1. 扩散模型和去噪自动编码器
方法原理
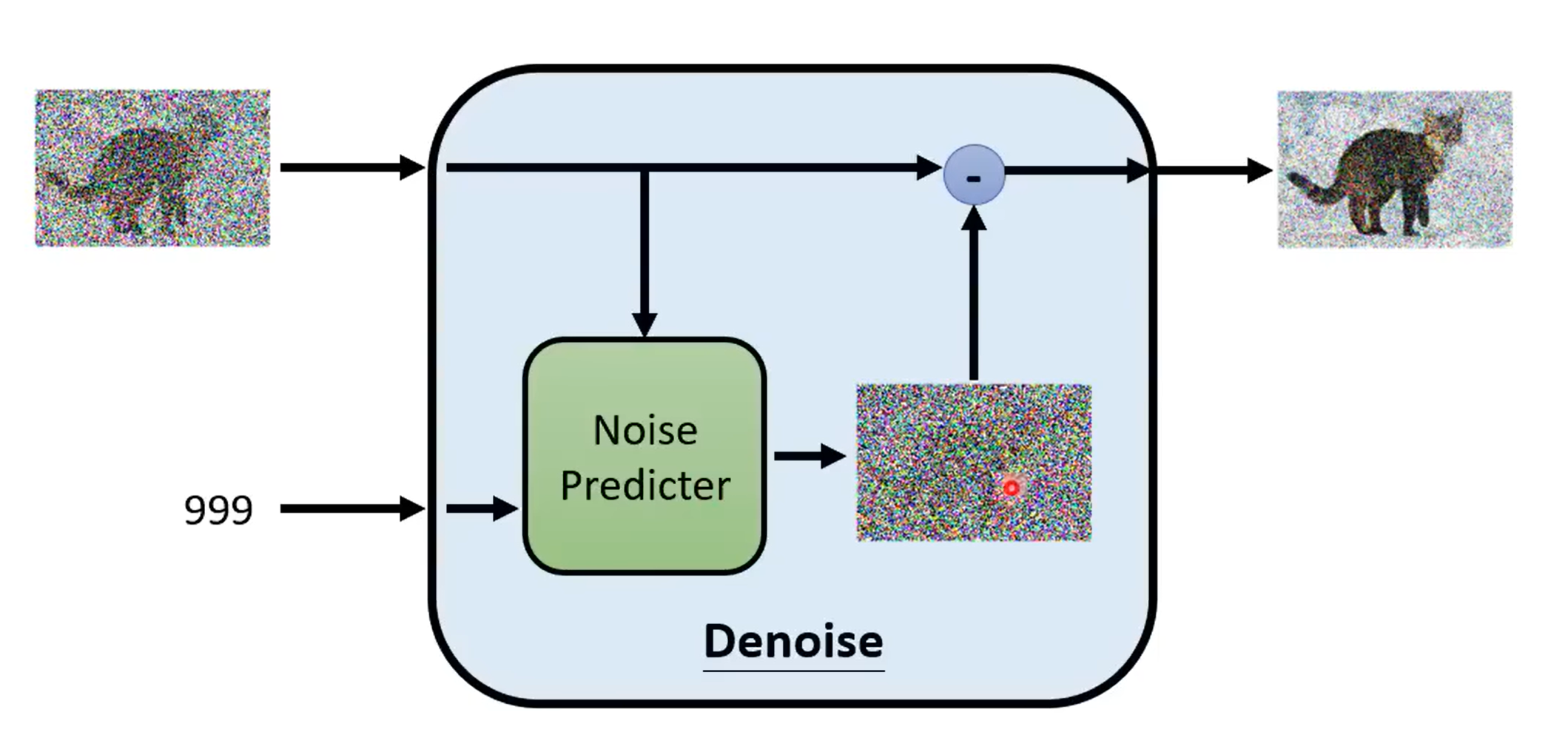
方法原理大概就是对于 Noise Predicter 输入一张有噪音的图、当前的步骤编号(和文字提示),然后 Noise Predicter 生成预测的噪音,再用原来的图片减去噪音,得到更完整的图片。不断迭代。
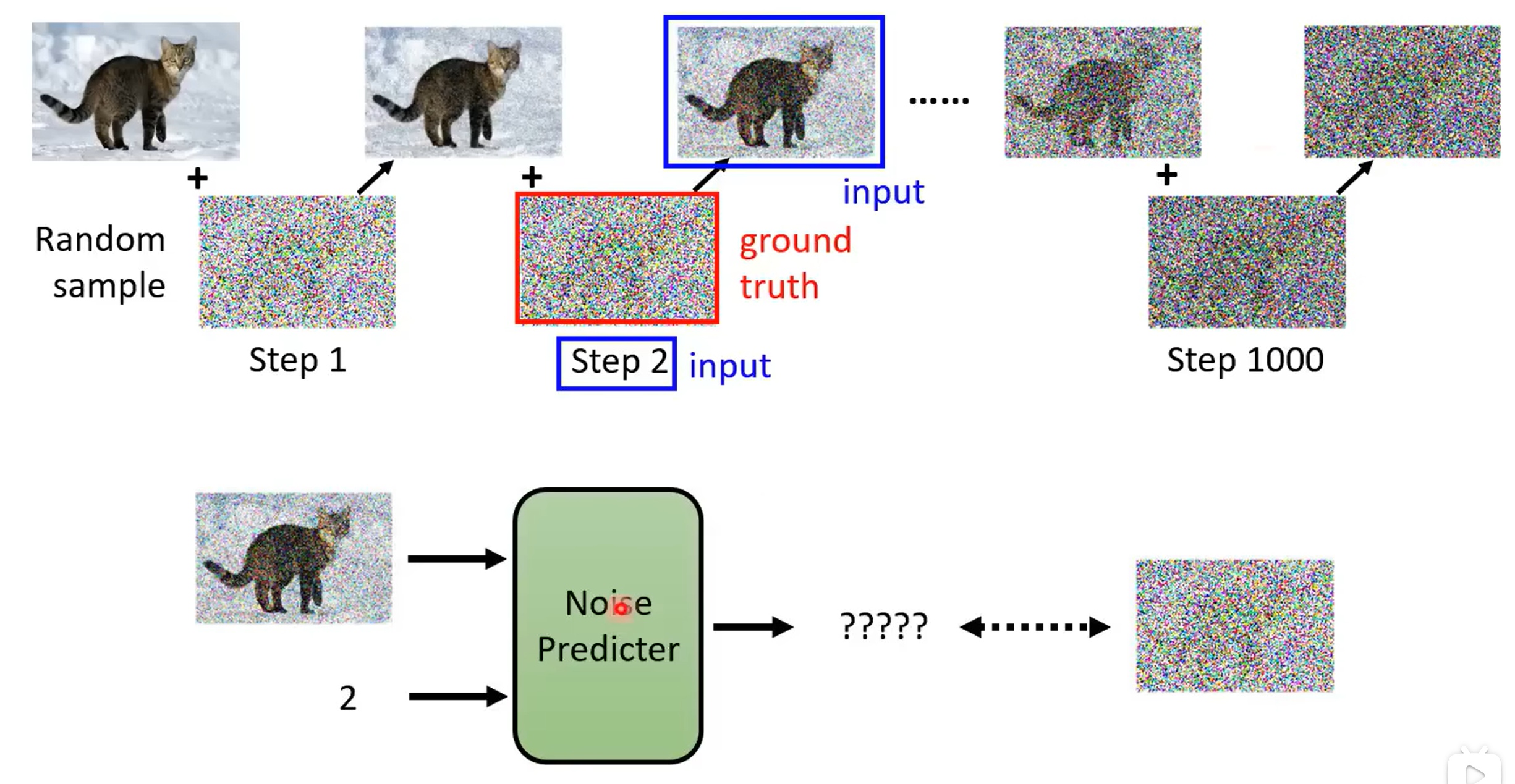
而 Noise Predicter 的训练资料就是对于完整的图片,不断加入噪音
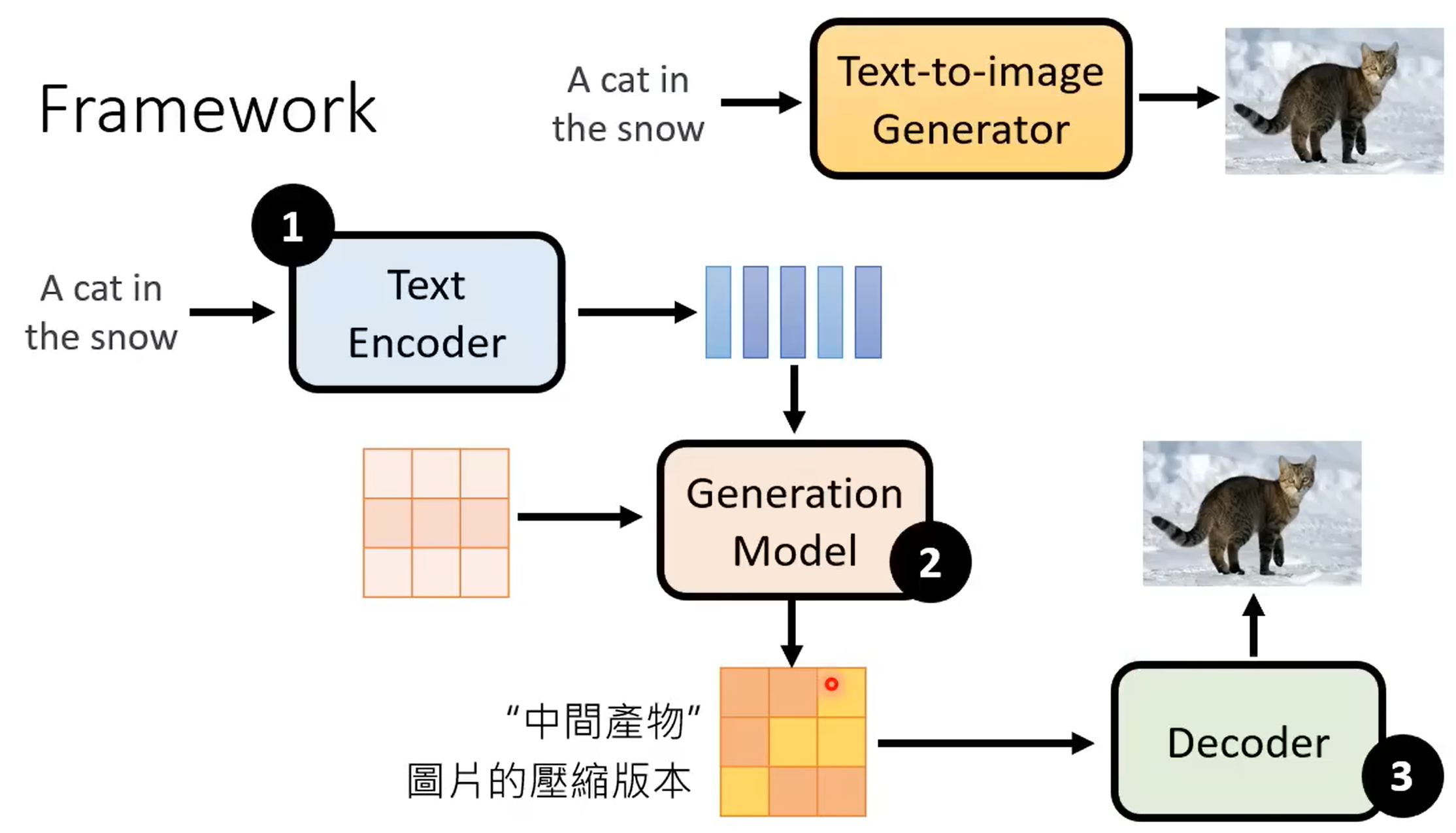
文字到图片主要就是文字先经过一个好的 Text Encoder ,生成向量,在加入噪音,生成模型就生成中间产物,中间产物图片压缩版本经过Decoder生成最终图片
公式推导

实际上并不是一步一步地去噪音的,每一个循环都是在尽量找出对应的噪音,希望能够最大地去噪。

首先是尝试找到

可能无法找到
最终可以化简为(要使下面的式子最小)
- 要使
最小,希望两个分布的mean最接近。 根据 ,替换 ,得到 需要在 的条件下预测为 。 实际上就是需要预测
2. 实验评估方法与效果
为所有实验设置 T = 1000,将前向过程方差设置为从