1. 研究背景、动机、主要贡献
引入新概念到大模型中往往是困难的。因为重新训练模型非常昂贵,而仅用少量示例进行微调通常会导致“灾难性遗忘”——模型忘记了先前学到的知识。尽管有些方法通过冻结模型并训练转换模块来适应新概念,但这些方法依然面临知识遗忘或无法同时访问新旧概念的难题。
解决方案:文本嵌入空间中的新“词”
1.1 相关工作
1.1.1 文本引导的图像合成
文本引导的图像合成最早是在生成对抗网络(GAN)中研究的。通过给定的图像-文本配对数据集,模型会被训练生成相应的图像。现代的方法引入了注意力机制和跨模态对比方法,以提高生成图像与文本描述的匹配度。
近年来,随着大规模自回归模型和扩散模型的出现,生成图像的质量有了显著提升。这些模型的应用领域不仅限于图像生成,还包括图像编辑、视频合成、运动生成等。
然而,这些方法大多依赖用户通过文本准确描述目标图像的能力。而本文的创新点是引入伪词,扩展了生成模型的词汇量,让模型可以通过新的伪词生成个性化的图像,而无需从头训练模型。
1.1.2 GAN反演
GAN反演是指找到一个潜在表示,使得该潜在向量通过GAN生成与目标图像一致的输出。反演方法通常有两类: - 优化方法:直接优化潜在向量,使之通过GAN生成目标图像。 - 编码器方法:使用大规模数据集训练网络,将图像映射到其潜在表示。
本文采用了优化方法,因为它在处理未见过的新概念时更灵活。而编码器方法在泛化时面临更大挑战,可能需要大规模的网络数据来实现相同的自由度。
1.1.3 扩散模型反演
在扩散模型中,反演可以通过给图像添加噪声,然后利用模型去噪来实现。然而,这种方法往往会显著改变图像内容。改进方法包括通过目标图像的低通滤波数据来指导去噪过程,以及使用闭式反演采样过程,这可以提取一个噪声图并生成相应的图像。
在本文的方法中,作者反演的是用户提供的概念,而不是现有图像,将这些概念表示为模型词汇中的伪词,以便在未来生成过程中用于更广泛和直观的编辑。
1.1.4 个性化
个性化模型一直是机器学习的研究目标,尤其是在推荐系统和联合学习中。
最相关的工作是PALAVRA,该方法利用预训练的CLIP模型检索和分割个性化物体。然而,PALAVRA的任务是判别性的,旨在将物体与其他候选对象区分开来。而本文的方法不仅捕捉到了更多细节,还能实现更自然的图像重建和新场景的合成。
1.2 贡献
- 提出个性化文本到图像生成任务,生成场景以展示用户提供的特定概念。
- 在生成模型的背景下提出“文本反演”概念,找到新的伪词嵌入来捕捉高级语义和精细视觉细节。
- 分析了嵌入空间,展示其在失真与可编辑性之间的权衡,并证明法在这方面表现优越。
- 通过比较,展示了方法在图像生成的视觉保真度和编辑能力上具有优势。
