1. 研究背景、动机
在视频生成领域,通常通过时间结构来扩展预训练的T2I模型,但这些方法通常更新所有参数,修改原始T2I模型的特征空间,因此与个性化 T2I 模型不兼容。
预备知识
- Stable Diffusion
- Low-rank adaptation (LoRA)
- 在LoRA中,模型的权重W不会直接被更新,而是通过添加两个低秩分解矩阵A和B作为残差来更新。
2. 论文提出的新方法
2.1 ALLEVIATE NEGATIVE EFFECTS FROM TRAINING DATA WITH DOMAIN ADAPTER
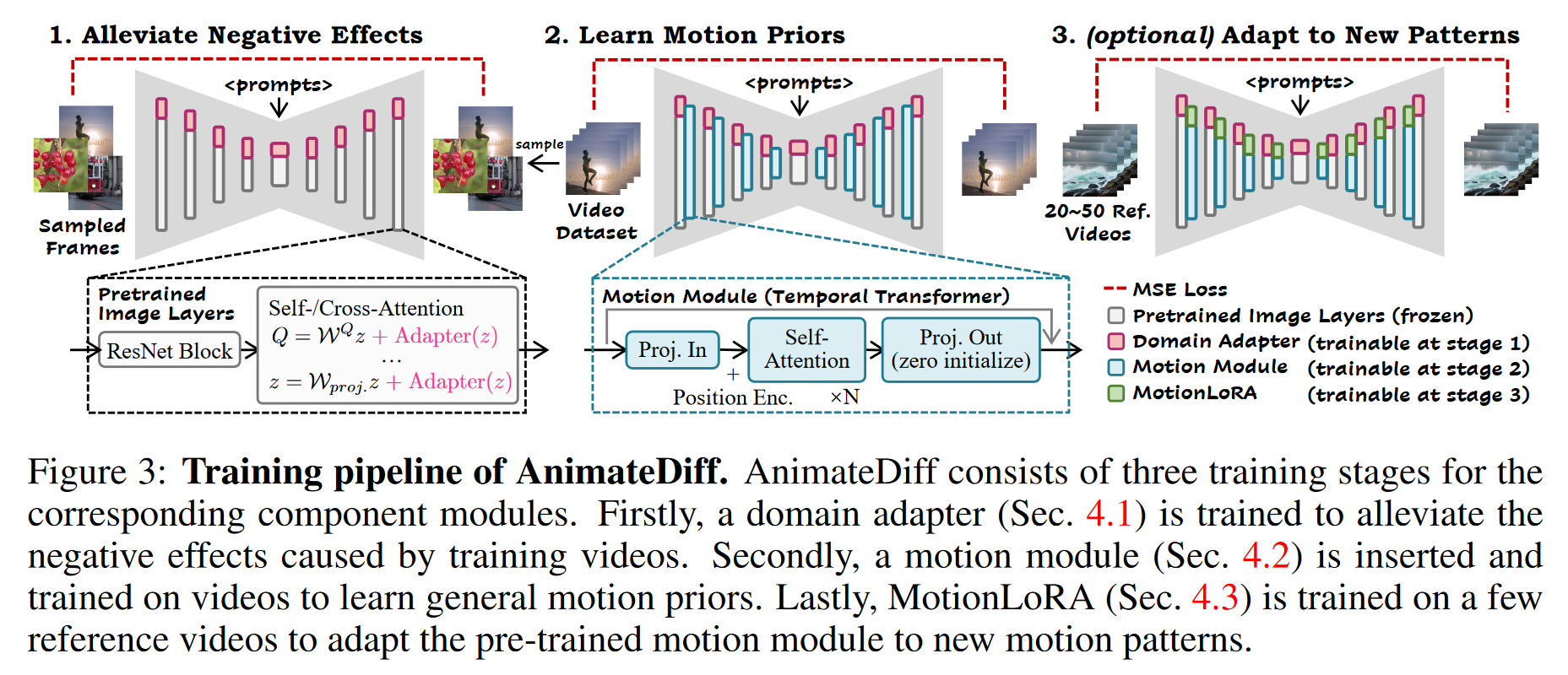
域适配器通过适配视频与图像数据的领域差异,防止模型在训练时学习到低质量的视频特征。
- 视频与图像数据的质量差异
- 视频数据的收集比图像数据更困难,且质量通常较低。
- 视频帧可能存在运动模糊、压缩失真和水印等问题。与高质量的图像数据相比,这些问题导致了视频和图像之间存在显著的质量域差距。
是标量,可以在推理时调整为其他值(设置为 0 以完全消除域适配器的影响)。 - 域适配器通过LoRA(低秩适配)实现,并嵌入到T2I模型的自注意力和交叉注意力层中。这种实现方式允许在训练时只优化域适配器的参数,减少对其他部分的干扰。
2.2 LEARN MOTION PRIORS WITH MOTION MODULE
Network Inflation
预训练的 T2I 模型中已经学到了非常高质量的图像生成能力。为了不浪费这些已有的知识,作者希望将这些图像层的知识扩展到视频数据上,但同时保留这些图像层处理静态帧的能力。
- 将输入修改为5D张量,格式为
,其中: - b是批次维度,
- f是帧的时间维度(代表时间轴),
- h和w是图像的高度和宽度。
- 时间轴(帧数 f)在进入图像层时会被重塑为批量大小 b,每一帧都会被当作一个独立的静态图像来处理。
- 处理完图像层后,再把特征映射恢复成5D张量格式。
Module Design
- 运动模块采用的是 Transformer 架构。这里 Transformer 被调整来处理视频的时间维度(即帧与帧之间的关系)。时间 Transformer 由沿时间轴的多个自注意力块组成,并通过正弦位置编码来编码动画中每一帧的位置。
- 在输入阶段,空间维度(h,w)被整合到 b 中。然后,这些特征图沿着时间轴
f 分割成一系列的向量序列
每个向量对应一个视频帧。这些向量会被投影并进入多个自注意力块。 其中, 是三个独立的投影。通过这种机制,模型可以让每一帧在生成时参考其他帧的信息,从而捕捉动画中的动态变化。 - 为了让模型知道每帧的顺序,必须在自注意力操作之前加入正弦位置编码。如果没有这个编码,模型就无法感知帧的先后顺序。
- 时间 Transformer的输出投影层采用了零初始化,并加入了残差连接。以便运动模块在训练开始时是恒等映射。
2.3 ADAPT TO NEW MOTION PATTERNS WITH MOTIONLORA
MotionLoRA 是一种高效的微调方法,能够快速适应新的运动模式(如镜头变焦、平移和滚动等)。
将 LoRA 层添加到运动模块的自注意力层,并针对新的运动模式进行训练。
研究中进行了多种镜头类型的实验,利用规则基础的数据增强获取参考视频。例如,为了获得具有缩放效果的视频,我们通过沿时间轴逐渐缩小(放大)或放大(缩小)视频帧的裁剪区域来增强视频。MotionLoRA 显示出即使只使用20到50个参考视频和大约2000次的训练迭代(大约1到2小时),也能够取得令人满意的结果。此外,所需的存储空间也相对较小,约为30MB。
2.4 ANIMATEDIFF IN PRACTICE
2.4.1 Training
训练目标:
域适配器的训练使用与 LDM 中相同的原始目标
运动模块、 MotionLoRA 作为动画生成器的一部分,使用类似的目标,但经过轻微修改以适应更高维度的视频数据。
具体训练过程
视频数据批次
首先通过SD的预训练自动编码器编码为潜在编码 。 使用定义的前向扩散过程对潜在编码进行加噪
训练目标是
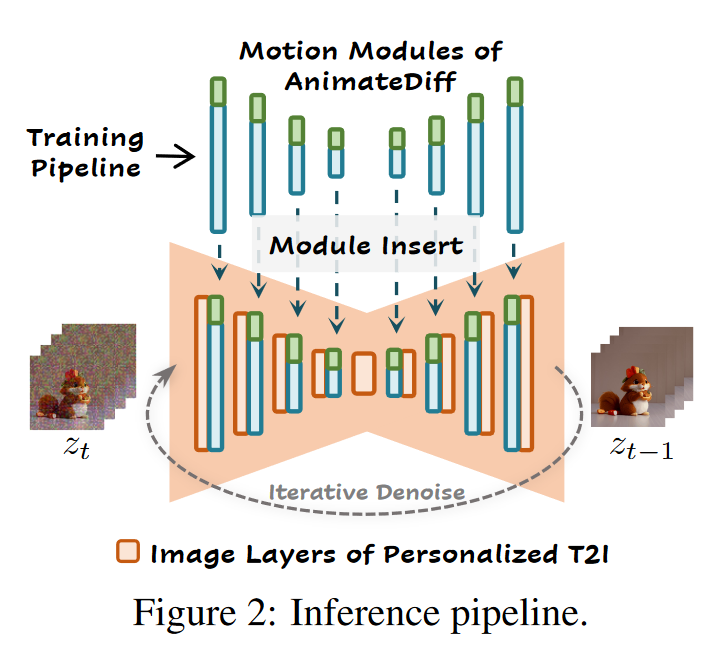
2.4.2 Inference
在推理时,个性化的 T2I 模型将首先进行膨胀,然后注入运动模块以生成一般动画,此外还可以选择性地加入 MotionLoRA 以生成个性化的动画。
在推理过程中,域适配器并非简单地被丢弃,而是可以注入到个性化的 T2I
模型中。用户可以通过调整
最后,通过执行反向扩散过程和解码潜在编码,生成动画帧。
3. 论文实验评估方法与效果
3.1 QUALITATIVE RESULTS
AnimateDiff 使用了 Stable Diffusion V1.5 作为基础模型,并在 WebVid10M 数据集上训练了运动模块。为了验证模型的效果,AnimateDiff 在来自 Civitai 社区的多个个性化 T2I 模型上进行了评估。这些个性化模型涵盖了不同领域,是一个全面的基准。
- 实验展示了 8 个 AnimateDiff 的定性结果,每个样本对应一个不同的个性化 T2I 模型。还展示了与 MotionLoRA 结合的效果,通过组合不同的权重来实现复杂的镜头控制。
- 研究者将 AnimateDiff 与其他最近的基于视频生成的方法(如 Text2Video-Zero 和 Tune-a-Video)以及商业工具(如 Gen-2 和 Pika Labs)进行了对比,证明了 AnimateDiff 在个性化 T2I 动画生成任务上的优越性。
3.2 Quantitative Comparison
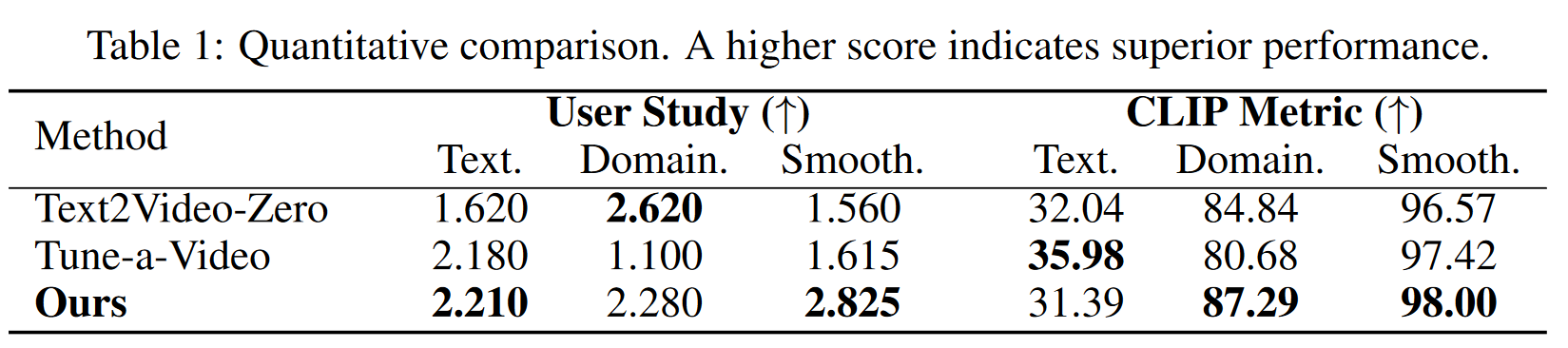
研究者通过用户研究和 CLIP 指标对三个关键方面进行了定量评估
- 文本对齐
- 领域相似性
- 运动流畅度
用户研究:通过生成动画并让参与者对其进行排名,得到平均用户排名(AUR)作为模型性能的衡量指标。文本对齐和领域相似性的评价基于提示词和参考图像。
CLIP 指标:CLIP 指标用于评估动画帧与个性化 T2I 生成的参考图像之间的领域相似性。
3.3 Ablative Study
Domain adapter
通过调整域适配器中的比例因子,研究了其对视觉质量的影响。随着比例因子减少,视觉质量提高,且视频数据集中的分布偏差(如 WebVid 中的水印)减少。表明域适配器通过减轻运动模块学习视觉分布间隙而在增强 AnimateDiff 视觉质量方面发挥了成功作用。
As illustrated in Figure 6, as the scaler of the adapter decreases, there is an improvement in overall visual quality, accompanied by a reduction in the visual content distribution learned from the video dataset (the watermark in the case of WebVid (Bain et al., 2021)). These results indicate the successful role of the domain adapter in enhancing the visual quality of AnimateDiff by alleviating the motion module from learning the visual distribution gap.
此处随着比例因子减少,视觉质量提高,是否与下面的
the successful role of the domain adapter in enhancing the visual quality矛盾?:thinking:
Motion module design
- 比较了时序Transformer和1D时序卷积。结果表明,时间 Transformer 更好地捕捉帧与帧之间的动态变化,而全卷积模块未能有效建模帧间的运动变化。
Efficiency of MotionLoRA
- MotionLoRA 在参数效率和数据效率上进行了实验。研究表明,即使参数量较小,MotionLoRA 依然能够学到新摄像机运动(如放大或缩小);然而,当参考视频数量过少(如 N=5)时,模型的运动质量显著下降。
4.4 Controllable Generation
将 AnimateDiff 与 ControlNet(注意力机制,零卷积层) 结合,通过提取的深度图序列控制动画生成,展现了高质量的动画效果,特别是在细节(如头发、面部表情)方面的表现非常出色。
与 DDIM(非马尔可夫) 进行对比。
原文链接:ANIMATEDIFF: ANIMATE YOUR PERSONALIZED TEXT-TO-IMAGE DIFFUSION MODELS WITHOUT SPECIFIC TUNING