1 研究背景、动机、主要贡献
1.1 研究背景
近年来,大型文本生成图像扩散模型(如GLIDE、DALL-E 2、Stable Diffusion等)取得了显著进展,能够根据文本提示生成高保真图像。然而,生成理想的图像通常需要复杂的提示词工程,而且文本在表达复杂场景和概念时不够直观。因此,提出图像提示作为替代方案,以增强生成能力。
1.2 存在问题(动机)
- 微调模型消除原始文本生成能力,且需大量计算资源。
- 微调后的模型难以复用,无法在基于相同基础模型的自定义模型中直接应用图像提示功能。
- 与现有的结构控制工具(如ControlNet)不兼容,限制了灵活性。
- 替换文本编码器的方法虽然简单,但无法同时支持图像提示和文本提示,且生成图像的质量和泛化能力较差。
1.3 主要贡献
- 提出了IP-Adapter,一种轻量级适配器,采用解耦的交叉注意力机制,将文本和图像特征分别处理,保留原有的文本生成功能。
- IP-Adapter仅需22M参数,能够实现与完全微调的图像提示模型相当甚至更优的生成效果。
- IP-Adapter可复用,能够泛化至基于同一基础模型微调的其他自定义模型,并与结构控制工具兼容,实现灵活的图像生成任务。
- 支持文本提示和图像提示的多模态图像生成。
2 论文提出的新方法
3.1 Prelimiaries
Stable Diffusion
3.2 Image Prompt Adapter
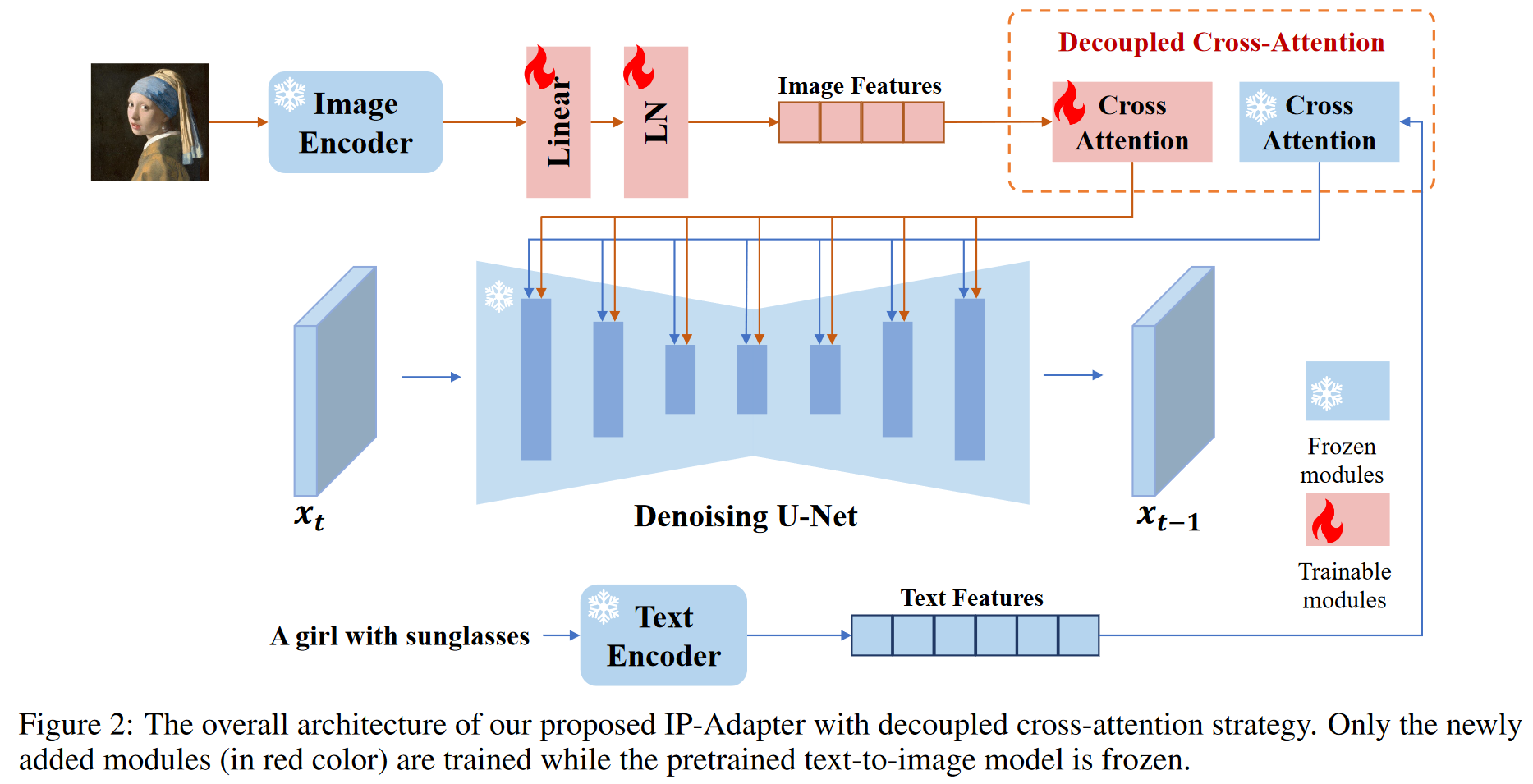
现有的方法难以达到那些为图像提示专门精调或从头训练的模型的性能,原因:
- 现有方法通常将图像特征与文本特征简单地拼接,然后直接输入到冻结的交叉注意力层。图像特征无法有效嵌入到预训练模型中。
- 这种拼接方式无法让扩散模型充分捕捉图像提示中的细粒度特征,导致生成图像的质量和细节欠佳。
本文提出了一种解耦的交叉注意策略,其中图像特征由新添加的交叉注意层嵌入。
- IP-Adapter设计:
- 图像编码器:使用预训练的CLIP图像编码器从图像提示中提取图像特征。
- CLIP是一种多模态模型,通过对比学习在包含大量图像-文本对的数据集上进行训练。它能够生成与图像描述高度匹配的全局图像嵌入,并代表图像的内容和风格。
- 在训练阶段,CLIP编码器是冻结的,其参数不再更新。
- 为了更有效地使用全局图像嵌入,论文引入了一个小型可训练的投影网络,将嵌入分解为N个特征序列(本研究中N=4),并且这些特征的维度与预训练扩散模型中的文本特征维度相同。
- 投影网络包括一个线性层和层归一化,用于处理图像嵌入。
- 图像编码器:使用预训练的CLIP图像编码器从图像提示中提取图像特征。
- 具有解耦交叉注意力的自适应模块:为每一个原有的交叉注意力层添加新的交叉注意力层来处理图像特征。
- 原始SD:
- 为原始UNet模型中的每个交叉注意层添加一个新的交叉注意层以插入图像特征。
为了加速收敛,和 由 和 初始化 - 然后,我们简单地将图像交叉注意力的输出添加到文本交叉注意力的输出上
- 原始SD:
- 训练和推理
- 在训练过程中,模型只优化IP-Adapter,而保持预训练的扩散模型参数不变。
- 通过在训练时随机丢弃图像条件,可以在推理时应用无分类器引导。
- 推理时可以通过调整图像条件的权重因子来控制图像提示的影响。
- 在训练过程中,模型只优化IP-Adapter,而保持预训练的扩散模型参数不变。
3 论文方法的实验评估方法与效果
3.1 Experimental Setup
3.1.1 Training Data
为了训练IP-Adapter,构建了一个多模态数据集,包括来自两个开源数据集(LAION-2B和COYO-700M)约1000万个文本-图像对。
3.1.2 Implementation Details
- 实验基于SD v1.5版本,使用OpenCLIP ViT-H/14作为图像编码器。
- SD模型包含16个交叉注意力层,并为每个交叉注意力层添加一个新的图像交叉注意力层。
- IP-Adapter的总可训练参数约为2200万,设计较为轻量。
- 使用HuggingFace diffusers库实现IP-Adapter,并采用DeepSpeed ZeRO-2进行快速训练。
- 在单台配备8个V100 GPU的机器上进行训练,步数为100万,每个GPU的批量大小为8。
- 使用AdamW优化器,固定学习率为0.0001,权重衰减为0.01。
- 在训练过程中,将图像的最短边调整为512,然后中心裁剪为512 × 512分辨率。
- 为了启用无条件分类器自由指导,在训练阶段以0.05的概率单独丢弃文本和图像,并以0.05的概率同时丢弃文本和图像。
- 推理阶段采用DDIM采样器,步数为50,指导尺度设置为7.5;当仅使用图像提示时,文本提示为空。
3.2 Comparison with Existing Methods
将 IP-Adapter 与其他现有的带有图像提示的生成方法进行比较
- 从头训练的方法:包括open unCLIP、Kandinsky-2-1和Versatile Diffusion。
- 从文本到图像模型进行微调:选择 SD Image Variations 和SD unCLIP。
- 适配器方法:与T2I-Adapter的风格适配器、Uni-ControlNet的全局控制器、ControlNet Shuffle、ControlNet Reference-only和SeeCoder进行比较。
3.2.1 Quantitative Comparison
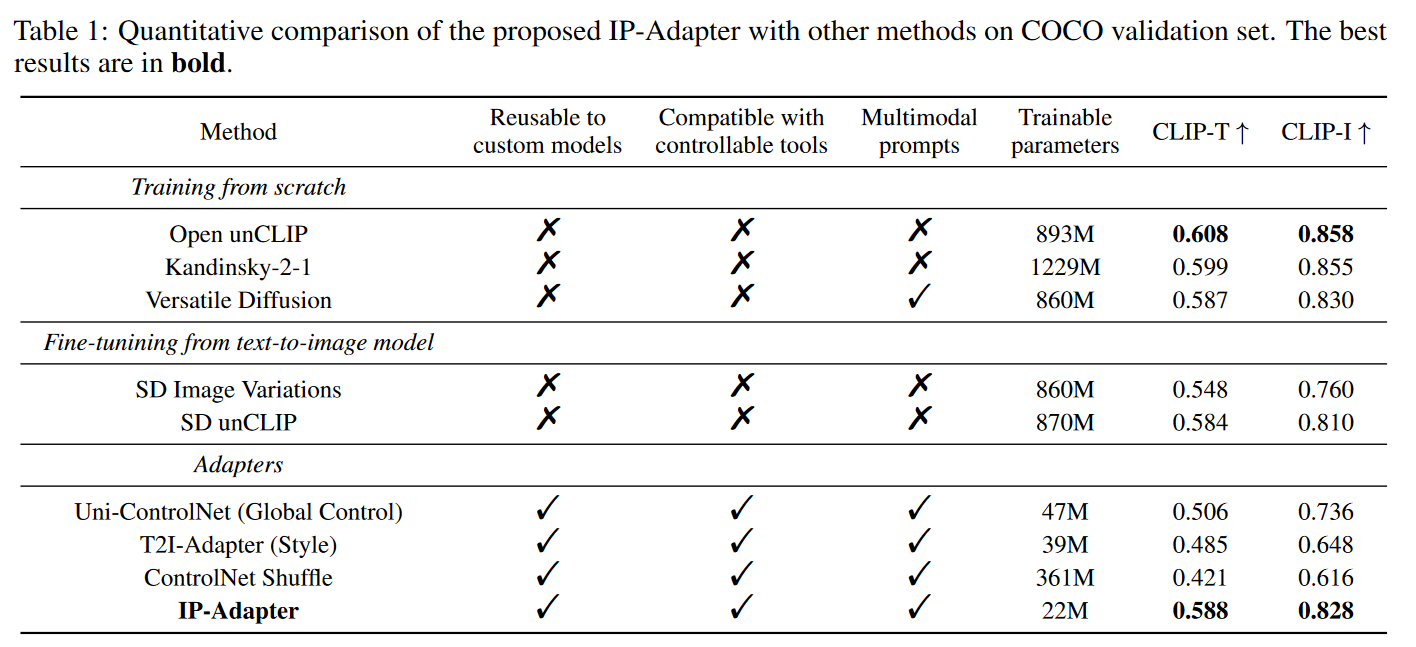
