1. 研究背景、动机、主要贡献(Why)
1.1 研究背景
最近多模态大语言模型的发展使基础模型能够让用户使用图像作为输入进行交互。MLLM 的能力使其能够胜任各种视觉任务。
MLLM 也面临着“幻觉”问题。例如,产生不相关或无意义的响应,识别图像中不存在的颜色、数量和位置方面不准确的对象。
这一缺陷给 MLLM 成为值得信赖的助手的实际应用带来了巨大的风险。例如,在模型辅助自动驾驶场景中,这种对道路场景图像的误解可能会导致系统的错误判断并导致严重的交通事故。
1.2 存在问题(动机)
1.2.1 现有方案缺点
- 方法会产生大量的额外成本,包括用于训练的额外指令数据的注释预算、外部知识或模型的集成
1.3 主要贡献
- 无需引入任何外部数据、知识或额外的培训。
- 我们揭示了幻觉和过度信任模式的出现,并提出了一种配备回顾重新分配策略的基于惩罚的解码方法。
- 包括GPT 评估在内的广泛评估证明了OPERA 的卓越性能,它几乎可以作为缓解幻觉的免费午餐。
2. 论文提出的新方法(What)
2.1 制定 MLLM 的生成过程
2.1.1 输入构造
MLLM 的输入包含
