1. 研究背景、动机、主要贡献
1.1 存在问题(动机)
现有的文本到图像生成模型可以根据文本提示生成高质量和多样化的图像,但它们无法在不同的场景中一致地再现特定主体。 因为即使使用详细的文本描述,现有模型的输出域表达力有限,生成的图像可能会与给定的参考主体外观不同。
1.2 主要贡献
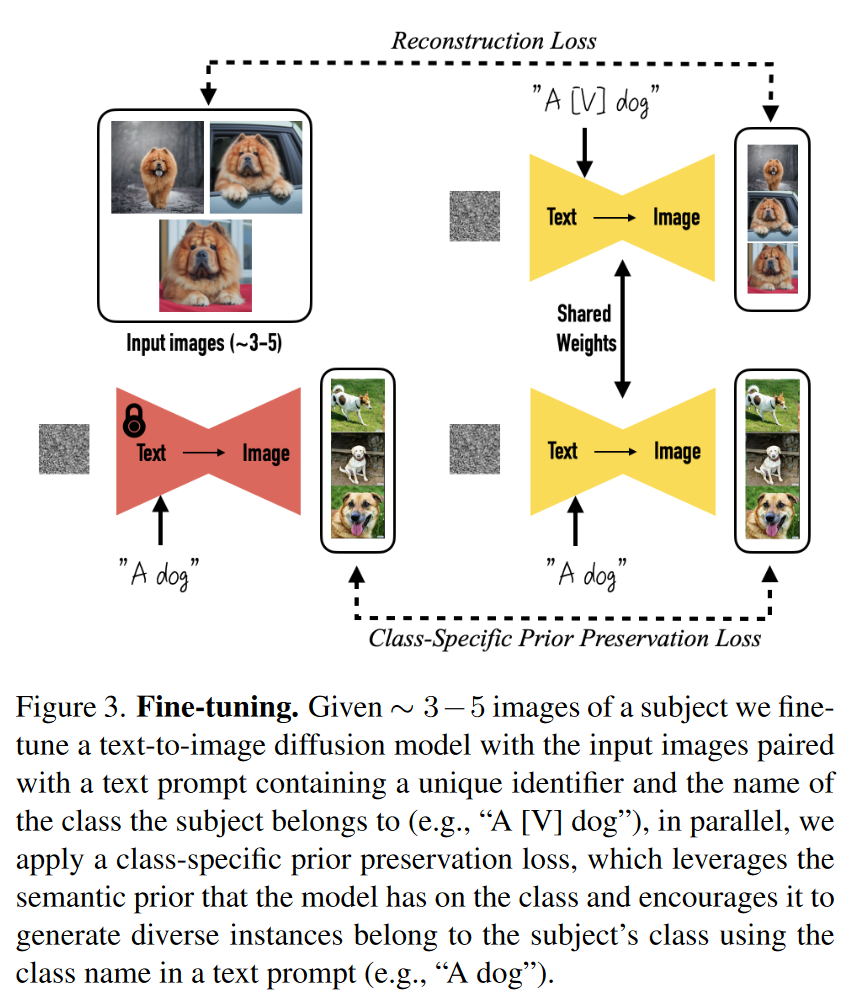
作者提出了一种“个性化”方法,将主体绑定到模型的输出域中(不是在潜在空间操作,是在像素层面),使其可以根据用户提供的图像生成新图像。 具体来说,用户提供一些主体的图片(大约3-5张),模型通过微调生成包含该主体的图像,且能在不同场景下保持主体的关键特征。
本文的技术是第一个解决主题驱动生成这一新的挑战性问题的技术,允许用户从几张随意拍摄的主题图像中合成该主题在不同背景下的新颖再现,同时保持其特色鲜明。
1.3 相关工作
- 图像合成
- 图像合成技术的目标是将给定的主体融入新背景中,使其看起来自然。这通常依赖3D重建技术,但这些方法往往仅适用于刚性物体,且需要大量视角。它们在处理光照、阴影等场景整合问题时表现不足,无法生成全新的场景。
- 本文提出的方法能够生成在新姿势和场景中的主体图像。
- 文本驱动的图像编辑和合成
- 近年来,结合生成对抗网络和图像文本表示的文本驱动图像编辑取得了显著进展。然而,这些方法通常只适用于结构化场景(例如人脸编辑),在处理多样化主体时效果不佳。
- 最近的扩散模型在多样化数据集上的生成质量超越了GAN,但仍无法一致地保持特定主体在生成图像中的身份。
- 现有大规模文本到图像生成模型(如Imagen、DALL-E2、Stable Diffusion等)虽然生成效果突出,但难以精细控制生成图像,特别是保持主体的一致性。
- 可控生成模型:
- 有多种方法用于控制生成模型,其中一些方法可能适用于以主体为驱动的图像生成任务。例如,Liu等提出的基于扩散的技术可以通过参考图像或文本进行图像变体生成,但这些方法在保持主体特征方面表现不佳。
- 一些方法使用用户提供的掩码限制修改区域,但这些方法仍无法生成具有一致身份的主体在新场景中的新图像。
- 在GAN领域,一些方法允许通过微调模型来编辑真实图像,但这些方法通常需要大量图像且仅限于特定领域,如人脸。
2. 论文提出的新方法
2.1 Text-to-Image Diffusion Models
这部分的思路在引入了条件向量这一点和LDM差不多,但是
LDM中是预测噪声,
本文是希望直接优化图片(至少这个公式是这样的),
- 条件向量
, 是文本提示 是真实图像 是控制噪声表和样本质量的项
2.2 Personalization of Text-to-Image Models
使用少量样本数据来微调模型,但这种方式容易导致过拟合或模式崩溃。人们已经对避免这些陷阱的技术进行了研究,但这些研究通常不涉及主体的保留。
此外作者发现大型文本到图像的扩散模型似乎擅长将新信息集成到其领域中,而不会忘记先验信息或过度拟合一小组训练图像
2.2.1 Designing Prompts for Few-Shot Personalization
目标是将一个新的“唯一标识符”与主体绑定,植入模型的“字典”中,使模型可以识别和生成该主体的多样化图像。
为简化操作,模型并不需要每张图片的详细描述,而是使用简单的标签,如
a [identifier] [class noun]
[identifier]是唯一标识符,指代具体的主体;[class noun]是该主体的粗略类别描述(如猫、狗、手表等)。- 类描述符可以由用户提供或通过分类器获得。这种方式利用了模型对类别的先验知识,使其生成符合该类别的多样化图像。如果使用错误的类别描述,可能会增加训练时间并降低生成质量。
2.2.2 Rare-token Identifiers
- 一些常用的英语单词(如“unique”、“special”)不适合作为标识符,因为模型需要学习将这些词与其原始含义区分开,并重新与主体绑定,这增加了学习难度。
- 因此,需要选择稀有标记符,即在语言模型和扩散模型中都有较弱先验的标识符。通过随机选取一些字母组合生成稀有标识符并不理想,因为模型往往会将每个字母单独处理,导致这些标识符仍然具有较强的先验知识。
本文提出通过查找模型词汇表中的稀有标记符,通过去标记器将这些标记符转化为对应的文本字符序列,得到实际的标识符。
- 从词汇表中查找稀有标记符,得到一系列稀有标记符的标记序列
,该序列可以具有可变长度 k,并且发现相对较短的 k = {1, ..., 3} 序列效果很好 。 是源自标记 的解码文本。 - 通过
