1. 研究背景、动机、主要贡献
1.1 存在问题(动机)
- 文本到图像模型在对图像的空间组成提供的控制方面受到限制。仅通过文本提示来精确表达复杂的布局、姿势、形状和形式可能很困难。生成与我们的心理想象准确匹配的图像通常需要多次反复试验,包括编辑提示、检查生成的图像,然后重新编辑提示。
- 而对于让用户提供其所需图像。特定条件的数据量通常远小于用于一般训练的数据量。这种数据不平衡导致过拟合和灾难性遗忘的问题。
1.2 主要贡献
- 提出了ControlNet,一种神经网络架构,可以通过有效的微调将空间局部化的输入条件添加到预训练的文本到图像扩散模型中。
- 提出预训练的ControlNets,能够基于多种条件(如Canny边缘、Hough线、用户涂鸦、人类关键点、分割图、形状法线、深度和卡通线条绘制)来控制Stable Diffusion。
- 通过消融实验和用户研究验证了该方法的有效性,比较了与多种替代架构的性能,并在不同任务中进行了评估。
1.3 相关工作
1.3.1 Finetuning Neural Networks
- HyperNetwork:最初用于自然语言处理,通过训练一个小的递归神经网络来影响较大网络的权重,之后应用到生成对抗网络(GAN)和图像生成中,并被用来改变Stable Diffusion生成图像的艺术风格。
- Adapter方法:在自然语言处理和计算机视觉中广泛应用。它通过嵌入新模块来定制预训练模型,用于增量学习、领域适应以及将预训练的主干模型迁移到不同任务中。
- Additive Learning:通过冻结原始模型权重,添加少量新参数避免遗忘,方法包括使用权重掩码、剪枝或硬注意力等。
- Side-Tuning:通过添加一个侧支网络并线性混合冻结模型和新网络的输出,学习额外功能,同时避免影响原始模型的表现。
- LoRA (低秩适应):通过低秩矩阵学习参数的偏移,避免灾难性遗忘。该方法基于许多过参数化模型位于低维子空间的观察结果。
- 零初始化层:ControlNet使用零初始化层连接网络块,确保在训练初期不会添加有害噪声。这种方法在神经网络权重初始化和操控中广泛讨论,其他相关的初始化策略如高斯初始化等也被提及。
1.3.2 Image Diffusion
图像扩散模型
- Glide 是一个支持图像生成和编辑的文本引导扩散模型。
- Disco Diffusion 使用CLIP引导处理文本提示。
- Stable Diffusion 是基于潜在扩散的一个大规模实现。
- Imagen 不使用潜在图像,而是通过像素金字塔结构直接扩散。
- 商业化产品包括 DALL-E2 和 Midjourney。
控制技术
- MakeAScene 和 SpaText 利用分割掩码控制图像生成。
- GLIGEN 学习注意力层中的新参数,以进行更精确的生成。