- 图像
- MLLM 通常使用视觉编码器从原始图像中提取视觉标记
- 将视觉标记表示为
。这里N是视觉标记的长度,在大多数情况下它是固定的数字 - 并使用跨模态映射模块将它们映射到 LLM 的输入空间。
- 文本。
- 输入文本使用分词器进行分词
- 将其表示为
。
图像和文本标记连接起来作为最终的输入序列,我们将其表示为
2.1.2 模型前向传播
- MLLM 使用因果注意掩码以自回归方式进行训练,每个标记根据先前的标记预测其下一个标记。
Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。
h 是 MLLM 最后一层的输出隐藏状态,包含了模型对输入序列的编码和理解
假设有一个 MLLM 模型,输入一个句子 "The weather is nice today.",模型经过处理后会有一个隐藏状态 “h”,这个隐藏状态包含了模型对整个句子的编码表示。
假设 “h” 是一个包含 512 维度的向量,其中每个维度可能对应于句子中的不同语义特征。
- MLLM 使用词汇头
来投影隐藏状态 h 并获取下一个标记预测的 logits(或概率)
词汇头,通常是指用于将隐藏状态映射为词汇表中每个单词的概率分布的神经网络层。这个层通常是一个全连接层,其输出是一个向量,每个元素对应于词汇表中一个单词的概率。这个输出向量可以通过 softmax 函数转换为概率分布,用于生成下一个可能的标记。
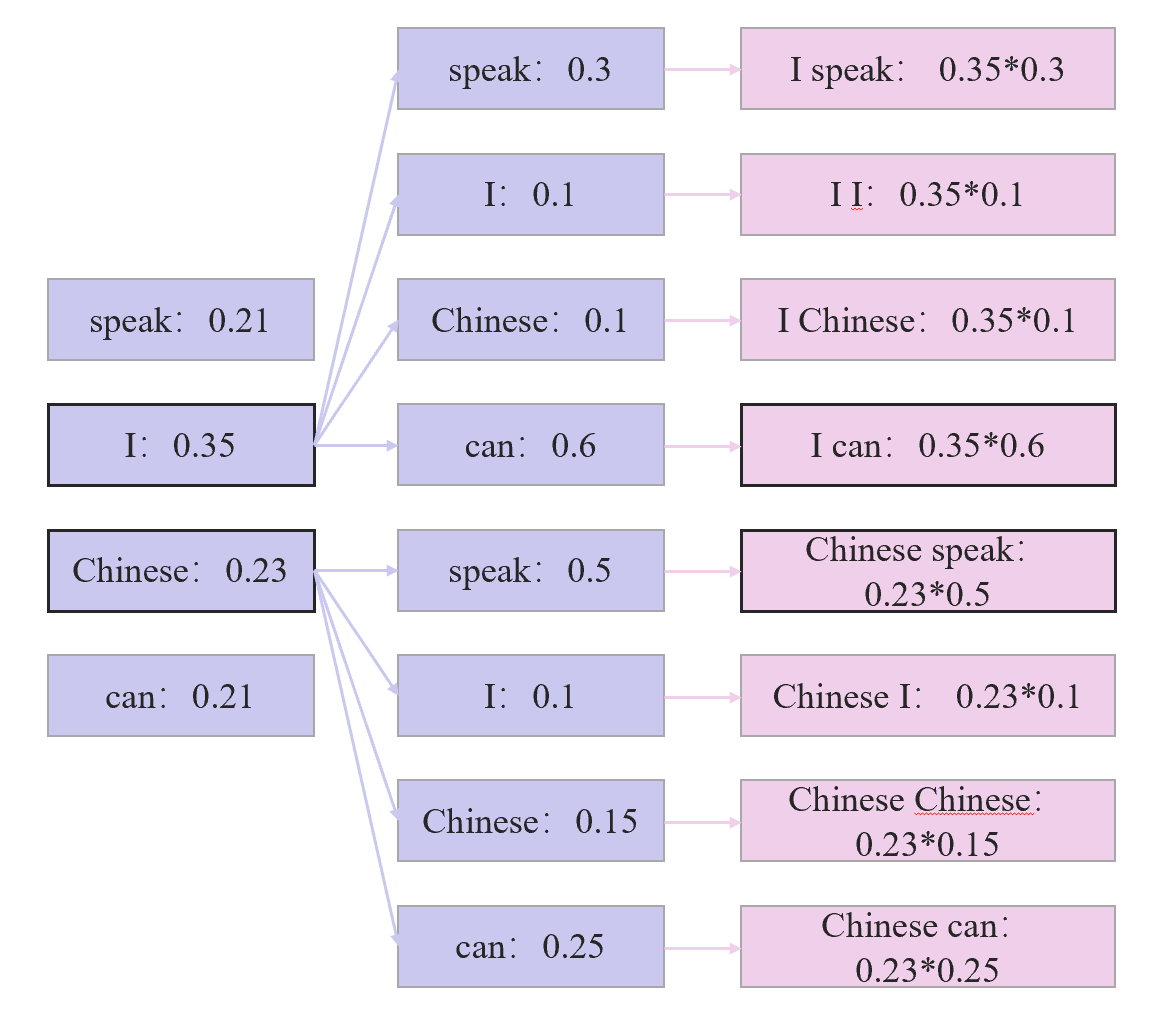
假设我们有一个掩码语言模型(MLLM),输入是一个经过编码后的序列的隐藏状态 “h”,我们想要预测下一个单词。
假设我们的词汇表中有以下单词:[“speak”, “I”, “Chinese”, “can”]。
现在,我们将隐藏状态 “h” 经过词汇头的处理,得到一个包含四个元素的向量,分别对应于词汇表中的每个单词。这个向量可以表示为 [0.1, 0.6, 0.2, 0.1]。
通过 softmax 函数,我们可以将这个向量转换为概率分布。经过 softmax 处理后,我们得到的概率分布如下所示:
- “speak”:
- “I”:
- “Chinese”:
- “can”:
2.1.3 解码
OPERA 基于 Beam Search
这是一种基于累积分数的解码策略。简而言之,对于给定的束大小
2.2 过度信任惩罚
2.2.1 前置背景
在浅层中,标签词从演示中收集信息以形成语义表示以进行更深入的处理,而深层则从标签词中提取并利用这些信息来制定最终预测。
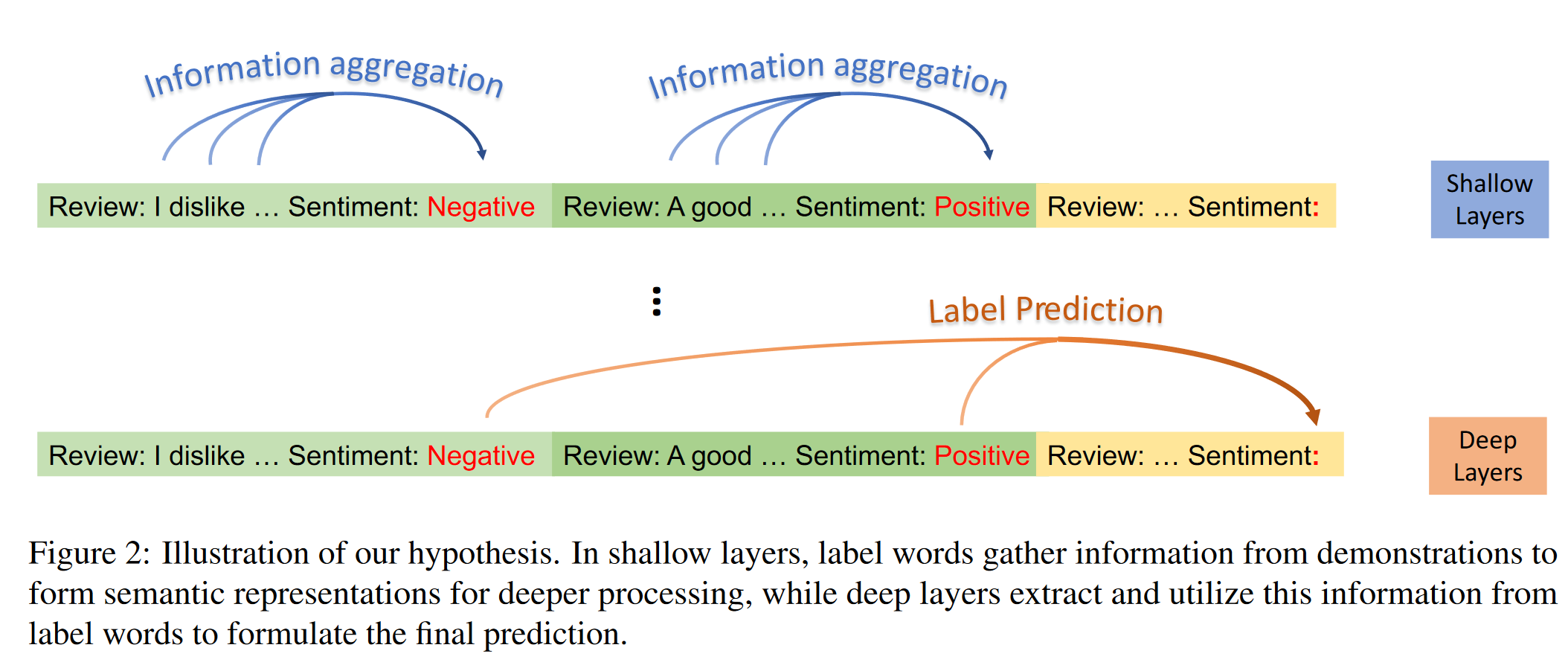
可视化自注意力图。
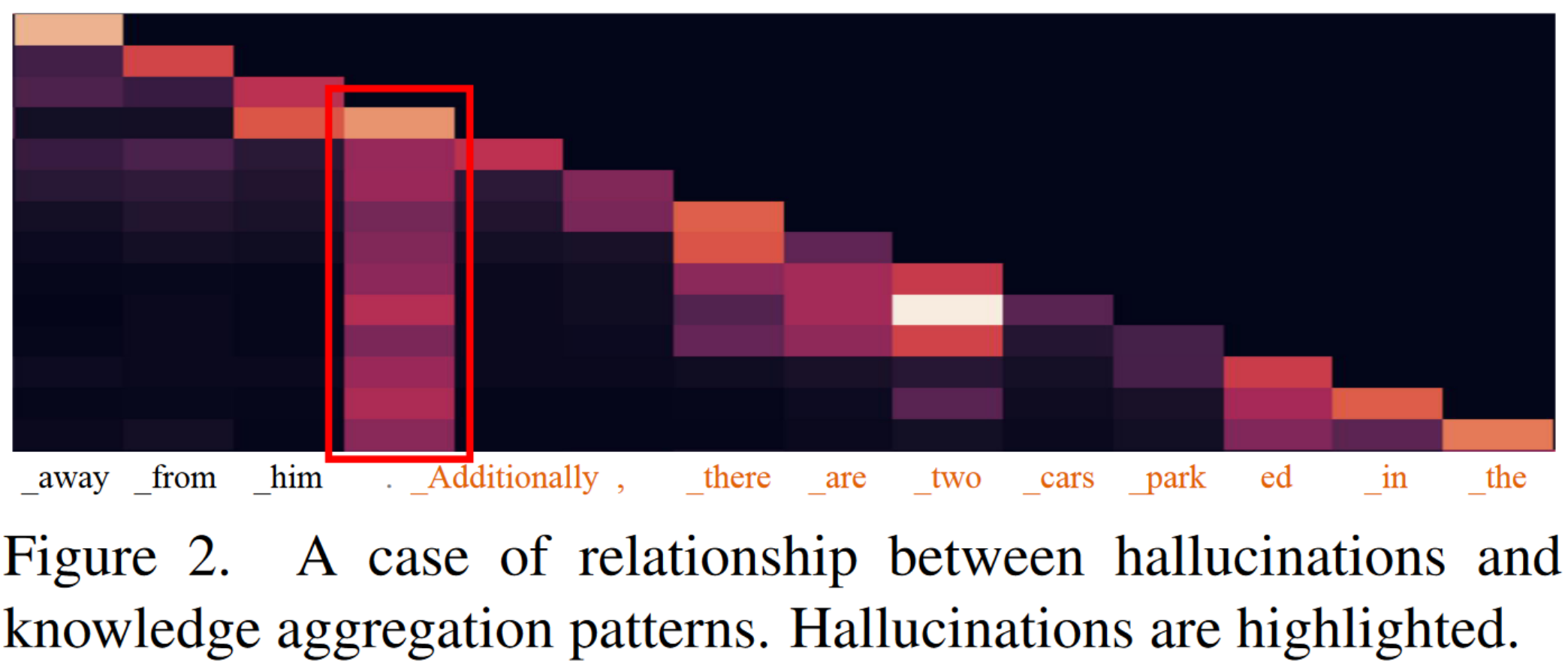
- 非对角线元素表示模型在生成当前输出标记时对其他输入位置的关注程度。
- 柱状注意力模式通常表现在缺乏大量信息的标记上,例如句号或引号。
- 柱状注意力模式的令牌通常拥有有限的信息,但却对所有后续令牌的预测产生显着影响。
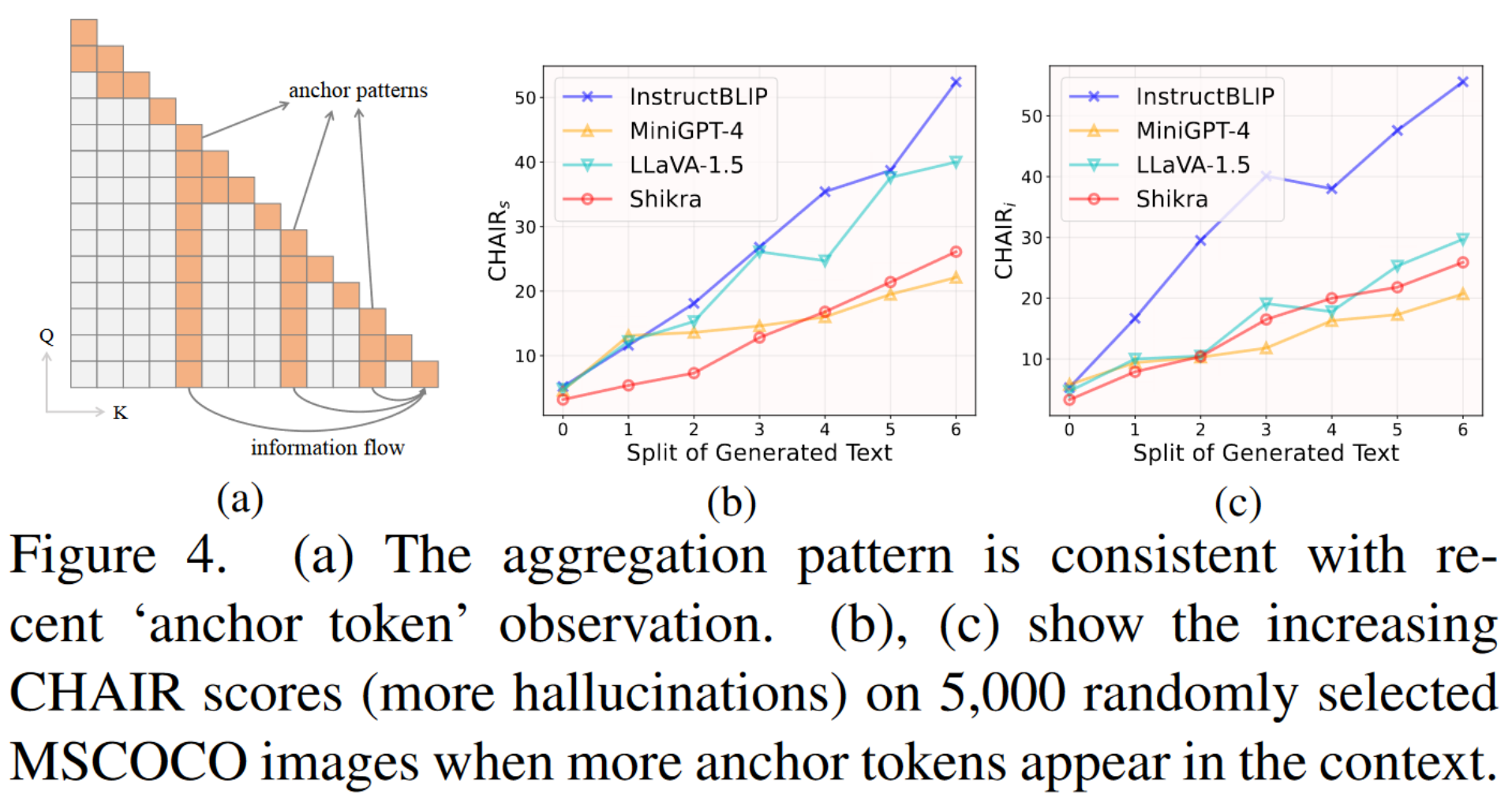
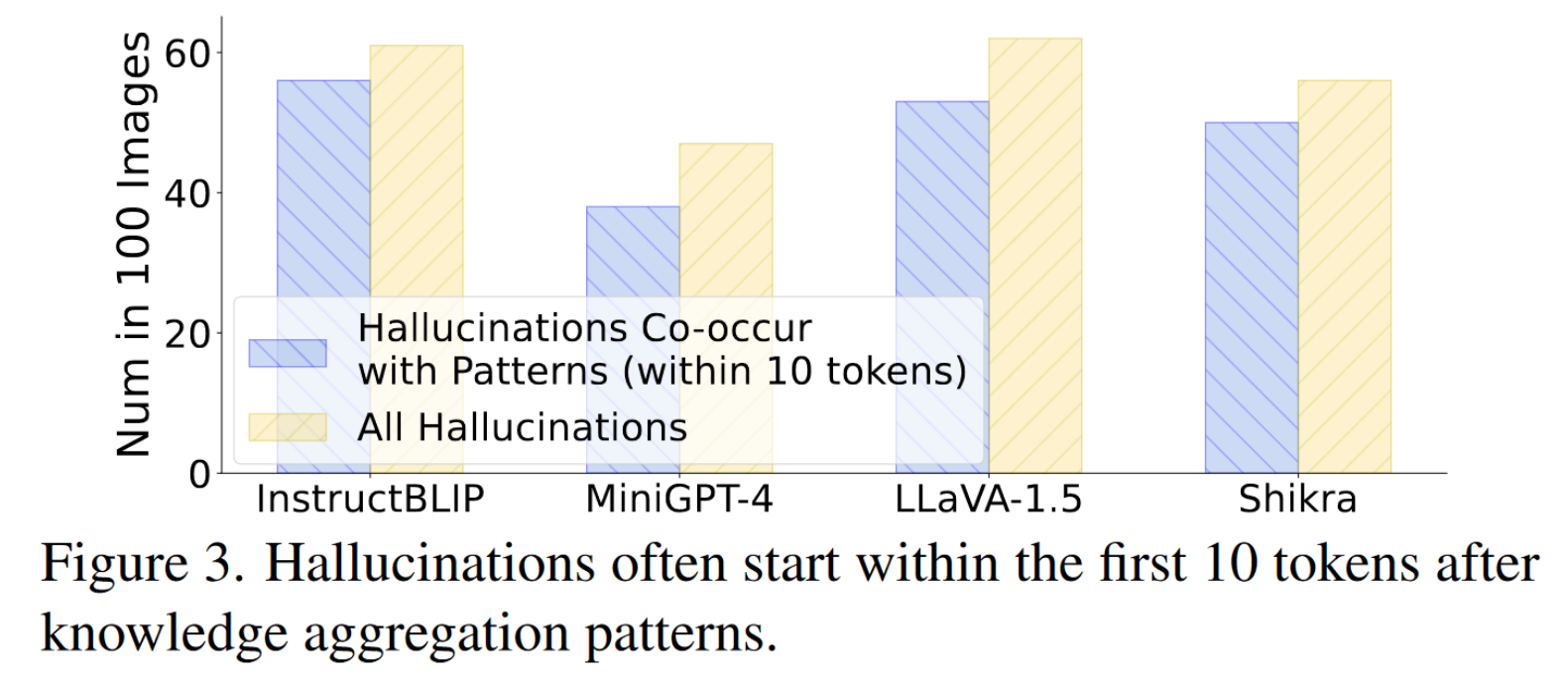
(a) 聚合模式与最近的“锚定令牌”观察结果一致。 (b)、(c) 显示当上下文中出现更多锚标记时,5,000 张随机选择的 MSCOCO 图像上的 CHAIR 分数(更多幻觉)不断增加。
知识聚合后面的内容大部分都带有推理或者幻觉
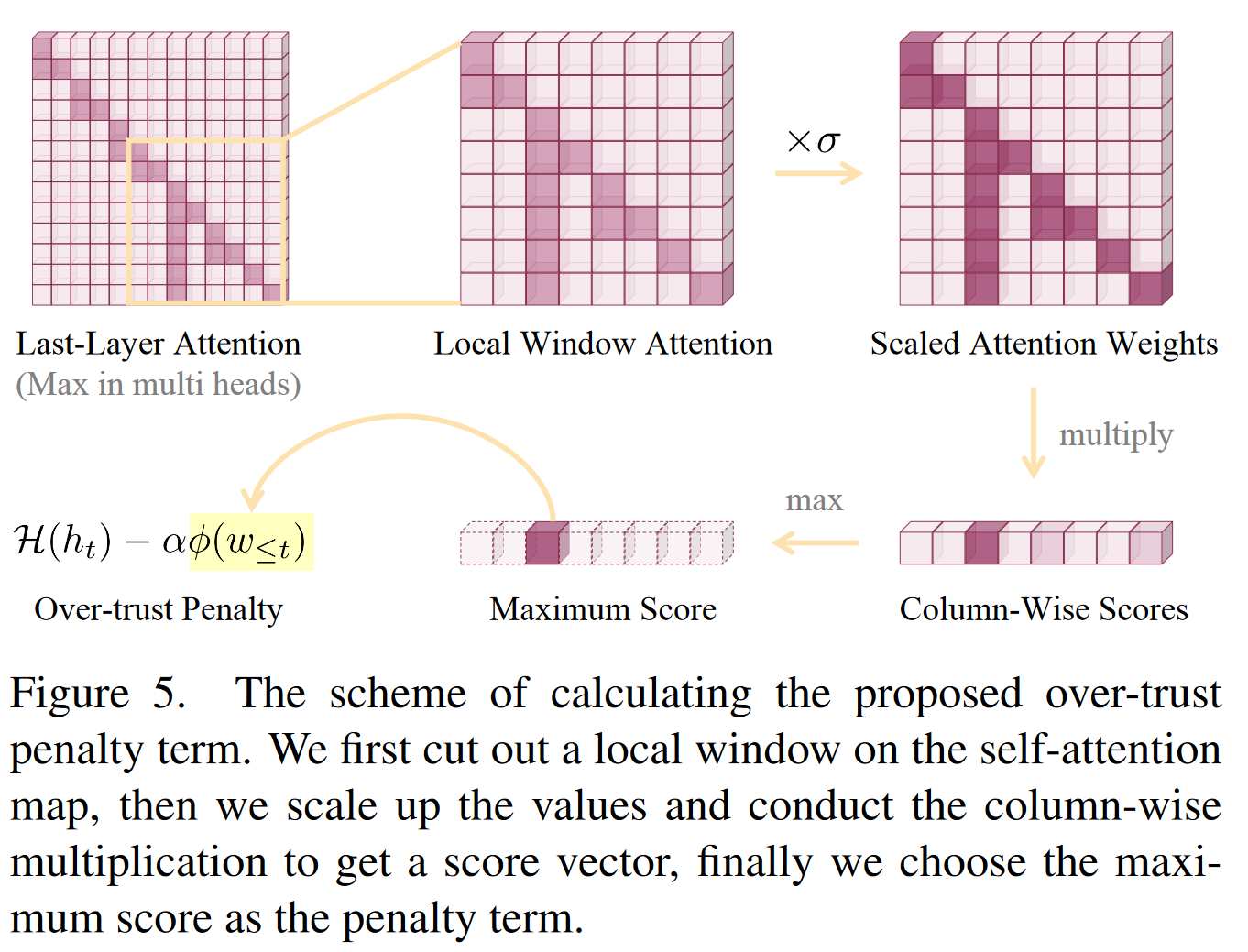
2.2.2 具体方法
幻觉和知识聚合模式之间存在高概率的共存。然而,这种模式具有显着的滞后性,即,当对应的令牌被解码时,不能立即观察到模式,而是在后续的几个令牌被解码之后,幻觉可能已经发生。为了应对滞后现象,我们提出了“过度信任惩罚”。
- 当前生成的序列
- 下一个标志词预测的因果自注意力权重
causual self-attention weights - 考虑在局部窗口中收集所有先前的自注意力权重来表征知识模式,即局部窗口注意力定义为
其中 k 表示我们在注意力图上裁剪的局部窗口的大小,表示第 j 个标记分配给第 i 个标记的注意力权重 - 预处理,用零填充矩阵的上三角形并放大注意力值
其中为零, 是可配置的比例因子。 - 对注意力矩阵的下三角进行列乘法,并获得列分数向量。
直观上,分数越大表示相应位置存在的模式越强。因此,我们选择列向得分向量的最大值作为知识聚合模式的特征。
2.3 回顾-分配策略