使用COCO2017验证集(包含5000张带有字幕的图像)进行定量评估。为了公平比较,对每个样本生成4张基于图像提示的图像,生成20000张图像。采用下面两个指标
- CLIP-I:生成图像与图像提示在CLIP图像嵌入中的相似度。
- CLIP-T:生成图像与图像提示字幕的CLIPScore。
3.2.2 Qualitative Comparison
从各种类型和风格的图像中随机生成4个样本,并选择每种方法中表现最佳的一个。
3.3 More Results
3.3.1 Generalizable to Custom Models
IP-Adapter可以在训练阶段冻结原始扩散模型,因此可推广到从SD v1.5微调的自定义模型。一旦训练完成,IP-Adapter可以直接应用于社区模型,并能生成与这些模型风格相符的图像。
3.3.2 Structure Control
IP-Adapter完全兼容现有的可控工具,可以生成带有图像提示和附加条件的可控图像。
3.3.3 Image-to-Image and Inpainting
可以实现文本引导/图像引导的图像到图像和修复。
3.3.4 Multimodal Prompts
对于完全微调的图像提示模型,原始的文本到图像能力几乎丧失。使用IP-Adapter可以生成包括图像提示和文本提示的多模态提示图像。
3.4 Ablation Study
3.4.1 Importance of Decoupled Cross-Attention
通过比较没有解耦交叉注意力的简单适配器和IP-Adapter,验证了解耦交叉注意力策略的有效性。
3.4.2 Comparison of Fine-grained Features and Global Features
利用CLIP图像编码器的全局图像嵌入,可能会丢失参考图像的一些信息。因此,设计了一个基于细粒度特征的IP-Adapter,提取CLIP图像编码器倒数第二层的网格特征,并通过轻量变换模型学习特征。
虽然具有更细粒度特征的IP-Adapter可以生成与图像提示更加一致的图像,但它也可以学习空间结构信息,这可能会减少生成图像的多样性。
4 论文优点、局限性
优点:
- 基于解耦交叉注意力,为预训练的文本到图像扩散模型实现图像提示功能。
- IP-Adapter在经过一次训练后,可以直接与基于相同基础模型的自定义模型及现有的结构可控工具集成。
- 多模态图像生成
局限性:
只能生成内容和风格与参考图像相似的图像。无法像某些现有方法(例如 Textual Inversion 和 DreamBooth )那样生成与给定图像主题高度一致的图像。
原文链接:IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models