- Textual Inversion 和 DreamBooth 通过微调模型以少量用户提供的图像进行个性化内容生成。
- Prompt-based image editing 提供了通过文本提示编辑图像的实际工具
1.3.3 Image-to-Image Translation
条件 GAN 和 Transformer 可以学习不同图像域之间的映射
- Taming Transformer 是一种视觉变换器方法,用于学习图像域之间的映射。
- Palette 是从头训练的条件扩散模型,专门用于图像到图像翻译任务。
- PITI 是一种基于预训练的条件扩散模型,旨在图像到图像翻译中实现高质量的生成。
2. 论文提出的新方法
2.1 ControlNet
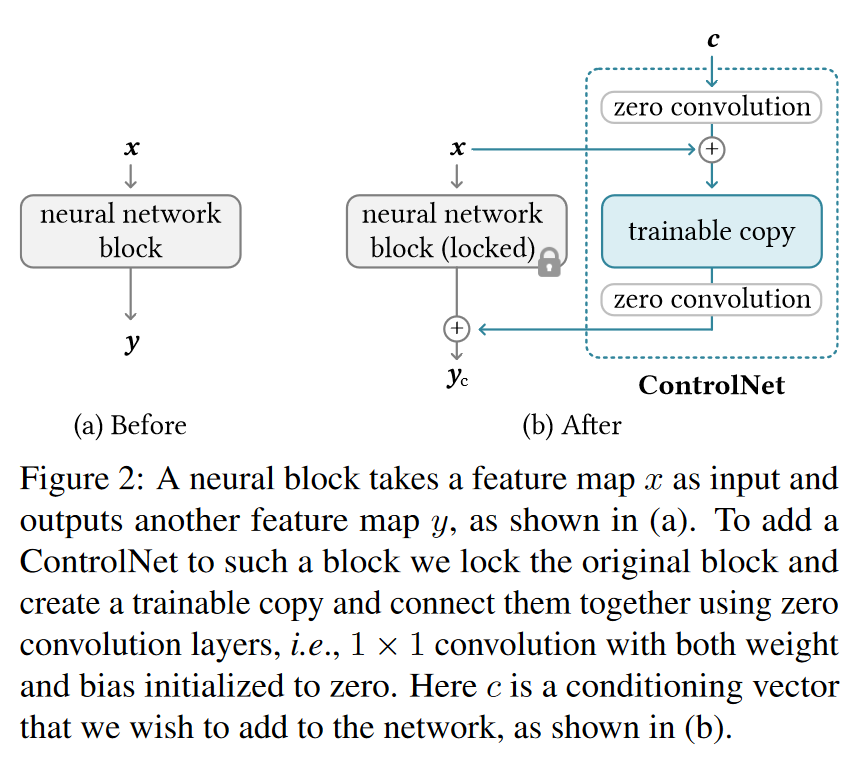
- 一个神经网络块是一组神经层,如ResNet块、卷积块、多头注意力块等。
, 代表一个经过训练的神经模块,其中参数 将输入特征图 x 转换为另一个特征图 y 。 - 为了将 ControlNet 添加到这样的预训练神经块中,会将该原始块的参数
冻结(锁定),同时将该块克隆到具有参数 的可训练副本。可训练副本接收外部的条件向量 c 作为输入。 当这种结构应用于 Stable Diffusion 等大型模型时,锁定的参数保留了用数十亿张图像训练的生产就绪模型,而可训练的副本重用此类大规模预训练模型来建立一个深度、稳健且强大的骨干来处理不同的输入状况。 - 为了将可训练的副本与冻结的预训练模型连接,ControlNet使用了零卷积层
, 是一个 1 × 1 卷积层,权重和偏置初始化为零。 - ControlNet的输出公式
因为权重和偏置初始化为零,所以在第一个训练步骤中 - 由于可训练的副本不仅接收输入图像 x ,还复用预训练模型的能力作为强大的骨干网络,能处理各种复杂的条件输入。零卷积的引入确保了在初始训练过程中,随机噪声不会破坏预训练模型的功能。
2.2 ControlNet for Text-to-Image Diffusion
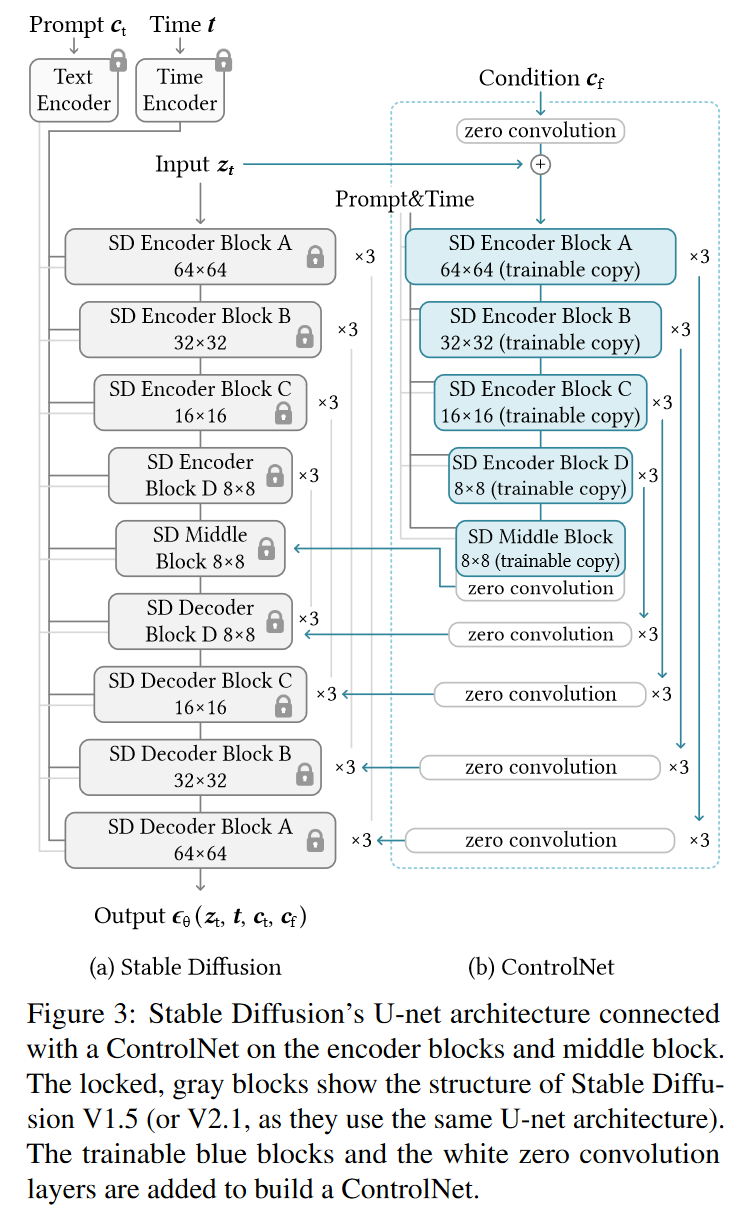
Stable Diffusion 架构
- Stable Diffusion 基本上是一个 U-Net 结构,包含编码器、一个中间块和跳跃连接的解码器。它的总共有25个模块,其中17个是主模块,8个是上下采样的卷积层。
- 主模块每个包含4个 ResNet 层和2个 ViTs,每个 ViT 都包含多个自注意力和交叉注意力机制,处理图像和文本的嵌入(text embeddings)。比如“SD Encoder Block A”包括4个ResNet层和2个ViTs,这个块会重复3次。
- 文本提示通过 CLIP 文本编码器编码,扩散的时间步通过时间编码器编码。