上的去标记器将标记序列解码为字符序列,生成定义唯一标识符 的字符序列。 - 对于Imagen模型,选择3个或更少Unicode字符的标记,并使用T5-XXL标记器范围内的标记(如5000到10000之间的标记)效果较好。
2.3 Class-specific Prior Preservation Loss
- 语言漂移
- 在语言模型中,当模型从大规模文本语料库上预训练后,再进行特定任务的微调时,模型会逐渐失去其对语言的语法和语义理解能力。本文首次发现了类似现象在扩散模型中的存在,模型在对特定主体进行微调时,逐渐忘记了如何生成该类主体(例如,目标主体所属类别的其他对象,如生成特定狗的图像时,可能逐渐失去生成其他狗的能力)。
- 输出多样性减少
- 扩散模型本身具备生成多样化图像的能力,但在对少量图像进行微调时,可能会导致模型生成的主体视角、姿势等变得单一,特别是在训练过长时间后,模型往往会“固定”在少数几个训练视角上。
为了缓解上述两个问题,作者提出了一种自生成的类特定先验保持损失。这个方法的核心思想是用模型自己生成的样本来监督模型,以便在小样本微调开始后保留先验信息。
- 在模型微调之前,利用冻结的预训练扩散模型生成一定数量的属于相同类别的样本
。 , 。 - 这些样本被用于保持模型的先验知识,并在微调过程中通过损失函数来监督模型。
损失函数设计
损失函数的第一项是用于去噪的传统扩散模型损失。
损失函数的第二项是先验保持损失,它用自己生成的图像来监督模型,并且 λ 控制该项的相对权重。
该方法不仅提高了模型输出的多样性,还有效解决了语言漂移问题,允许模型进行更多的训练迭代而不会出现过拟合。
通过实验,作者发现约1000次迭代、学习率为
1e-5(Imagen)或5e-6(Stable Diffusion)时,能够获得良好的结果。使用3到5张主体图像作为训练数据,每次训练大约生成1000个“a [class noun]”样本,整个训练过程在TPUv4(Imagen)或NVIDIA A100(Stable Diffusion)上仅需5分钟。
3. 论文实验评估方法与效果
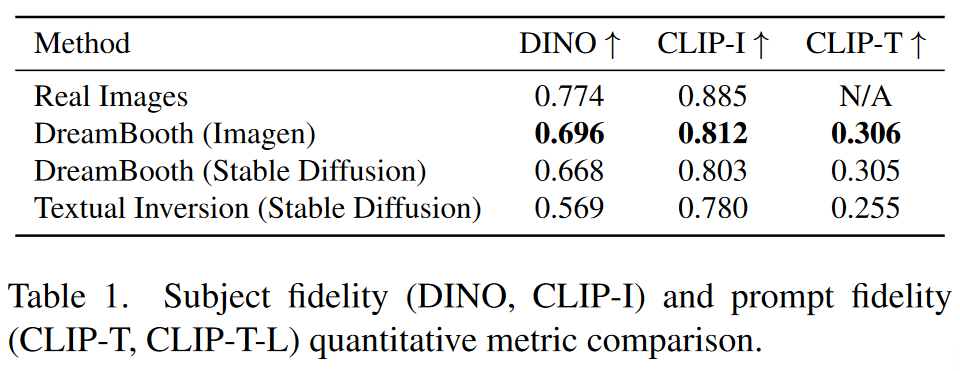