通常,惩罚项能够惩罚具有知识聚合模式的候选者,并鼓励其他候选者被预测。
但也有少数情况是,所有候选者都受到惩罚,而幻觉已经出现。
这个案例促使我们重新思考这种聚合模式的起源:它是由前几个后续标记过度信任摘要标记引起的,而惩罚未能纠正它们。因此,一个直观而激进的想法是,如果我们能够排除导致幻觉的标记并在摘要标记之后重新选择正确的前几个标记,则该模式将大大削弱。
回顾分配策略。
当解码过程遇到知识聚合模式并且幻觉不可避免时,它回滚到摘要令牌并选择除了之前选择的候选者之外的其他候选者用于下一个令牌预测。根据经验,解码回顾的条件被设计为对应于几个连续标记的列分数中最大值的位置重叠,其中我们手动将阈值计数设置为r。与不同模型之间变化的最大值不同,位置计数是一个更加稳健和通用的决策指标。
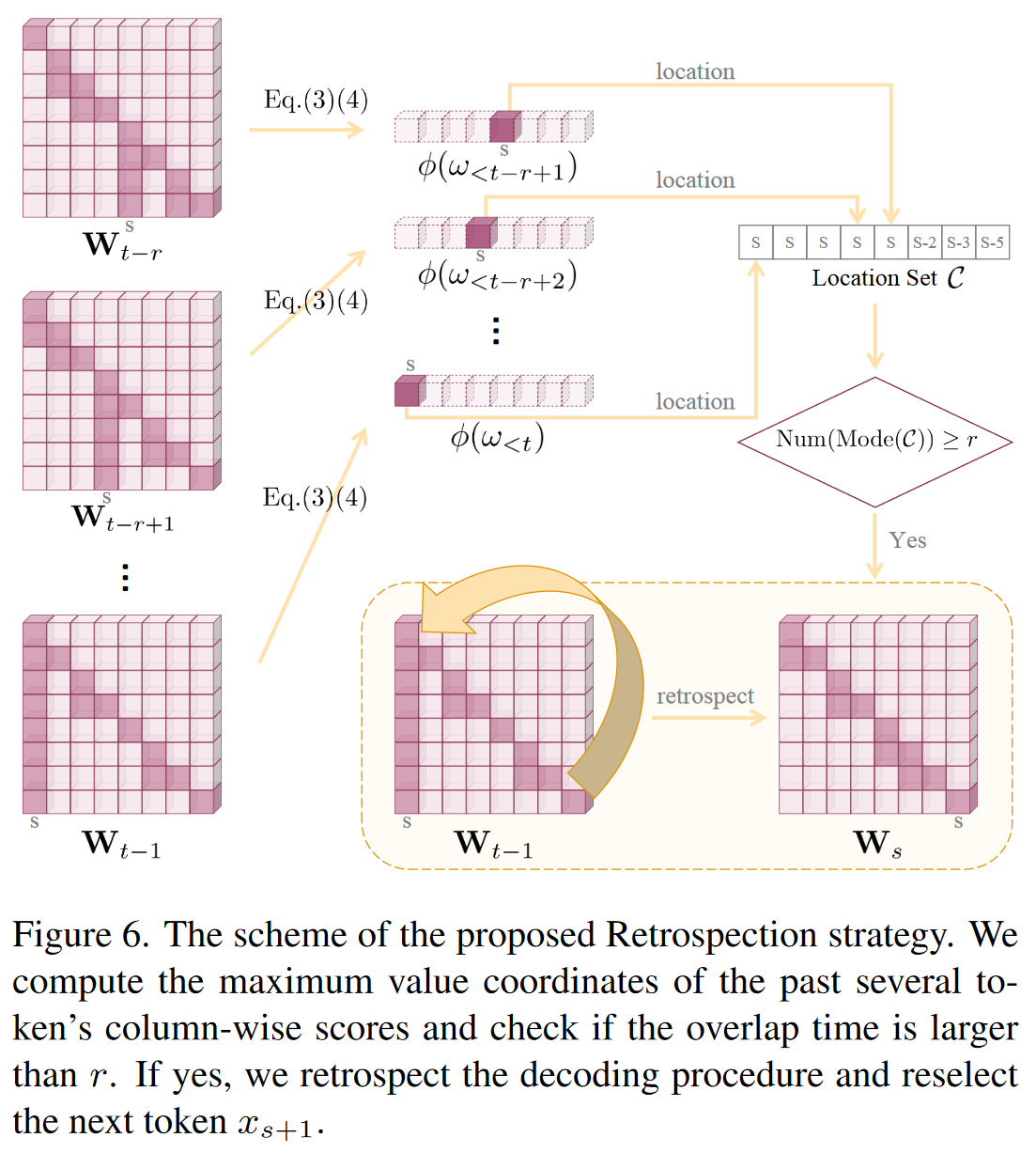
手动指定回滚位置 s 必须是单调不递减的。另外,我们配置了回滚的最大时间
3. 论文方法的理论分析或实验评估方法与效果(How)
- 不同方法、不同模型,在图像级别和句子级别的幻觉表现
