1 研究背景、动机、主要贡献
1.1 存在问题(动机)
自回归生成由于图像令牌数量庞大,效率低下;而非自回归方法(如MIM)则在性能上有限,无法与先进的扩散模型相比。
1.2 主要贡献
增强的变换器架构:结合多模态和单模态变换器层,提高MIM的训练效率和性能,能够有效捕捉语言与视觉之间的交互。
先进的位置编码与动态采样条件
- 使用 RoPE 以保持高分辨率图像的细节
- 引入动态遮蔽率作为采样条件,改善图像生成的细节和整体质量。
- 高质量的训练数据
- 微条件:将原始图像分辨率、裁剪坐标和人类偏好评分作为微条件,可以大大增强高分辨率美学训练期间模型的稳定性。
- 特征压缩层:压缩与解压缩,最终生成高分辨率图像。
2 论文提出的新方法
2.1 MOTIVATION
扩散模型和自回归模型的差异使得集成这两种模态变得复杂,强调了开发创新方法的必要性,以缩小它们之间的差距。
非自回归的遮蔽图像建模(MIM)技术,例如MaskGIT和MUSE,展示了高效图像生成的潜力。然而,MIM面临两大关键限制:
- 分辨率限制:当前的MIM方法最多只能生成512 × 512像素的图像,这限制了其广泛采用和进一步发展的可能性,尤其是随着T2I社区逐渐将1024 × 1024像素作为标准。
- 性能差距:性能未能达到领先的扩散模型(如SDXL)的水平。尤其在图像质量、复杂细节和概念表达领域表现不佳。
本研究旨在
- 使MIM能够高效地生成高分辨率图像(如1024 × 1024)
- 同时缩小与顶级扩散模型之间的差距,并确保适合消费级硬件的计算效率。
- 通过Meissonic模型,目标是推动MIM方法的边界,将其带到T2I合成的前沿。
2.2 MODEL ARCHITECTURE
- 矢量量化图像编码器和解码器:采用VQ-VAE模型,将原始图像像素转换为离散语义令牌。此模型由编码器、解码器和量化层组成,使用学习到的字典将输入图像映射为离散令牌序列。
