1 研究背景、动机、主要贡献
1.1 存在问题(动机)
现有的方法通过降低潜在空间的维度来缓解表示崩溃问题(只有一小部分 codebook 中向量通过梯度下降更新),但会以牺牲模型容量为代价。
1.2 主要贡献
提出了 SimVQ 方法,有效解决了表示崩溃问题,并在多种模态(图像和音频)和不同模型架构上验证了有效性。
2 论文提出的新方法
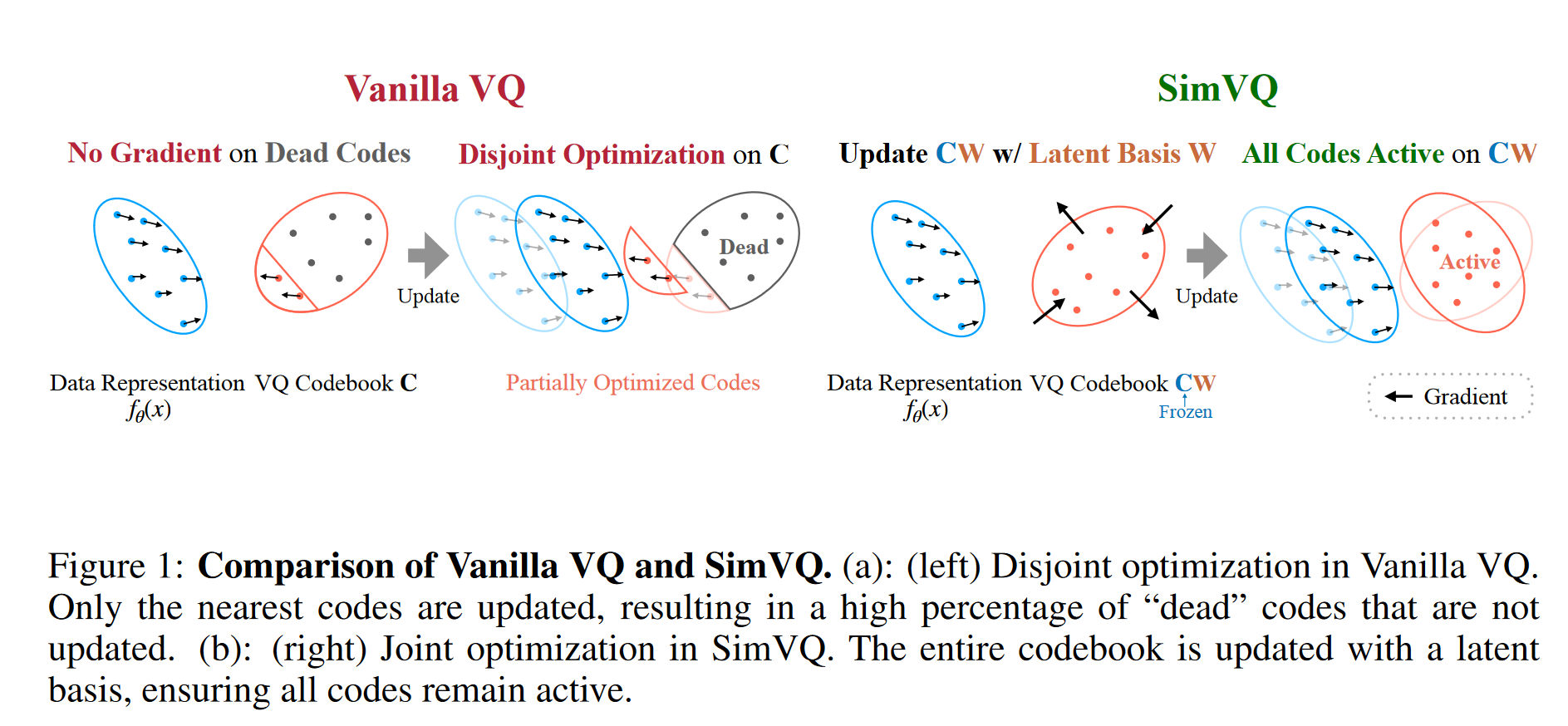

SimVQ 通过引入一个可学习的线性变换矩阵 W 来重新参数化 codebook,将codebook C 转换为 CW。这种方法使得整个 codebook 可以被优化,而不仅仅是被选择的 embedding。且验证了只有 W 被优化,而 C 保持固定的情况下效果最好,同时也显著降低了内存使用并提高了训练效率。
3 论文实验评估方法与效果
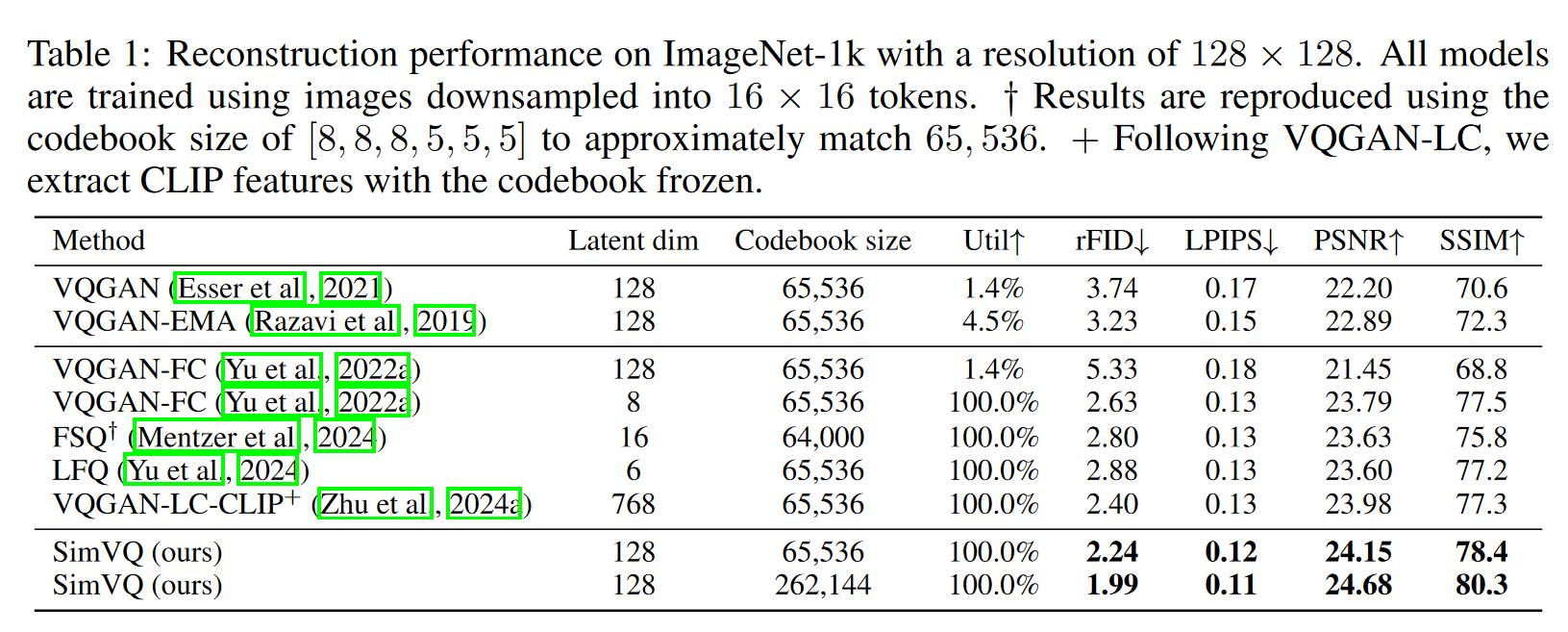
效果上挺好的,且其实验设置 embedding_dim 为 128,而其他的 vq 大多为 8、16。codebook size 为 65536,这点上也放大了其他方法的表示崩溃问题。codebook size 能够设置为 65536,其实也得益于其仅需要更新 W,内存消耗仅为
虽然这样的实验设置是根据本文方法的优点来设置的,同时也会放大其他方法的缺点,但是各个指标上面的表现,也优于其他方法在适合自身方法的 setting 下的表现。
4 论文优缺点、局限性、借鉴性
优点:
- 更高的重建表现、更高的 codebook 利用率
- 更小的内存消耗
- latent dim 较大时也能有较好的表现
缺点(审稿人):
- 虽然这在实践中可能效果很好,但我不认为需要就此写一篇全新的论文
- 论文的主要贡献可以总结为,如果将一个 codeword 分配给编码器输出会导致表示崩溃,那么可以使用整个 codebook 的加权组合。虽然这在实践中可能效果很好,但我不认为需要就此写一篇全新的论文。
- 相关工作的引用
- 请添加2024年ICML的“隐式神经码本的残差量化”以及其他关于VQ的最新论文的引用。
- 文献回顾有限:论文缺乏全面的相关工作回顾,省略了几个相关的解决codebook 崩溃的方法,如SQ-VAE [1]、VQ-WAE [2]、HVQ-VAE [3]和CVQ-VAE [4]
- 没有探索和经典的字典学习、稀疏编码和向量量化的联系
- 没有提到 SC-VAE
- 实验
- 缺少生成方面的实验
- 无法将潜在表示离散化。基于相关系数训练 transformer?
- 缺少 baseline:重要的 baseline 方法如SQ-VAE [1]、VQ-WAE [2]、HVQ-VAE [3]和CVQ-VAE [4]没有包含在实验比较中。
- 缺少和 SC-VAE 的比较
- 缺少生成方面的实验
- 实验分析方面
- “Remark 4.1. The simultaneous optimization of the latent basis w and the coefficient matrix q may lead to the collapse.”. Why is this the case?
- 其他
- 如果包含玩具示例部分,需要详细阐述,以便读者可以手工计算示例。
- 关于 codebook 崩溃原因的见解并不新颖
原文链接:Addressing Representation Collapse in Vector Quantized Models with One Linear Layer