2. 论文提出的新方法
2.1 LDM
基于LDM实现本方法
2.2 Text embeddings
- 文本嵌入
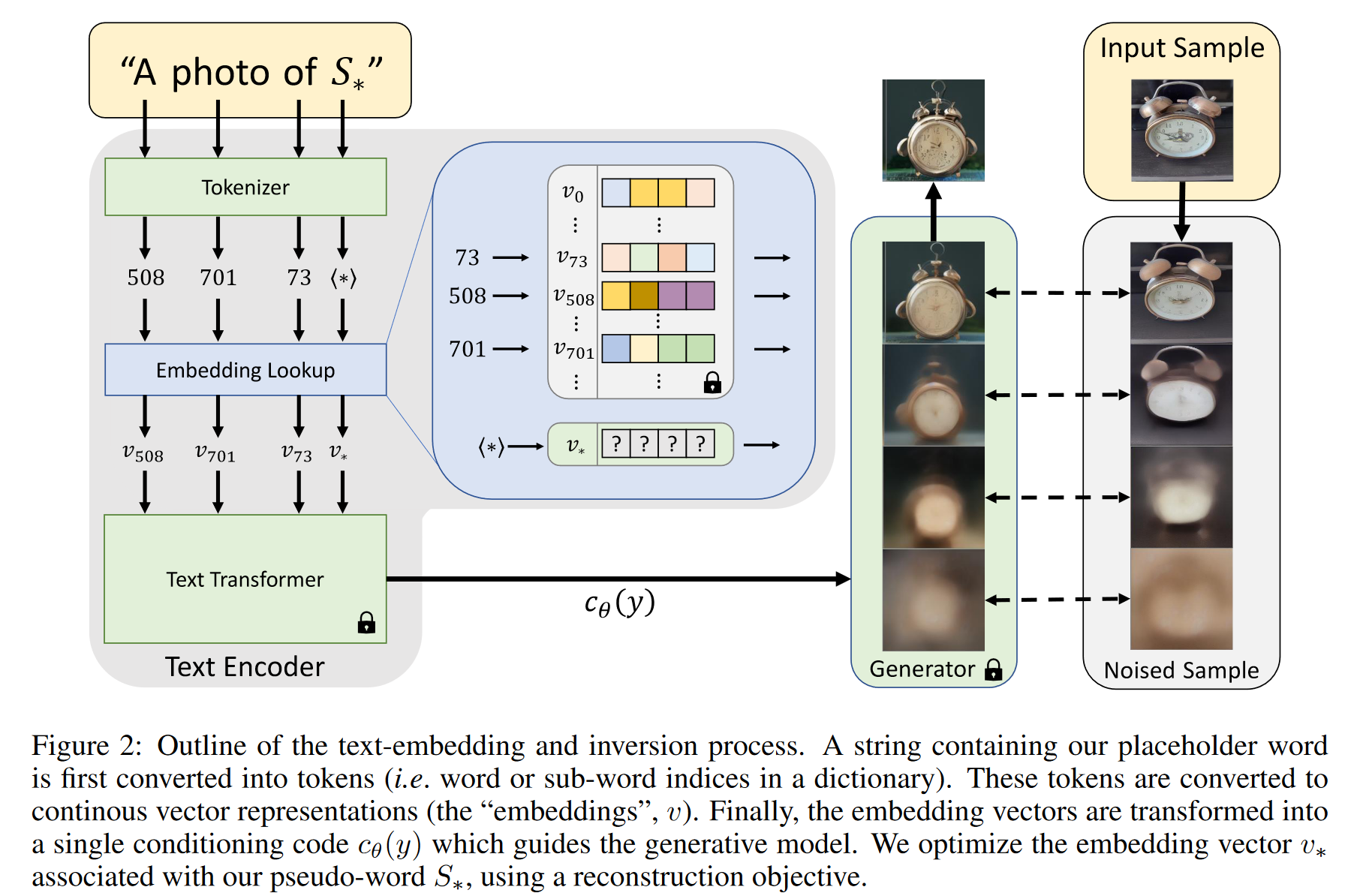
- 文本嵌入是将输入的文本(通常是单词或子词)转换成向量表示的过程。典型的文本编码器模型(如BERT)首先对输入的字符串进行处理,将每个单词或子词转换为token(标记),即某个预定义字典中的索引。
- 每个token对应于一个唯一的嵌入向量,这个嵌入向量通过索引查找的方式获得。这个嵌入向量表示了该单词或子词在语义空间中的位置,编码了其语义信息。
- 嵌入向量的学习
- 文本编码器会在训练过程中学习到这些嵌入向量,使模型可以根据这些向量进行计算和推理,进而理解和生成语言。
- 嵌入空间逆转
- 作者选择文本嵌入空间作为逆转目标。具体来说,他们通过引入一个占位符字符串
来表示他们想要学习的新概念。 - 逆转过程:他们干预嵌入过程,将与token化字符串关联的嵌入向量替换为一个新的、通过优化学习的嵌入向量
。 - 通过这种方式,模型相当于向词汇表中“注入”了一个新概念,并且可以像使用普通单词一样在生成的句子中使用这个新概念。
- 作者选择文本嵌入空间作为逆转目标。具体来说,他们通过引入一个占位符字符串
2.3 Textual Inversion
文本反演的目标是通过优化从一组图像中学习到的新嵌入向量
使用一小组(通常 3-5 张)展示目标概念的图像。这些图像不仅展示了目标物体,还包括不同的背景、姿态等变化。这些变化有助于嵌入向量
捕捉概念的多样性和细节。 通过最小化损失函数(LDM loss)来优化嵌入向量
。让生成的图像尽可能接近输入图像。 优化目标: 在这个过程中,模型保持原本的文本编码器 和去噪网络 不变,只优化嵌入向量 。 为了引导模型生成图像,作者随机采样源自 CLIP ImageNet 模板的中性上下文文本作为文本提示。这些模板包括类似于“A photo of
”或“A rendition of ”的句子,将生成任务与图像内容联系起来,从而为目标概念的嵌入向量 提供上下文。
2.4 Implementation details
- 保留原始超参数
- 词嵌入使用一个与目标对象相关的单词(例如“雕塑”或“猫”)的粗略描述来初始化。
- 实验是在 2 个 NVIDIA V100 GPU 上进行的。这种配置允许进行并行处理,提高了计算效率。使用的批量大小为 4。
- 基础学习率被设置为 0.005。进一步通过 GPU 数量和批量大小来缩放基本学习率,有效率为 0.04。
- 所有结果是在 5,000 次优化步骤内生成的。
3. 论文实验评估方法与效果
- Image variations

- Text-guided synthesis
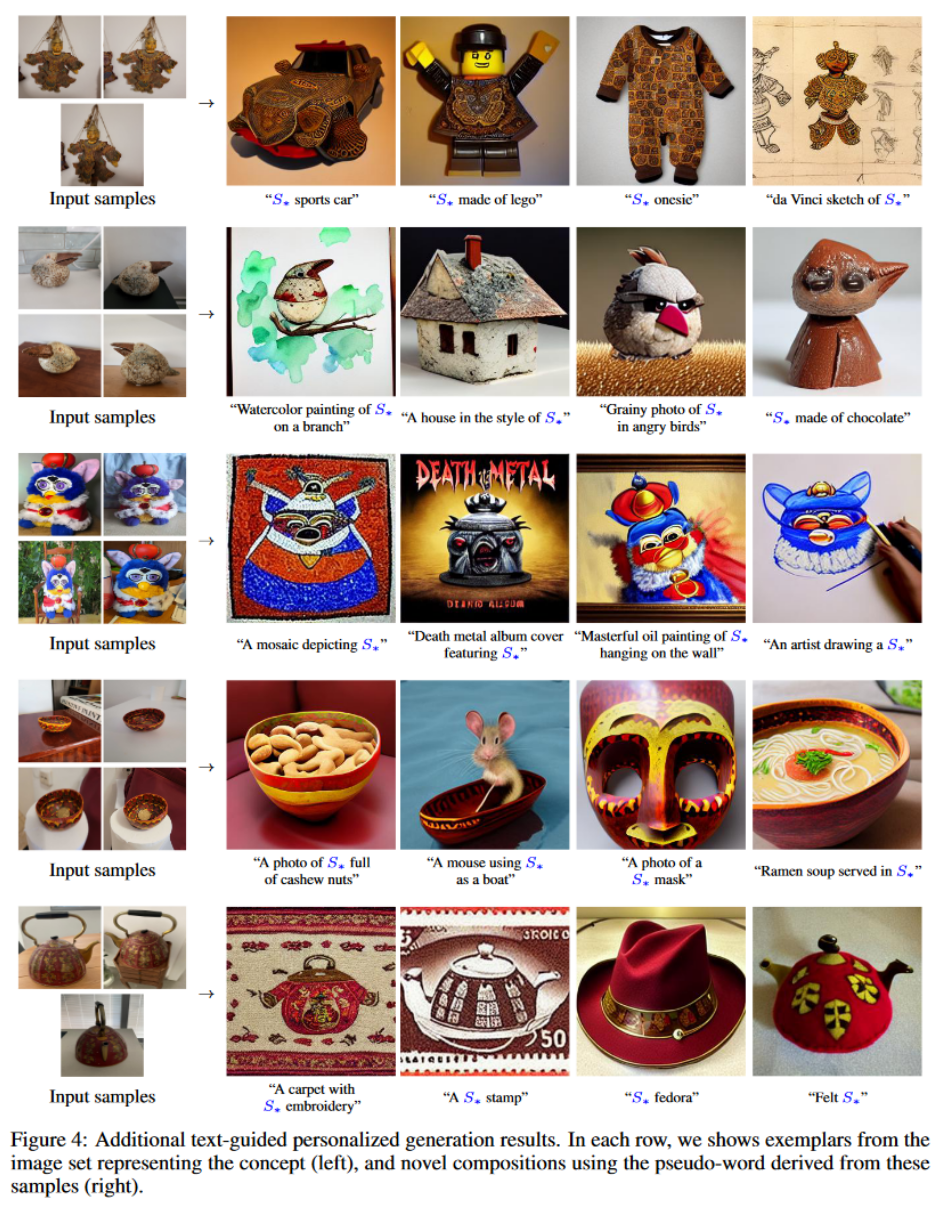

- Style transfer

- Concept compositions

- Bias reduction

- Downstream applications

- Image curation
4. 论文局限性
- 可能仍然难以学习精确的形状,而是融入概念的“语义”本质。
- 优化时间过长,学习一个概念大约需要两个小时。通过训练编码器直接将一组图像映射到其文本嵌入,这些时间可能会缩短。我们的目标是在未来探索这一领域的工作。
另外,在实验部分作者比较的都是先输入一个小的图像集合(通常是 3-5 张图片)进行优化。本文确实是针对这样一个小的图像集合进行过专门的设计,但是对比的其他模型却没有。这样进行最后生成质量的比较是否有失偏颇?是否应该将图像集合扩大后再进行比较?
原文链接:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion