1. 研究背景、动机、主要贡献
传统的扩散模型在像素空间操作,导致计算开销巨大,训练和推理都非常耗时。特别是高分辨率图像合成需要大量的GPU资源,限制了模型的广泛应用。
为了降低计算复杂度,作者提出在预训练的自动编码器的潜在空间中进行扩散模型的训练。使LDM能够在保持视觉细节的同时大大减少计算量。
此外,作者引入了交叉注意力机制,使模型能够进行灵活的条件生成任务,如文本生成图像或边界框生成图像。
主要贡献
比以前的工作提供更忠实和详细的重建
计算复杂度降低
高分辨率图像合成
2. 论文提出的新方法
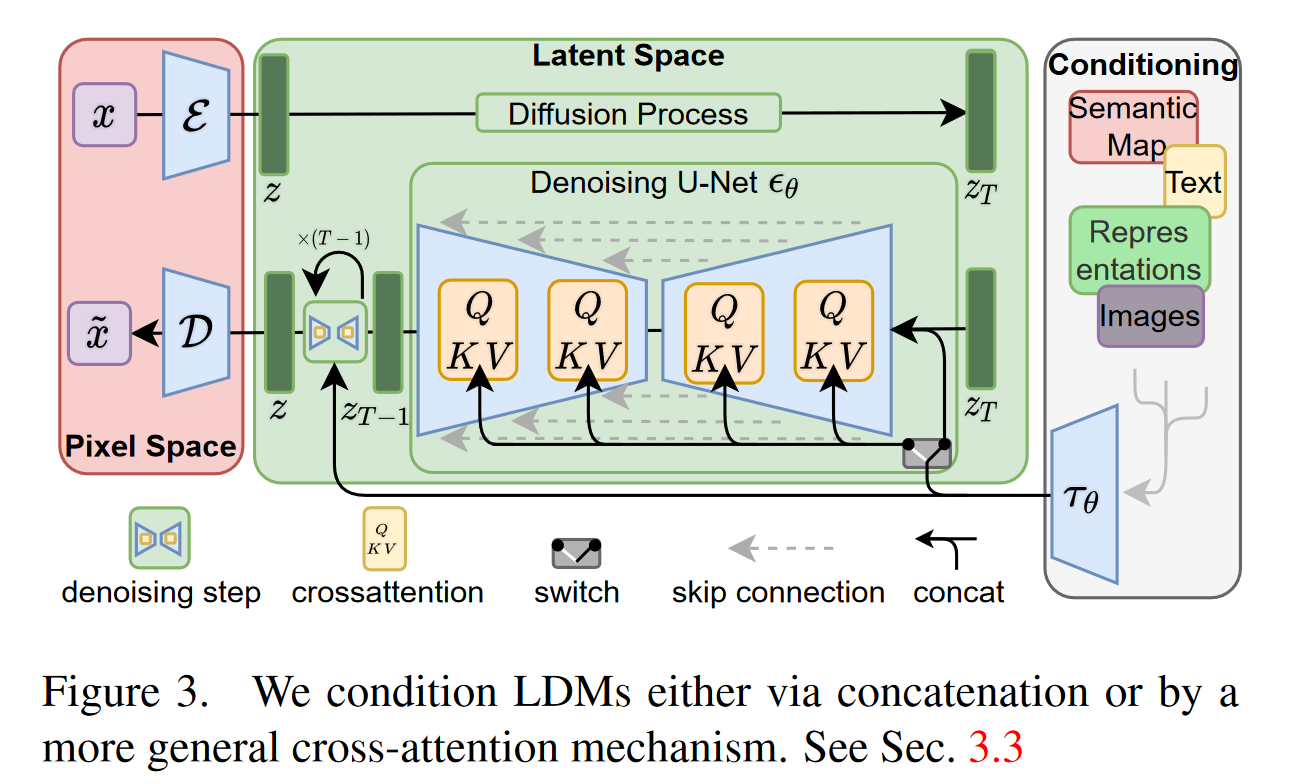
Perceptual Image Compression
感知压缩模型基于之前的工作,由一个基于感知损失和基于patch的对抗性目标相结合训练的自动编码器组成。与依赖像素级损失(如L2或L1)不同,感知损失和对抗性目标可以确保生成的图像在整体结构和局部细节上都与真实图像一致,从而避免模糊,保持高质量的重建效果。
- 感知损失(perceptual loss):感知损失通过衡量重建图像与原始图像在高层次特征空间中的差异,来指导模型生成更逼真的图像。它使用预训练的神经网络(如VGG)提取图像的高层次特征,而不是单纯比较像素级的差异。这样可以更好地保持图像的整体视觉质量和语义一致性。
- 基于patch的对抗性目标(patch-based adversarial objective):这是通过生成对抗网络(GAN)来进一步提高图像的局部质量。在这种方法中,判别器会评估图像的局部区域(patch)是否真实,从而迫使生成模型生成更加逼真的局部细节。这种局部对抗性目标可以有效防止重建图像中出现模糊或失真的问题。
- 自动编码器由编码器和解码器两部分组成。编码器负责将输入的高维图像压缩为低维的潜在表示,解码器则从潜在表示中重建出原始图像。
编码器
作者为避免潜在空间中出现高方差,采用了两种正则化策略:KL正则化和VQ正则化。通过这两种方法,模型能够更稳定地工作,并且可以在保持图像细节的同时实现较轻的压缩。与之前的将潜在空间表示成一维的自回归方法不同,作者保留了潜在空间的二维结构,这意味着潜在表示保留了空间信息(如图像的高度和宽度),而不是将图像压缩成一维序列。从而更好地保存了图像的空间信息,并且生成效果更加逼真、细腻。
KL正则化(KL-reg.):
- 这种方法引入了Kullback-Leibler(KL)散度作为正则化手段。KL散度通常用于衡量两个概率分布之间的差异。在这里,它的作用是将学习到的潜在表示 z 的分布拉近到标准正态分布(mean = 0,variance = 1),类似于变分自编码器(VAE)。
- 通过在潜在空间上引入KL惩罚,模型可以避免潜在表示的方差过大,保持潜在空间的紧凑性。
VQ正则化(VQ-reg.):
- VQ正则化基于向量量化(Vector Quantization, VQ)技术,这种技术在VQ-VAE和VQGAN中广泛应用。它通过离散化潜在空间中的连续表示,使得模型更好地捕捉离散的语义信息。
- 在这里,VQ层被集成到解码器中,通过将潜在表示限制在特定的离散值上来实现正则化。
- VQGAN(Vector Quantized Generative Adversarial Network)是基于VQ的生成模型,作者的设计与VQGAN类似,但VQ层直接融入了解码器结构。
Latent Diffusion Models
相比传统的像素空间,这种低维的潜在空间去除了感知不重要的细节,保留了关键的语义信息,使生成模型能够更加专注于生成重要的图像部分。模型采用UNet架构并通过优化重加权的变分下界,能够在保持高效性的同时生成高质量的图像。
重加权变分下界:在这个模型中,生成过程通过优化一个重加权的变分下界来实现。这种重加权机制允许模型将注意力集中在图像中感知上最重要的部分。损失函数的形式如下:
其中,模型在时间 t 上根据潜在表示 进行去噪。 时间条件的UNet:模型的主干是一个时间条件的UNet。UNet是一种适合图像生成的神经网络架构,通过卷积操作捕捉图像的局部特征,并逐步恢复图像细节。在这个模型中,UNet根据输入的噪声和时间步 t 进行去噪。
在训练时,前向过程是固定的。一旦潜在表示
通过编码器 E 得到,模型可以通过单次通过解码器 D 将潜在表示解码回图像。这种高效的推理过程使得生成图像更加快速。
Conditioning Mechanisms
扩散模型可以通过引入条件输入来进行灵活的图像生成。本文的方法通过交叉注意力机制结合不同模态的输入(如文本、语义图等),并使用特定领域编码器
- 条件生成模型
- 条件分布 p(z∣y):扩散模型可以建模条件分布 p(z∣y)。条件生成意味着模型可以通过给定的输入条件来生成特定的输出。例如,给定某个文本描述,模型可以生成与该描述相关的图像。
- 条件去噪自编码器
:噪声输入 、时间步 t,还引入条件信息 y。通过条件去噪自编码器,模型能够在去噪过程中利用 y 来指导生成的方向。y 可以是文本、语义地图、或者其他形式的条件输入。
- Beyond Class Labels
- 以往的扩散模型主要通过类别标签(class labels)或者模糊图像变体(blurred variants of the input image)进行条件生成。然而,将扩散模型与其他条件输入形式结合,目前仍然是一个研究较少的领域。
- 本文提出将扩散模型与交叉注意力机制(cross-attention mechanism)结合,扩展了模型的条件生成能力。
- 交叉注意力机制