实现中,a downsampling ratio of f = 16 and a codebook size of 8192 - 灵活高效的文本编码器:与以往工作中常用的大型语言模型编码器(如T5XXL1或LLaMa)不同,我们采用CLIP模型中的单个文本编码器,并对其进行微调以优化T2I性能。这种设计在显著减少GPU内存和计算成本的同时,未降低视觉质量。
- 多模态Transformer骨干:
- 模型采用多模态Transformer框架,结合采样参数和旋转位置嵌入(RoPE)进行空间信息编码,并引入特征压缩层以有效处理有大量离散token的高分辨率生成。(将嵌入特征从 64 × 64 压缩到 32 × 32,经过transformer后解压缩为 64 × 64 )
- 在分布式训练期间实现梯度裁剪和检查点重新加载
- 并将 QK-Norm 层集成到架构中
- 多样的微条件:为了增强生成性能,模型加入了额外的条件,如原始图像分辨率、裁剪坐标和人类偏好评分。这些条件被转换为正弦嵌入,并作为额外的通道连接到文本编码器的最终池化隐藏状态中。
- 掩码策略
- 采用余弦调度的可变掩蔽比。与自回归模型按固定toke顺序学习条件分布不同,Meissonic通过随机掩码和可变比率来学习任意子集token的分布,这使模型具有更高的灵活性。
- 这种灵活性支持了并行采样策略,并使模型能够实现多种零样本图像编辑功能。
- 采用余弦调度的可变掩蔽比。与自回归模型按固定toke顺序学习条件分布不同,Meissonic通过随机掩码和可变比率来学习任意子集token的分布,这使模型具有更高的灵活性。
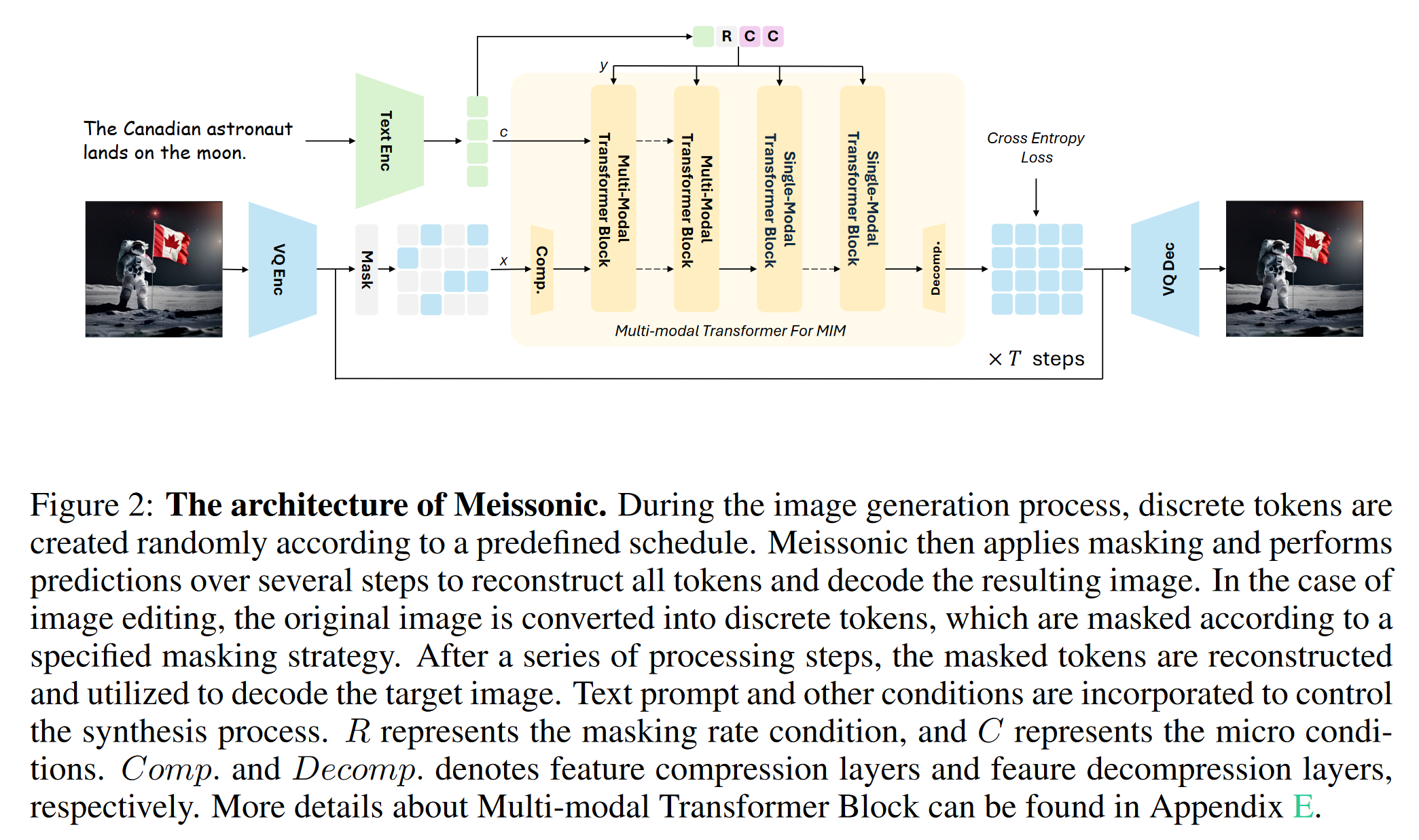
中间的过程是类似于扩散模型的, other conditions的加入是通过
1 | norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb) |
2.3 MULTI-MODAL TRANSFORMER FOR MASKED IMAGE MODELING
为MIM的专门设计
- Rotary Position Embeddings:RoPE在LLM中表现出色。由于使用高质量 image tokenizer 将图像转换为离散标记,原始 1D RoPE 已经可以取得良好的结果。这种 1D RoPE 有助于从 256 × 256 阶段到 512 × 512 阶段的无缝过渡,同时增强模型的生成性能。
- Deeper Model with Single-modal Transformer:
- 虽然多模态变换器表现良好,但实验表明,减少多模态块并采用单模态块配置在训练过程中更加稳定且计算效率更高。
- 模型的前半部分使用多模态变换器块,后半部分转为单模态变换器块,找到的最佳块比例大约为1:2。
- Micro Conditions with Human Preference Score:引入了
- 原始图像分辨率:有效地帮助模型隐式过滤掉低质量数据并学习高质量、高分辨率数据的属性。
- 裁剪坐标:提高训练稳定性,可能是由于增强了裁剪区域与语义条件之间的一致性。
- 人类偏好分数
- Feature Compression Layers:
- 主张在微调阶段集成精简的特征压缩层,以促进高效的高分辨率生成的学习过程。
- 通过在 Transformer 的前后引入基于2D卷积的特征压缩层,模型可以在处理之前压缩特征图,之后再进行解压缩,从而有效解决效率与分辨率过渡的挑战。
2.4 TRAINING DETAILS
Meissonic使用MODEL ARCHITECTURE中的三个模块构建。训练过程中采用CFG和交叉熵损失,并分为三个分辨率阶段进行训练,使用公共数据集和自定义数据。
- 阶段1:训练分辨率为 256×256 的模型,批量大小为 2048,训练 10 万步。从大量数据中理解基本概念。
