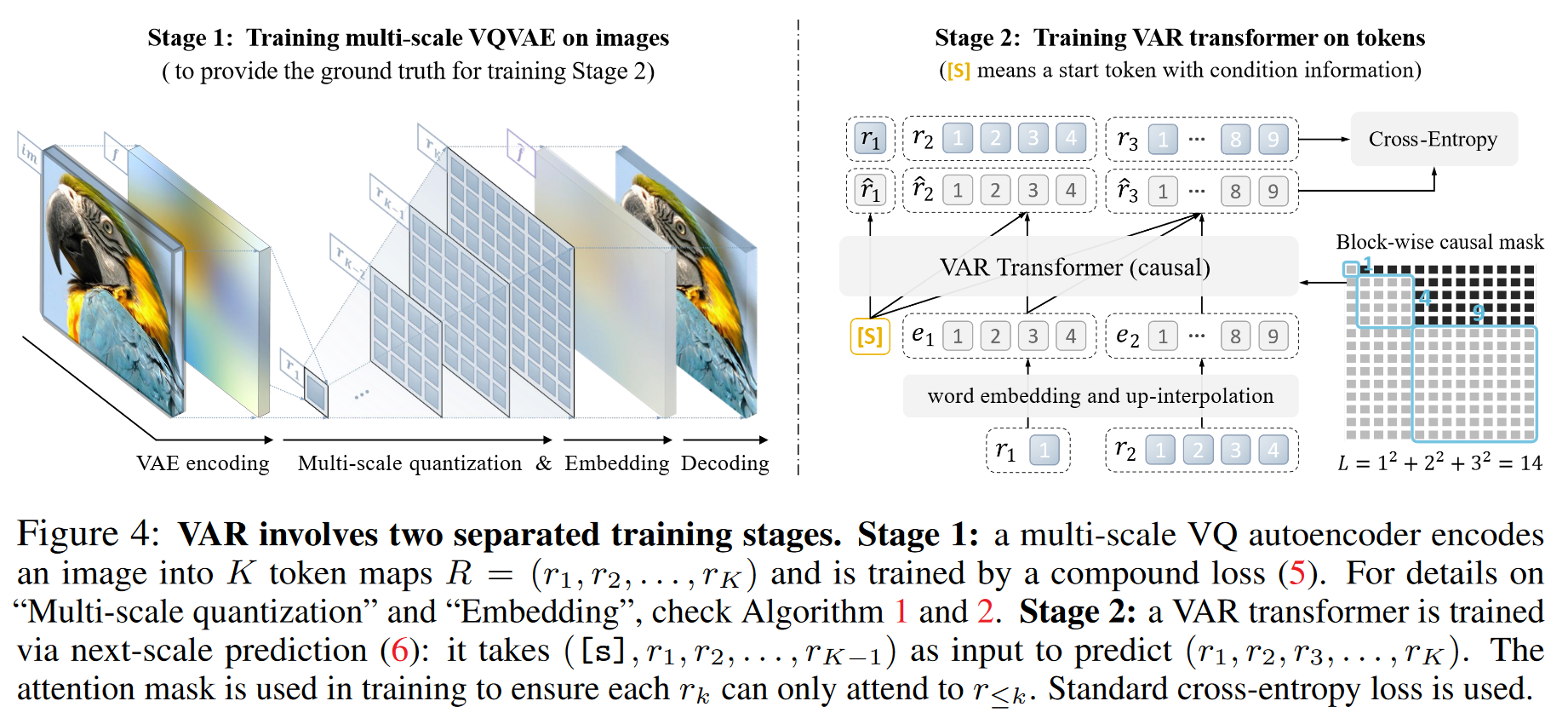
1 研究背景、动机、主要贡献 1.1 研究背景 标准自回归模型 vs. VAR AR在文本中的应用:按顺序从左到右逐个生成文本标记。 AR在图像中的应用:以类似的方式,从左到右、从上到下逐行生成图像的视觉标记,类似于在文本...

Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
1 研究背景 基于自回归模型的 LLMs 取得了显著进展,部分研究开始探讨自回归模型在图像生成领域的应用,并引入图像标记化技术将连续图像转换为离散标记,从而实现图像标记的生成。 2 论文提出的新思路、新理论、或新方法 首先,...