ControlNet 集成到 Stable Diffusion
- ControlNet 的结构被应用于 U-Net 的每一个编码层。 ControlNet 创建了一个可训练的Stable Diffusion编码块的副本(包括12个编码块和1个Stable Diffusion的中间块)。这些编码块在4种不同的分辨率下操作(64×64、32×32、16×16 和 8×8),每个分辨率包含3个重复的块。
- 输出会被添加到12个跳跃连接和U-net的1个中间块上。
- 由于 Stable Diffusion 使用的是典型的U-net架构,因此这种ControlNet结构也可能适用于其他类似的模型。
计算效率
- 连接 ControlNet 的方式在计算上是高效的,冻结的模型参数不会进行梯度计算,减少了计算量并节省了GPU内存。
ControlNet对条件图像的处理:
Stable Diffusion 去噪过程发生在潜在图像空间。它将512×512像素的图像通过VQ-GAN类似的方法预处理为64×64的潜在图像。
为了在 Stable Diffusion 中引入条件控制(如边缘、姿势或深度图),ControlNet 首先要将输入的512×512像素的条件图像转换为64×64的特征空间向量。这通过一个小型网络
实现,该网络由4个卷积层组成(每个卷积层使用4×4的卷积核和2×2的步幅),然后用ReLU激活并逐层增加通道数。 最终,这些条件图像的特征向量
会输入到 ControlNet 中,以实现条件控制。
2.3 Training
特定任务条件 文本提示
随机将 50% 的文本提示
在训练过程中,由于零卷积不会给网络增加噪声,因此模型应该始终能够预测高质量的图像。
模型不会逐渐学会如何处理控制条件,而是通常在不到 10K 次优化步骤后突然开始成功地遵循输入条件生成图像。

2.4 Inference
2.4.1 Classifier-free guidance resolution weighting.

Stable Diffusion 使用了一种称为分类器无关引导 (CFG) 的技术来生成高质量图像。
分别是模型的最终输出、无条件输出、条件输出和用户指定的权重。 当通过 ControlNet 添加条件图像时,条件图像可以被添加到
, 两者,或者仅添加到 。 - 如果条件图像被同时添加到
, ,在没有文本提示的情况下,可能会完全消除CFG引导。 - 如果仅将条件图像添加到
,则引导效果会非常强烈。
- 如果条件图像被同时添加到
解决方案
- 将条件图像首先添加到
,然后根据每个网络块的分辨率大小乘以一个权重 , , 是第 i 个网络块的分辨率大小(例如, )。 - 通过降低CFG引导的强度,可以得到更加平衡的结果(如图5d),这种方法被称为CFG分辨率加权。
- 将条件图像首先添加到
2.4.2 Composing multiple ControlNets.

- 当需要将多个条件输入(如Canny边缘检测和姿势信息)同时应用于一个Stable Diffusion实例时,可以直接将多个ControlNet的输出添加到模型中。
- 在这种情况下,不需要额外的权重调整或线性插值。多个ControlNet的组合可以无缝地直接与Stable Diffusion进行集成,确保不同条件输入的协同工作。
3. 论文实验评估方法与效果
3.1 消融实验
为了模拟真实用户的行为,设置了四种提示语场景:
- 无提示
- 不足提示:提供的提示没有充分覆盖条件图像中的对象,例如默认提示“高质量、详细、专业的图像”。
- 冲突提示:提示内容与条件图像的语义不一致。
- 完美提示:准确描述生成内容所需的提示,例如“一个漂亮的房子”。

3.2 Quantitative Evaluation
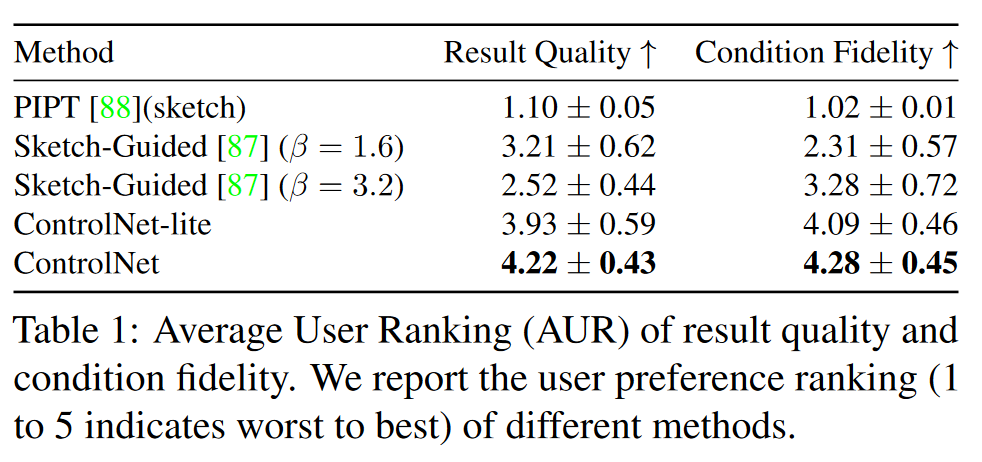
- User study
- Comparison to industrial models
- Stable Diffusion V2 Depth-to-Image (SDv2-D2I)是在大型计算资源上训练的,涉及数千小时的GPU计算和超过1200万的训练图像。
- 与SDv2-D2I相比,ControlNet只使用了200k的训练样本,在一台单一的NVIDIA RTX 3090Ti上训练了5天。
- 生成各100张图像,邀请用户判断哪些图像来自SDv2-D2I,哪些来自ControlNet。结果显示用户的平均准确率为0.52±0.17,表明两种方法生成的图像几乎无法区分。
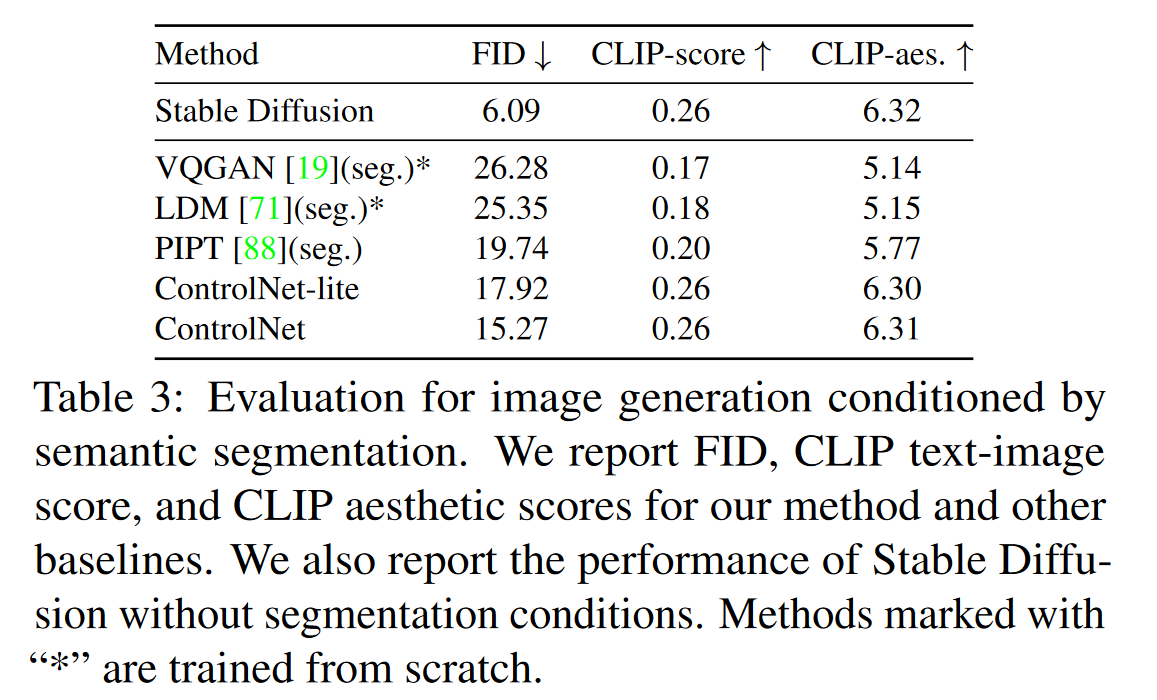
- Condition reconstruction and FID score

原文链接:Adding Conditional Control to Text-to-Image Diffusion Models