- 阶段2:训练分辨率为 512×512 的模型,批量大小为 512,继续训练 10 万步。使用长提示对齐文本和图像。
- 阶段3:训练分辨率为 1024×1024 的模型,批量大小为 256,训练 42000 步。掌握特征压缩以生成更高分辨率。
- 阶段4:微调模型,不冻结文本编码器,并引入人类偏好分数。完善高分辨率美学图像的生成。
Meissonic 的训练时间约为 48 个 H100 GPU 天
3 论文实验评估方法与效果
3.1 QUANTATIVE COMPARISON
传统的图像生成评估指标(如FID和CLIP分数)对于视觉美学的相关性有限。因此,作者使用了更具代表性的人类偏好分数v2(HPSv2)、GenEval、多维人类偏好分数(MPS)等评价标准来衡量模型的表现。
Meissonic经过优化后具有10亿参数,可以在8GB的显存上高效运行,使推理和微调都变得方便。
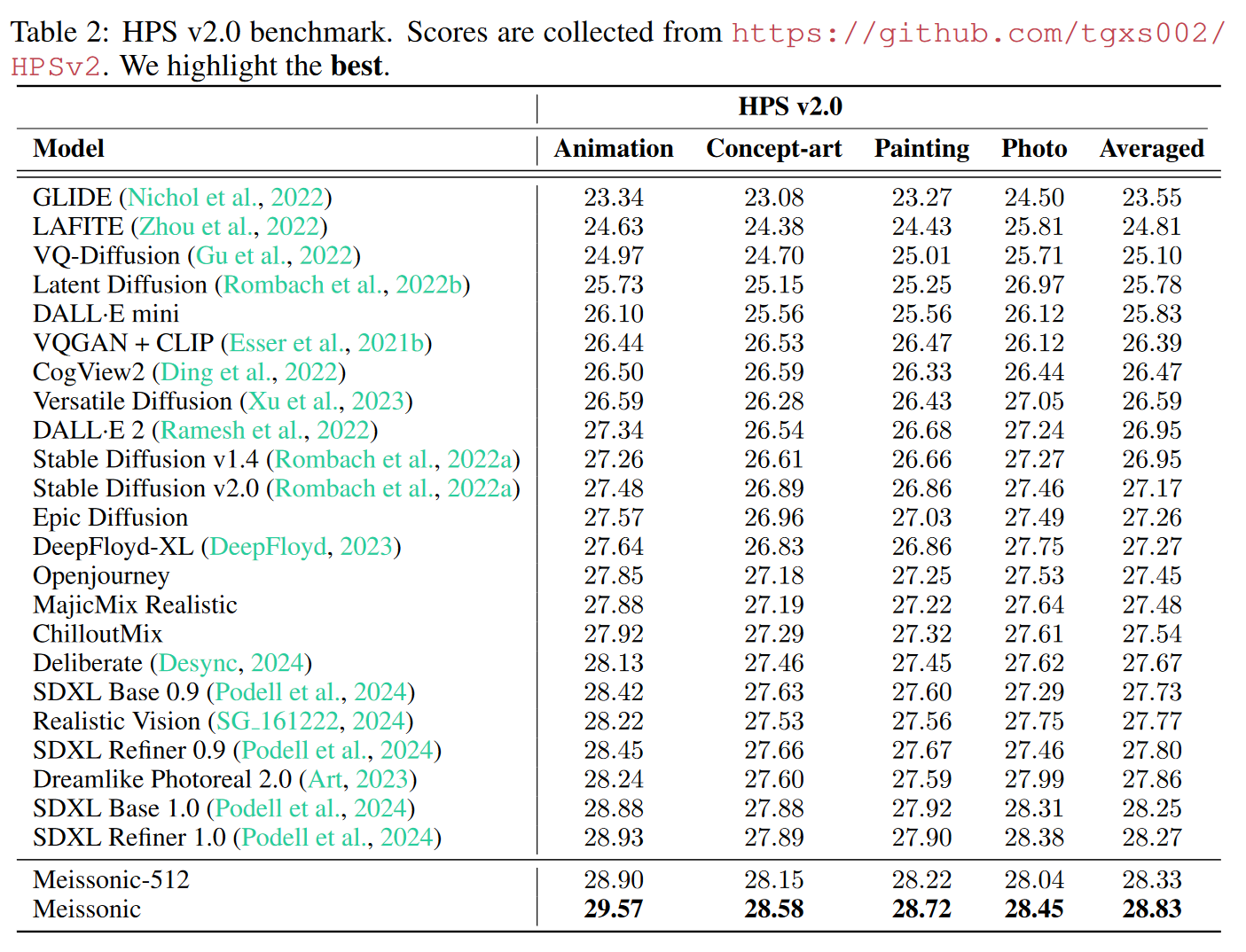
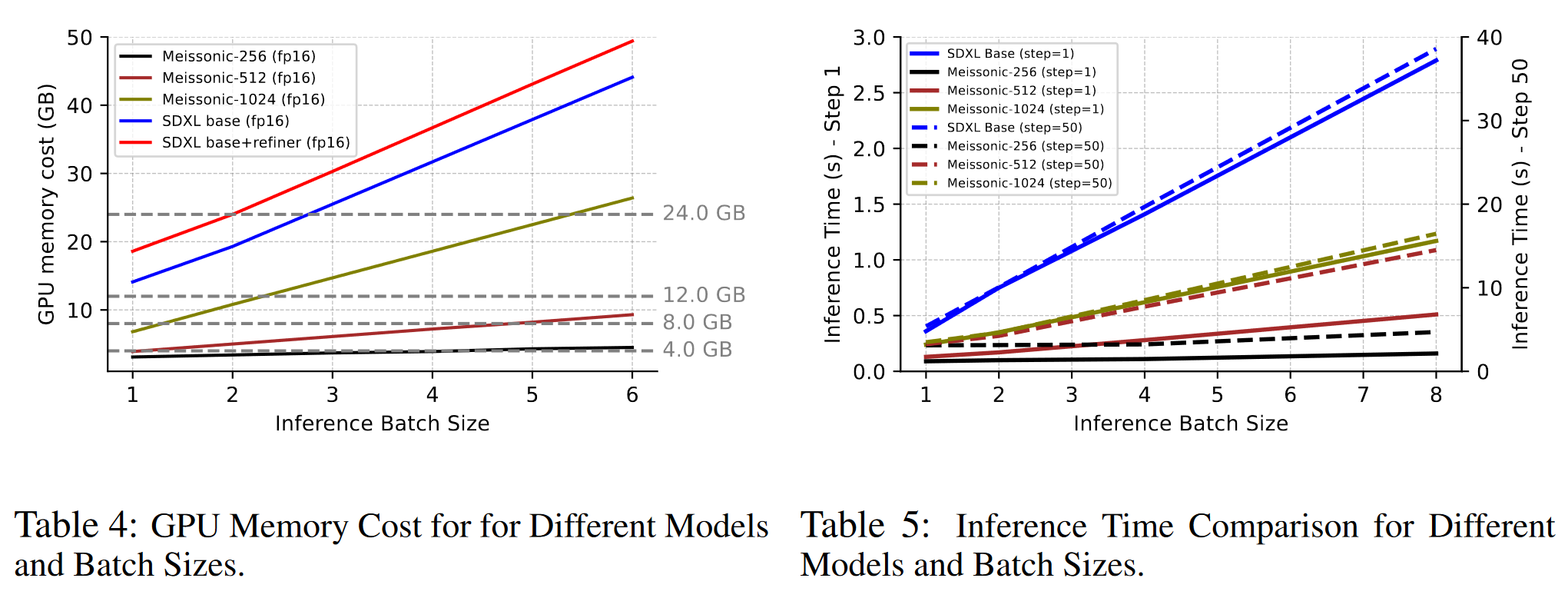
3.2 ZERO-SHOT IMAGE-TO-IMAGE EDITING
- 图像编辑任务:使用EMU-Edit数据集,模型需要完成七类操作、
- 背景更改
- 全面的图像修改
- 风格更改
- 对象删除
- 对象添加
- 局部修改
- 颜色和纹理的变化。
- 内置图像编辑
- mask-free
- mask-guided
- Meissonic 无需对图像编辑特定数据或指令数据集进行任何训练或微调即可实现这一性能。

4 论文优点
优点:
- Meissonic 仅有10亿参数,却在高分辨率、美观的图像生成任务中表现优异。能够在消费级的GPU上运行(如8GB的显卡)
- 可以应用在移动设备等有限计算资源的场景中,为用户提供离线生成图像的能力。