- 对 MSCOCO 数据集(Microsoft COCO,通过收集包含自然环境中常见物体的复杂日常场景的图像来实现的) 进行 CHAIR 评估,该数据集包含超过 300,000 张图像和 80 个带注释的对象。具体来说,我们在验证集中随机选择 500 张图像,并查询不同的 MLLM 模型,并提示
“请详细描述该图像”。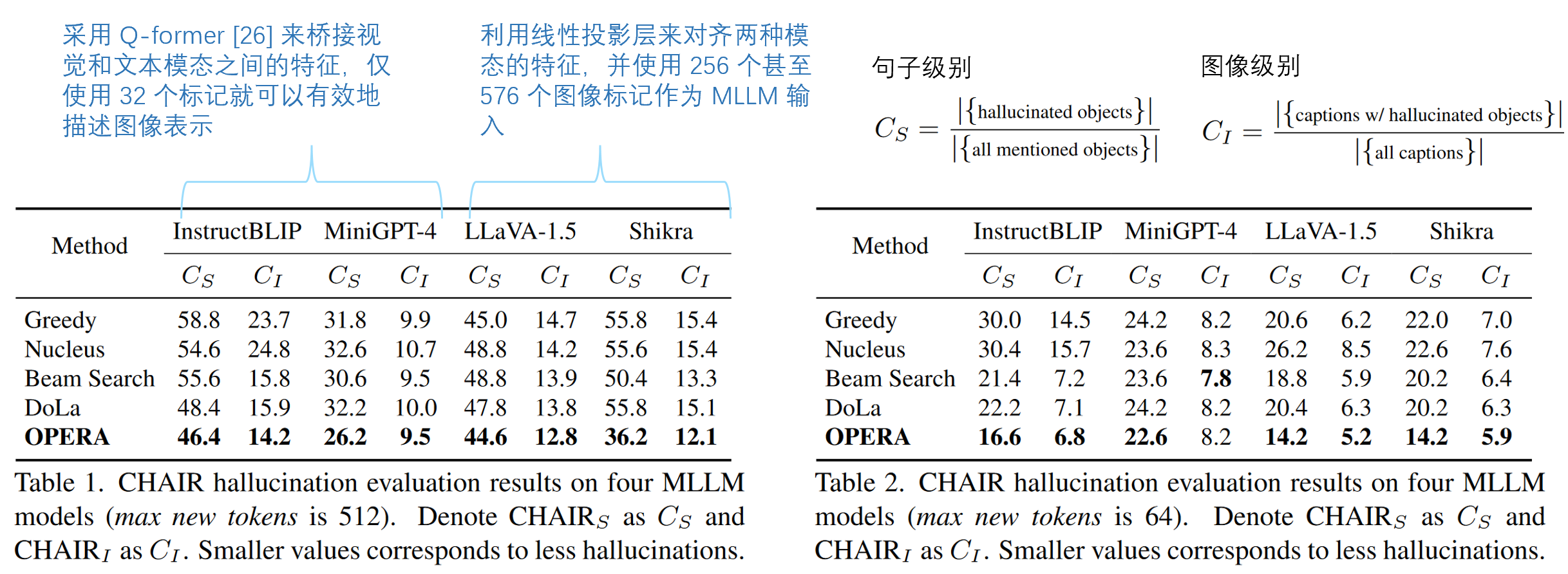
- 对 MSCOCO 数据集(Microsoft COCO,通过收集包含自然环境中常见物体的复杂日常场景的图像来实现的) 进行 CHAIR 评估,该数据集包含超过 300,000 张图像和 80 个带注释的对象。具体来说,我们在验证集中随机选择 500 张图像,并查询不同的 MLLM 模型,并提示
- 不同方法、不同模型,在不同方面的表现(GPT辅助幻觉评估)
- OPERA确实帮助模型部分克服了由于其偏见或过度信任问题而导致的幻觉问题。我们还注意到,OPERA 以某种方式稍微减少了 MLLM 输出序列的长度,这可能是由于那些额外的幻觉内容的减少所致。
