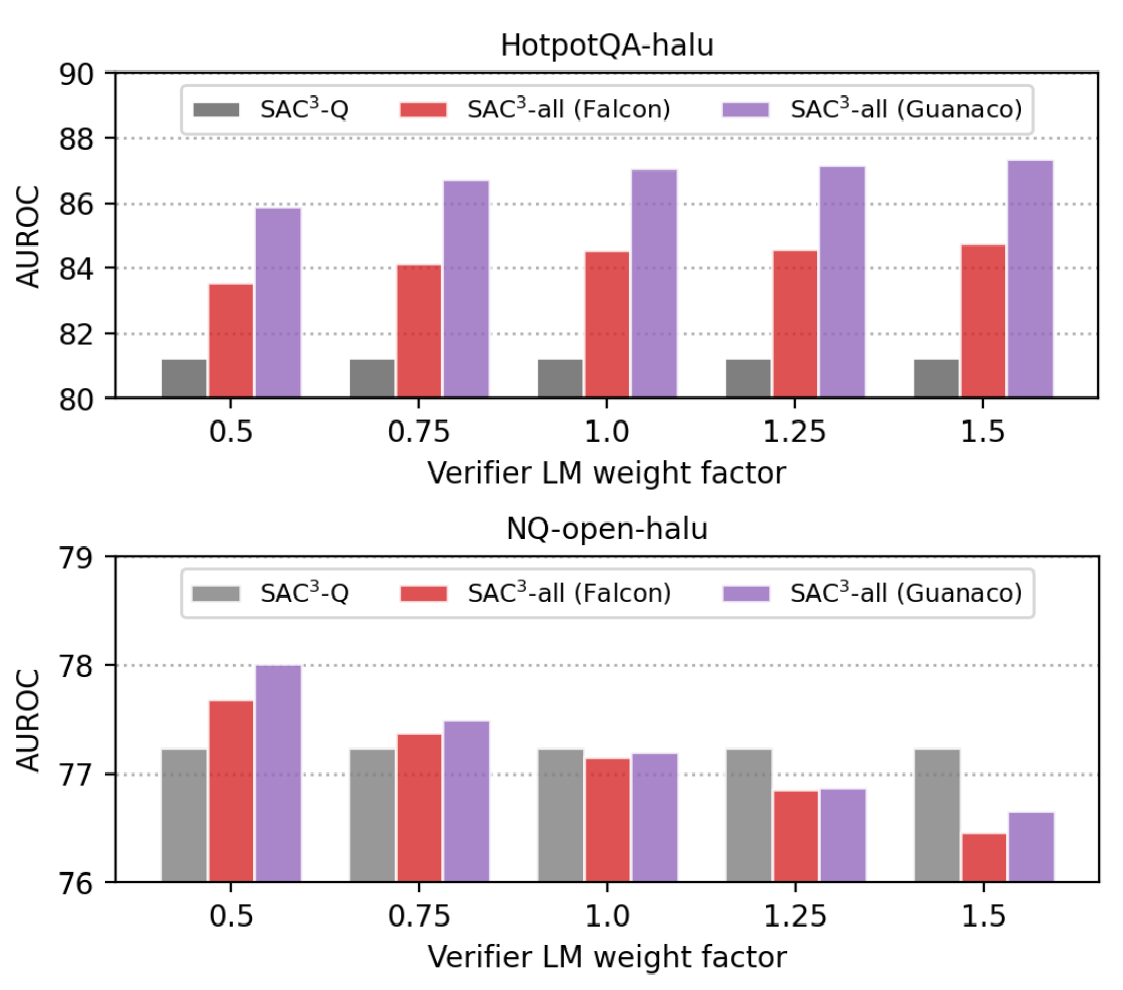
- 信任差异可以通过在验证者 LM 生成的一致性分数中引入权重 λ 来体现。
- 例如,如果目标是检测特定领域中的幻觉,并且验证器 LM
是为此领域开发的特定领域模型,我们可以为其分数分配较大的权重(例如,λ
>
1.0)。一般情况下,验证者LM是小型开源模型,我们可以应用较小的权重值(例如,λ
< 1.0)来抵消验证者LM对最终得分的影响。 验证者 LM 权重对 AUROC
的影响:
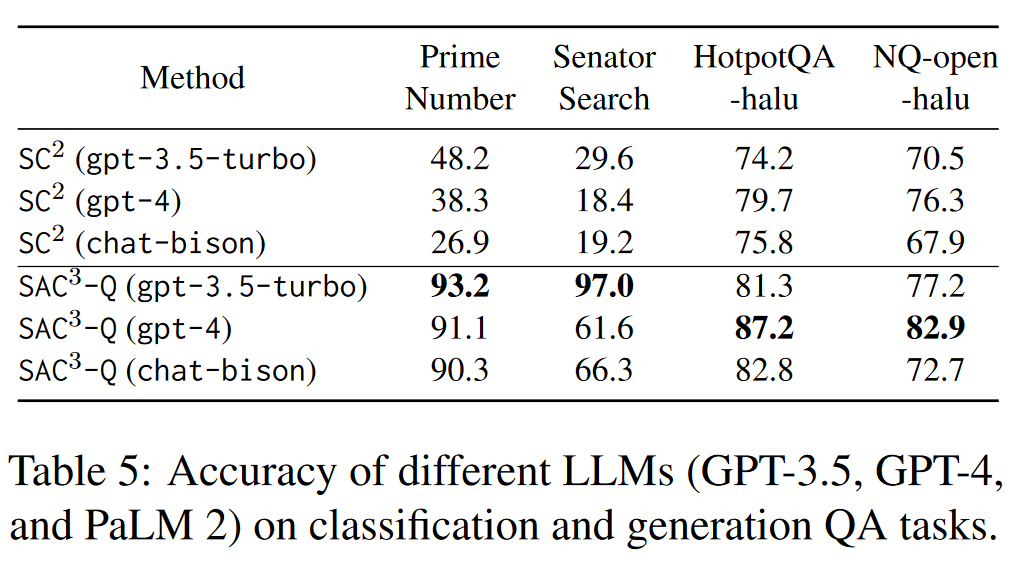
不同 LLM(GPT-3.5、GPT-4 和 PaLM 2)在分类和生成 QA 任务上的准确性。
数据集方面:在分类 QA 和生成 QA上评估幻觉检测方法,每个类别包含两个数据集。
- 分类QA
- 素数:该数据集包含 500 个问题,询问 1,000 到 20,000 之间随机选择的素数的素性,其中事实答案始终为“是”。合成的幻觉答案是“不,这不是素数”。
- 参议员搜索:数据集由 500 个问题组成,遵循以下模板:“是否曾经有一位美国参议员代表 [美国州名] 州,其母校是 [美国大学名称]?”。事实的答案总是“不”。我们还会产生幻觉答案:“是的,有一位美国参议员代表[美国州名]州,他的母校是[美国大学名]。”
- 生成 QA (手动注释答案的真实性)
- HotpotQA-halu:利用一个多跳推理的数据集,构建含250 个带有手动注释的非事实和事实示例的数据集
- NQ-open-halu:关于自然问题的含 250 个带有手动注释的非事实和事实示例的数据集
实验设置
- 评估 模型
- 目标 LM: OpenAI 的 gpt-3.5-turbo
- 验证器 LM:
- (1)Falcon-7b-instruct(Almazrouei 等人,2023):由 TII 构建的开源因果解码器模型,在 RefinedWeb 的 1,500B 代币上进行训练( Penedo 等人,2023)并使用精选语料库进一步增强;
- (2)Guanaco-33b:通过 QLoRA(Dettmers 等人,2023)调整 OASST1 数据集上的 LLaMA(Touvron 等人,2023)基本模型的开源指令跟踪模型。
- 实施细节
- 在执行语义扰动和一致性检查时,将温度设置为 0.0 以获得确定性的高质量输出。
- k = 10
- 对于基于自检的方法 SC2,将温度设置为 1.0 并生成 ns = 10 个随机样本。
- 对于 SAC3-Q 和 SAC3-QM ,设置 nq = nqm = 1 以减少计算成本。为了进一步降低推理成本,默认设置 nm = 1 ,
- 使用幻觉检测精度和 ROC 曲线下面积 (AUROC) 来评估性能。除了估计的幻觉分数之外,我们还显示了目标 LM 的语言概率(Tian et al., 2023)以进行比较。
实验细节 
4. 论文优缺点、局限性、借鉴性
优点:
- SAC3方法不依赖于语言模型的内部结构,适用于黑盒语言模型,在实际应用中更为广泛。
- 考虑到了输入的一致性,检验QA对整体的一致性,而非答案一致性。
改进:
- 如何增强语义扰动的多样性?
- 比如可以完善提示“使用同义词和反义词”、“句式变换”、“改变问题的风格和语调”
- 交叉检查所带来的效率问题,如何简化交叉检查?(选择最具代表性和关键性的特征进行交叉检查,避免对所有特征都进行全面比对)
- 该方法的并行只是各个得分计算可以并行。如何设计提示来同时生成多个语义等价的问题变体,如何进行并行的一致性检查
- 对于频繁出现的问题或类似问题,使用缓存机制存储已生成的问题和其一致性评分,避免重复计算。
- 论文提到,当验证模型在某一领域表现更好时,可以给它更大的权重。在实际应用中权重的选择,如何实现自动选择一个较优的权重?
- 可以通过自动调整机制来确定最优权重,例如使用网格搜索或贝叶斯优化等方法寻找最佳权重值。