- UNet架构中的交叉注意力:通过交叉注意力机制增强其底层 UNet 主干网。具体地,通过交叉注意力层来处理多种输入模态(如语言提示),从而使模型在不同的输入条件下生成相应的图像。
- 处理条件输入 y
- 为了处理不同类型的条件输入
y(如文本、图像或语义图),模型引入了一个特定领域编码器
。该编码器将输入 y 投射到一个中间表示 ,表示为维度为 的矩阵。 - 通过交叉注意力机制,模型能够将条件输入 y
的中间表示用
传递给UNet的中间层。具体的注意力机制计算如下: - Q 是对UNet中间表示
进行线性变换后的查询矩阵。 - K 和 V 是通过将条件输入
进行线性变换后的键和值矩阵。 - 注意力机制通过对 Q 和 K 的点积进行加权,从 V 中提取相关信息,从而在生成过程中融入条件信息。
- Q 是对UNet中间表示
- 为了处理不同类型的条件输入
y(如文本、图像或语义图),模型引入了一个特定领域编码器
- 条件扩散模型的训练
- 损失函数变为:
- 损失函数衡量模型预测的去噪结果
与真实的噪声 之间的差异。 和 是联合优化的,所以模型不仅学习去噪的过程,还学习如何从条件输入中提取有用信息。 可以由特定领域的专家进行参数化
- 损失函数变为:
3. 论文方法的理论分析或实验评估方法与效果
3.1 感知压缩的权衡分析
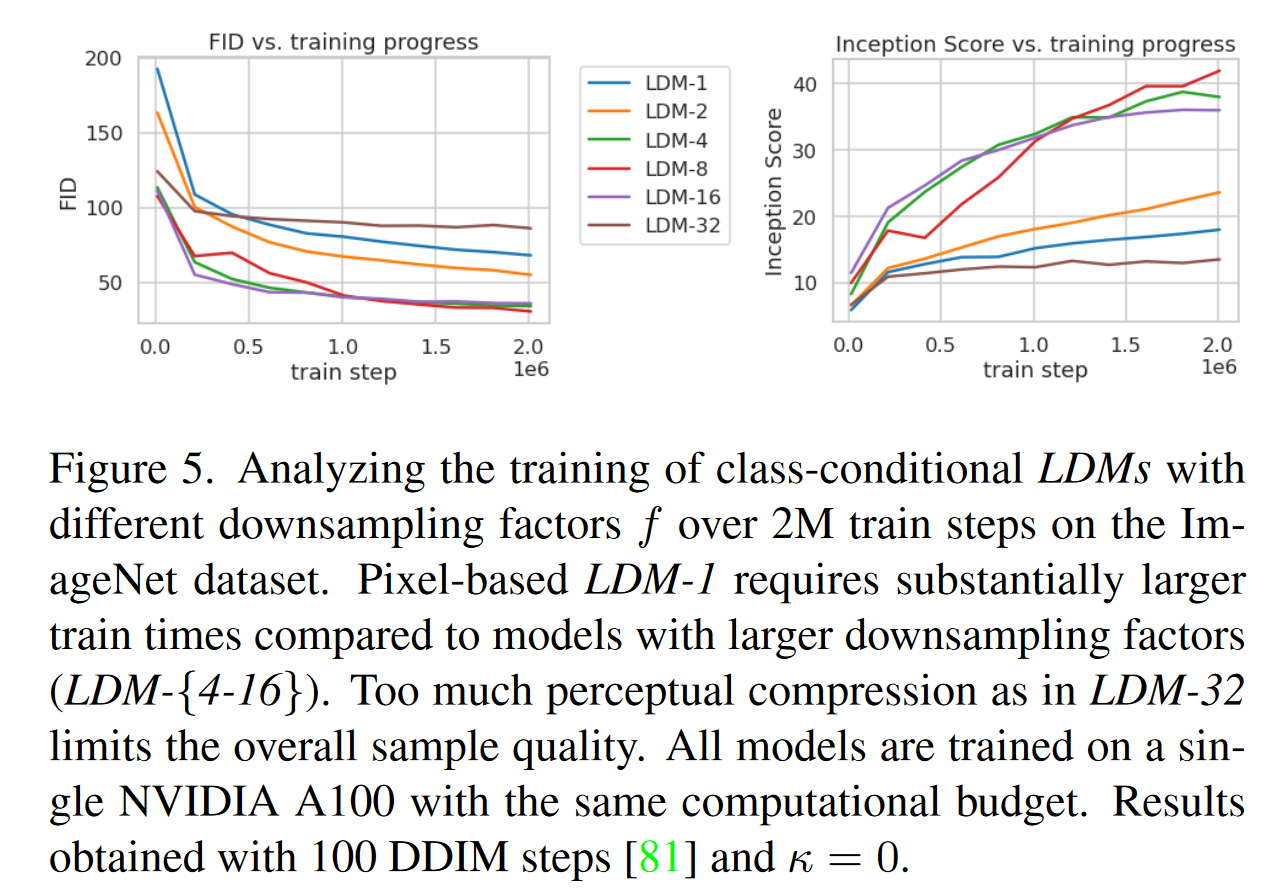
- 探讨不同下采样因子 f 对模型生成质量和计算效率的影响,分别在
进行实验。 - 较小的压缩因子(如 LDM-1)需要更多的训练时间,而较大的压缩因子(如 LDM-32)虽然计算效率高,但生成的图像质量较差。适中的压缩因子(如 LDM-4 到 LDM-16)在计算效率和图像质量之间达到了良好的平衡 。
3.2 无条件图像生成
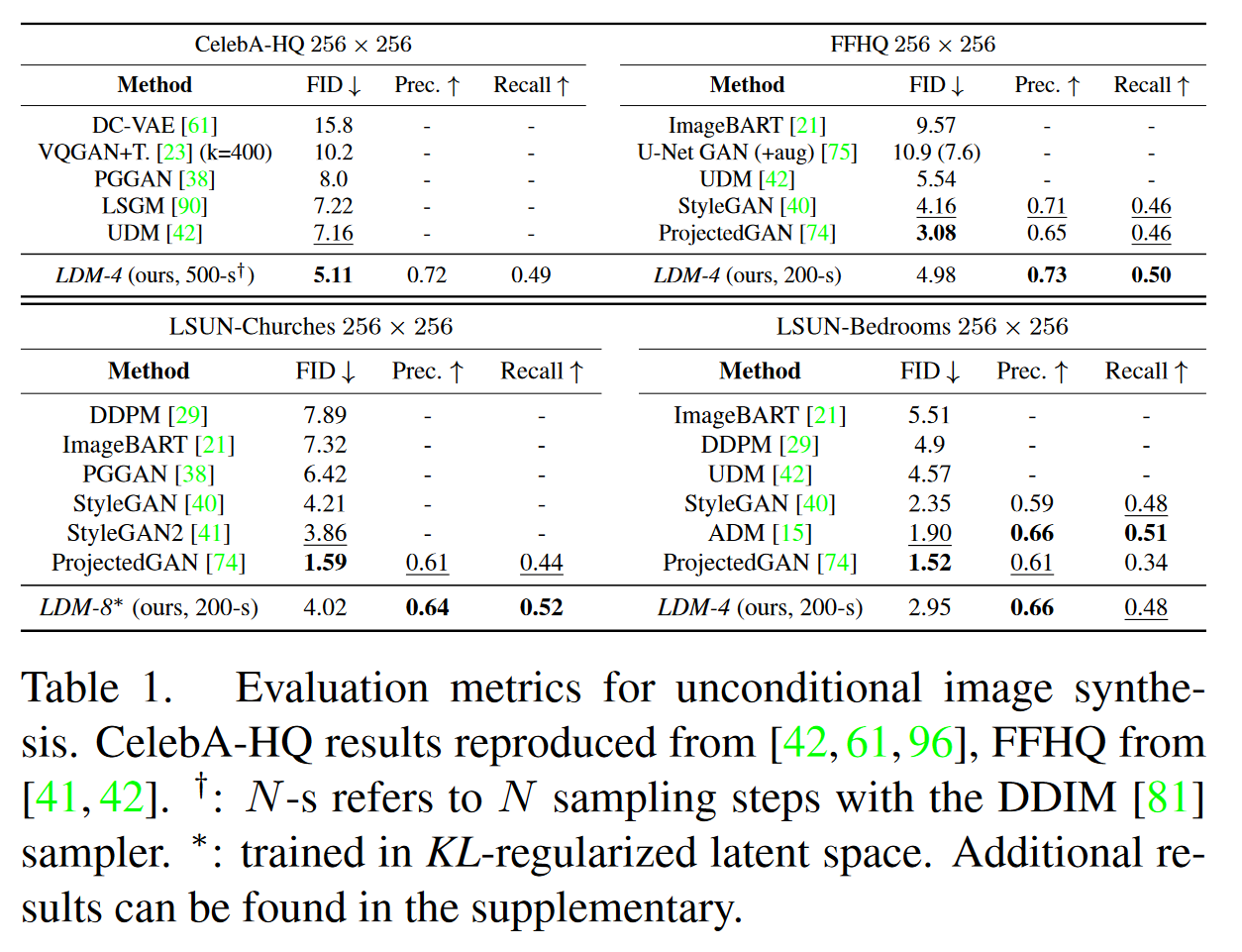
- 在 CelebA-HQ、FFHQ、LSUN-Churches 和 ImageNet 数据集上训练了无条件生成模型,图像分辨率为 256x256。
- LDM-4 模型在 CelebA-HQ 数据集上达到了新的最优 FID 分数,在生成质量上超越了GAN和VAE等方法 。
3.3 文本条件生成
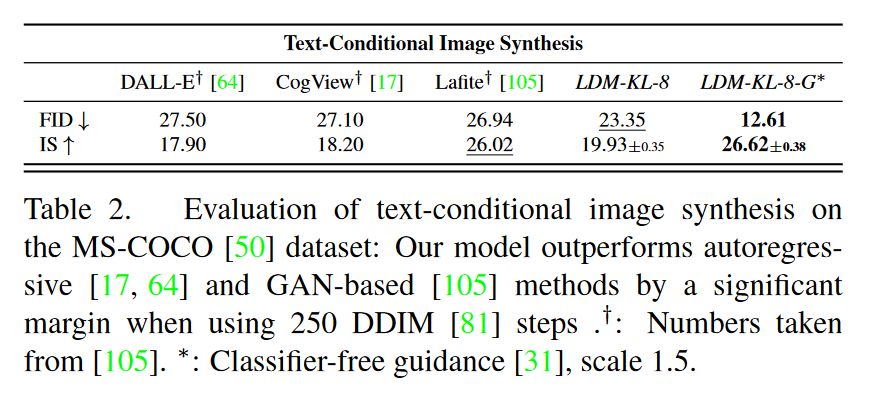
- 在 MS-COCO 数据集上测试文本条件生成,使用交叉注意力机制将文本提示与生成图像关联。
- LDM 模型在文本条件生成任务中的表现优于其他基于自回归模型的生成方法,如 DALL-E 和 CogView,在 FID 和生成多样性方面具有优势 。
3.4 超分辨率与图像修复
- 超分辨率:LDM 模型在 ImageNet 数据集上进行了 64x64 到 256x256 的超分辨率生成实验,生成的图像细节更为逼真。
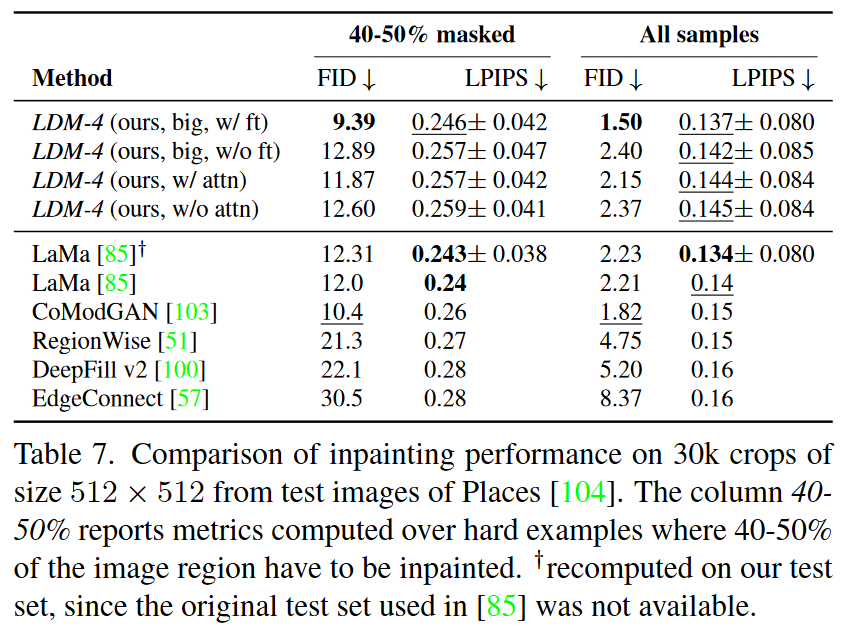
- 图像修复:在 Places 数据集上进行了图像修复实验(inpainting),特别是对图像中 40-50% 被遮挡区域进行修复。
4. 论文创新点
将潜在扩散模型应用于低维潜在空间 降低了计算复杂度,并且通过感知压缩模型去除不重要的高频细节,从而在保持高生成质量的前提下实现高效的图像合成。
引入交叉注意力机制进行灵活的条件生成 引入领域特定编码器来处理不同类型的输入,并通过交叉注意力将这些条件输入的信息注入到生成过程中。
在潜在空间中进行多模态生成的灵活性 不同于以往依赖自回归或离散潜在空间的生成模型,该方法在潜在扩散模型中保留了图像的二维空间结构。这使得模型可以处理更加丰富的输入信息(如语义图、语言提示等),而不是将图像压缩成一维的离散序列。
原文链接:High-Resolution Image Synthesis with Latent Diffusion Models