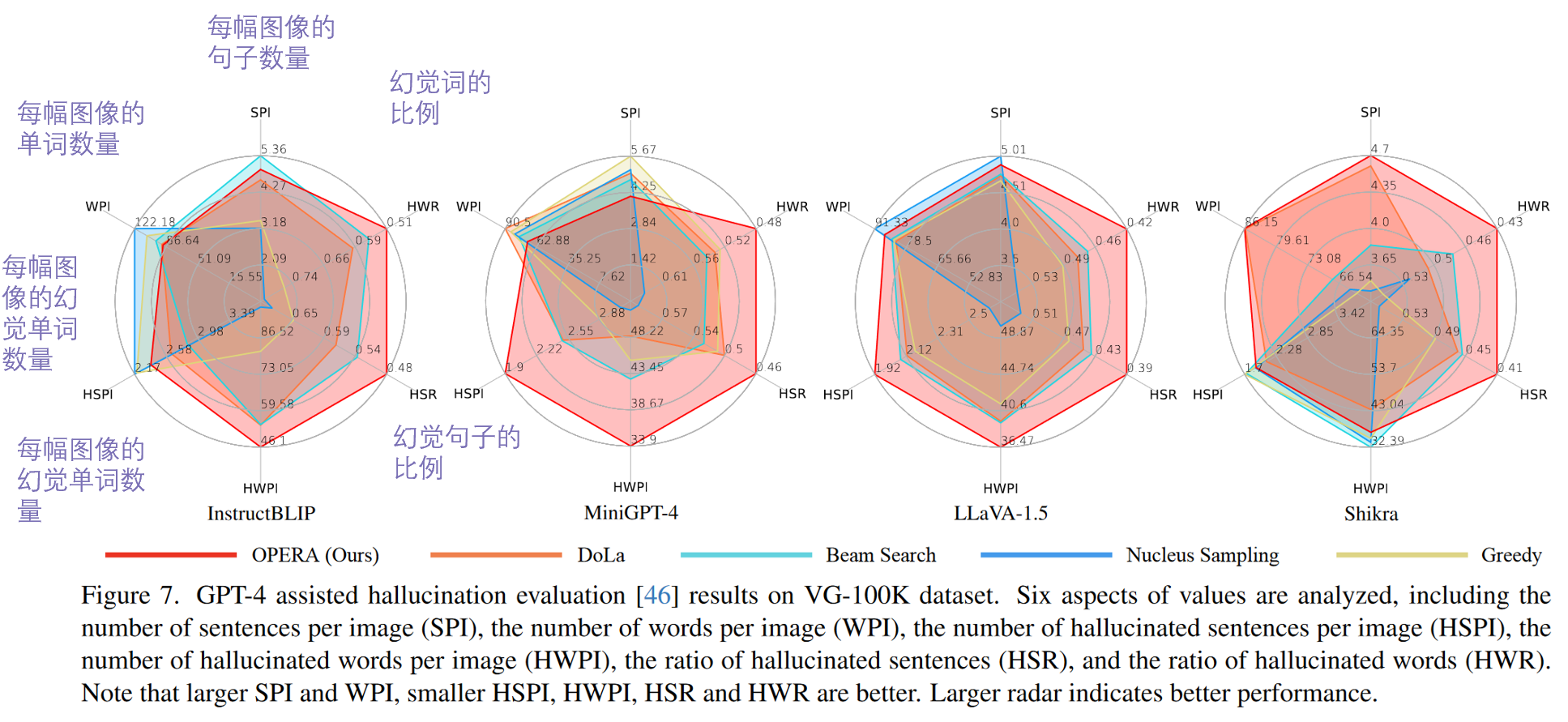
- OPERA确实帮助模型部分克服了由于其偏见或过度信任问题而导致的幻觉问题。我们还注意到,OPERA 以某种方式稍微减少了 MLLM 输出序列的长度,这可能是由于那些额外的幻觉内容的减少所致。
- Beam Search和OPERA、不同模型,在正确性和详细性的表现(GPT辅助幻觉评估)
- 不同方法、不同模型,在随机、流行和对抗性的表现
- 不同方法,在 LLaVA-1.5 7B 模型上,生成文本质量(语法、流畅度和自然度)的表现(GPT辅助幻觉评估)
- 不同方法,在流行的 MLLM 基准上的性能的表现
4. 论文优缺点、局限性、借鉴性
优点:
之前接触的一些解决幻觉的方法,很多都是通过给模型对应的指令,让其自动调整,而本文却从更为底层的入手
从更为根本的角度揭示了幻觉的出现原因(过度信任)
验证方面做的很全面。
缺点:
- 图像标注
改进:
- 假设序列
已经在摘要标记 处呈现了知识聚合模式,我们打算将解码过程回滚到序列
手动指定回滚位置 s 必须是单调不递减的- 可以稍微向前回滚一点。比如s-k