Subject Fidelity(主体保真度) 衡量生成图像与输入图像中的主体是否一致,尤其是细节保留。CLIP-I可以用于这个目的,但DINO由于其自监督训练方式,鼓励区分主题或图像的独特特征,更适合用来区分相似主体,效果更好。
Prompt Fidelity(提示保真度): 评估生成的图像是否准确反映了输入的文本提示。CLIP-T通过比较生成图像与文本提示的CLIP嵌入来计算相似度,从而衡量提示的准确性。
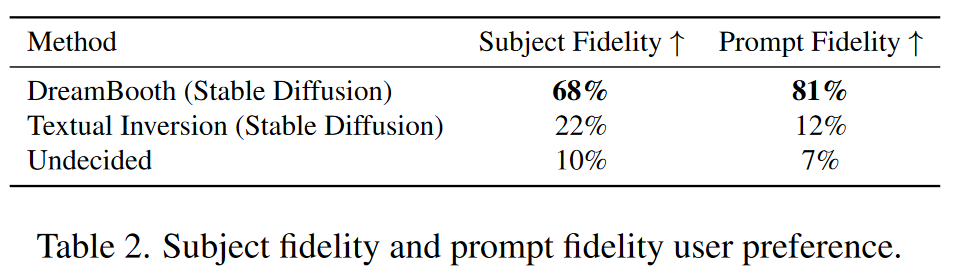
DreamBooth 与 Textual Inversion的对比实验

Ablation Studies
Prior Preservation Loss Ablation
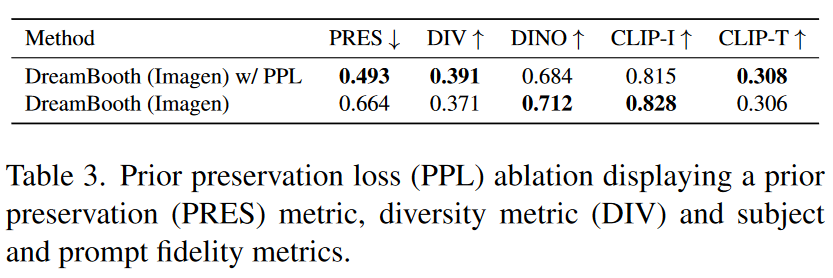
- PRES 用来衡量先验信息保持情况
- DIV 衡量的是生成图像的多样性
Class-Prior Ablation
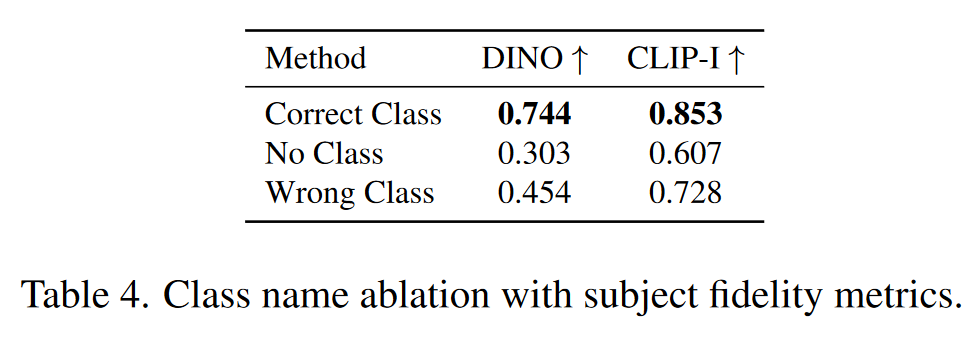
- 正确的类名对于微调生成模型至关重要,能够引导模型更好地利用类的先验知识,从而生成高质量且一致的图像。
- 错误类名会导致类先验和主体特征之间的冲突,生成的结果往往失真或不合逻辑。
- 不使用类名则会使模型缺乏生成的引导,导致生成结果质量低下,训练难以收敛。
关键应用
- 重新场景化(Recontextualization)
- 艺术风格呈现(Art Renditions)
- 新视角生成(Novel View Synthesis)
- 属性修改(Property Modification)
4. 论文局限性
生成的图像未能准确反映给定的上下文提示
主体的外观会因提示的上下文而发生变化
当提示与主体在训练数据中的原始场景相似时,模型可能会过度拟合原始图像,导致生成的图像缺乏变化。
一些主体比其他主体更容易学习(例如,狗和猫)。对于较为罕见的主体,模型可能无法支持足够多的变体生成。
在某些生成图像中,主体的细节保真度可能会有所下降,甚至出现虚构的主体特征。
原文链接:DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation