1. 研究背景、动机、主要贡献
1.1 研究背景
像Imagen、DALL·E 2和Parti等LLI模型,展示了出色的语义生成和组合能力,但它们在图像编辑方面存在控制力不足的问题。即使是对文本提示的轻微修改,生成的图像也可能完全不同。
1.2 存在问题(动机)
1.2.1 现有方案
现有方法通常要求用户手动遮罩要编辑的图像区域,只在遮罩区域进行图像修改,保持其他部分不变。这种方法虽有效,但操作复杂且容易忽略遮罩区域中的重要结构信息,因此不适合更精细的编辑,如修改特定物体的纹理。
1.3 主要贡献
本文提出了一种新的、直观的文本编辑方法,通过“Prompt-to-Prompt”操控,利用预训练的文本条件扩散模型来进行语义图像编辑。
关键思想是深入分析交叉注意力层,探索它们在控制生成图像中的语义作用。交叉注意力层的映射将图像像素与从文本提示中提取的单词进行绑定,作者发现这些映射包含丰富的语义关系,并且对生成图像起关键作用。
2. 论文提出的新方法
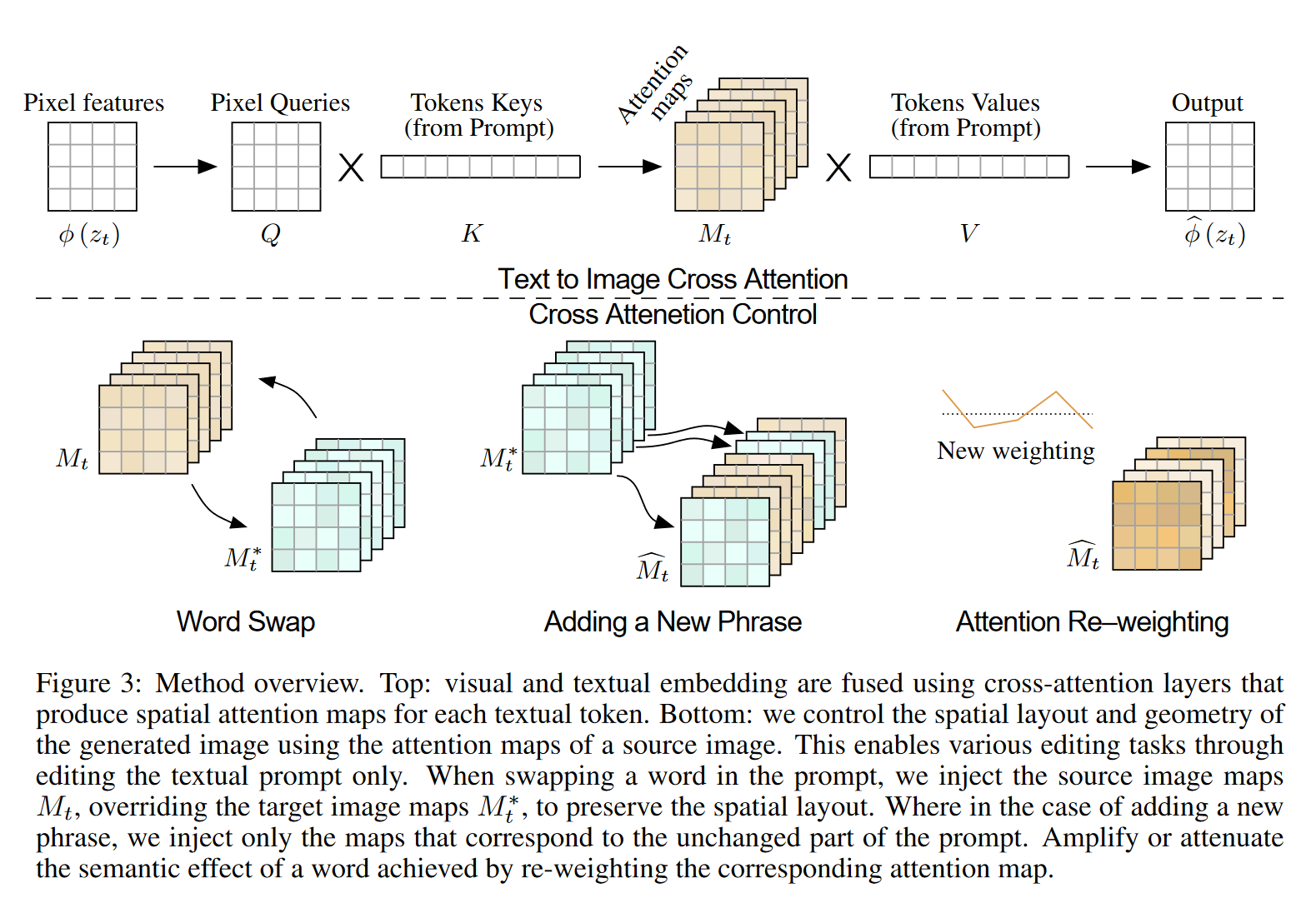
2.1 Cross-attention in text-conditioned Diffusion Models
本节主要讲利用交叉注意力机制,结合文本嵌入更新空间特征
基于Imagen文本引导合成模型,主要关注于文本到图像的扩散模型,而保持超分辨率过程不变。图像的构图和几何特征主要在64 × 64分辨率时决定。
步骤
- 每个扩散步骤 t 通过U形网络预测从噪声图像
和文本嵌入 中生成噪声 。最终生成的图像为 。 - 噪声图像的深层空间特征
被投影到查询矩阵 ,文本嵌入则被投影到键矩阵 和值矩阵 。 - 注意力图为
其中 d 是 keys and queries 的潜在投影维度。注意力图的元素 表示第 j 个令牌对第 i 个像素的权重。 - 最终的交叉注意力输出通过加权平均计算得出,即
,用于更新空间特征 。
- 每个扩散步骤 t 通过U形网络预测从噪声图像
Imagen 模型在每个扩散步骤的噪声预测中使用两种类型的注意力层: 交叉注意力层和混合注意力层 。只干预混合注意力的交叉注意力部分。也就是说,只有最后一个通道(引用文本标记)在混合注意力模块中被修改。
2.2 Controlling the Cross-attention
生成图像的空间布局和几何形状取决于交叉注意力图。
 像素更容易被描述它们的单词所吸引
像素更容易被描述它们的单词所吸引将来自原始提示
的注意力图 注入到修改后的提示 ,来生成编辑图像 ,使其既能依据新的提示进行操作,又能保留原始图像的构图。 整体思路
- 使用两个提示同时迭代原注意力图和修改后的注意力图。


- 使用两个提示同时迭代原注意力图和修改后的注意力图。
编辑操作
Word Swap
- a softer attention constrain
- 通过在早期步骤使用新提示的注意力图,而在后期步骤逐渐减少其影响,可以在保留原有构图的同时,给予生成图像必要的几何自由度,以适应新提示的内容。
- 通过为不同的令牌分配不同的注入时间戳和适当的处理方式(如重复或平均),模型能够更精细地控制生成图像的内容和结构。
- a softer attention constrain
Adding a New Phrase
例如:
仅对两个提示中的共同标记应用注意注入 使用对齐函数 A,它从目标提示
接收标记索引,并在 中输出相应的标记索引,如果不匹配则输出 None。 如果对齐函数 A 返回“none”,则使用新提示的注意力图
对应的值。 如果 A 返回一个有效索引,则使用原始提示的注意力图
中的相应值。
Attention Re–weighting
如
想调整蓬松的程度,可以调整其权重
原文链接:Prompt-to-Prompt Image Editing with Cross Attention Control