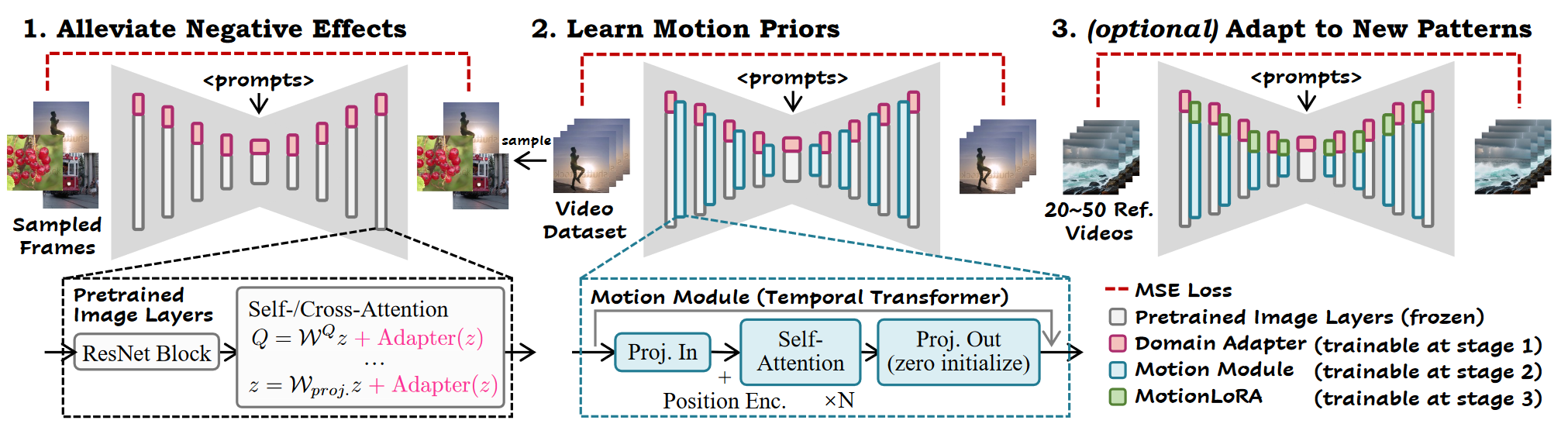
ANIMATEDIFF: ANIMATE YOUR PERSONALIZEDTEXT-TO-IMAGE DIFFUSION MODELS WITHOUT SPECIFIC TUNING
1. 研究背景、动机 在视频生成领域,通常通过时间结构来扩展预训练的T2I模型,但这些方法通常更新所有参数,修改原始T2I模型的特征空间,因此与个性化 T2I 模型不兼容。 预备知识 Stable Diffusion L...
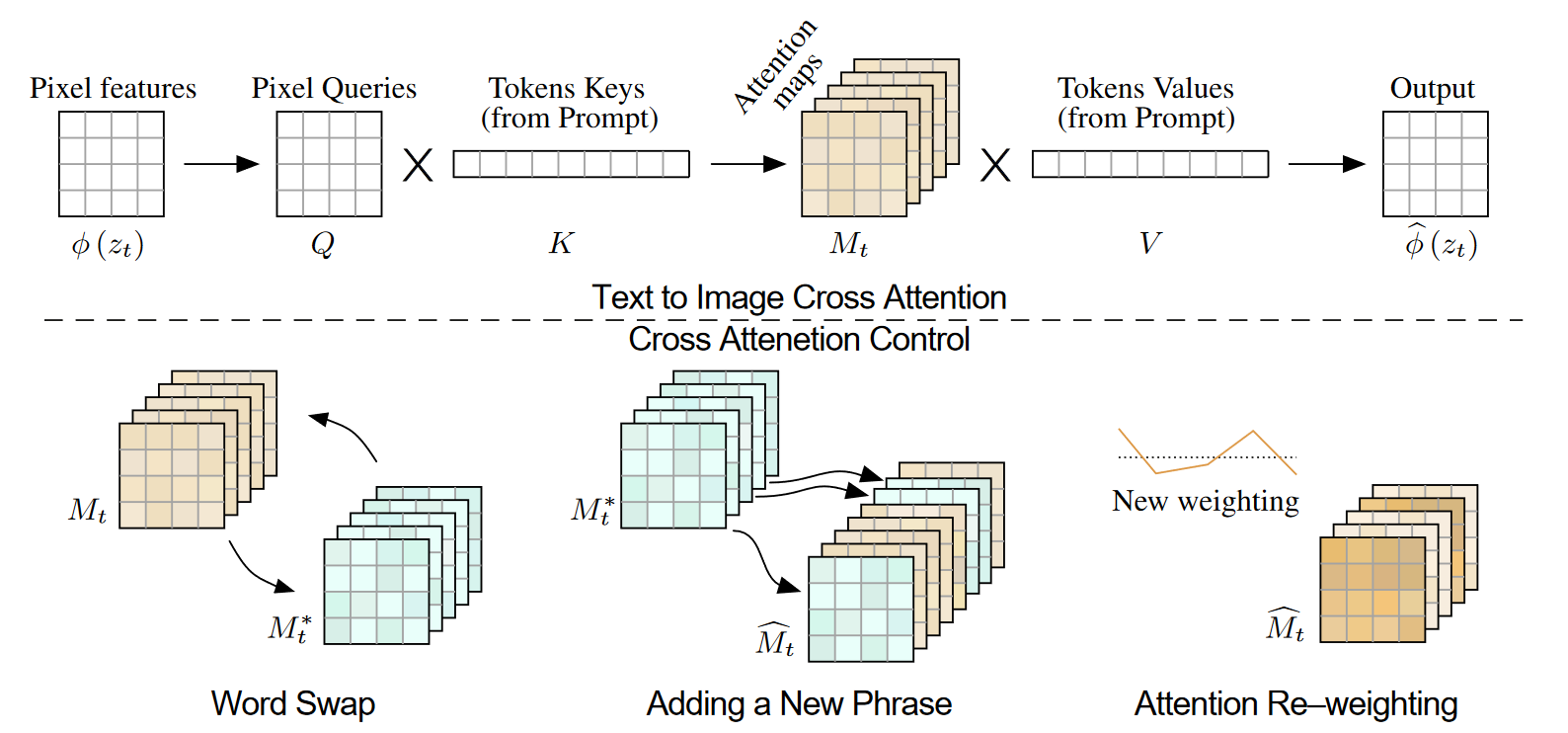
Prompt-to-Prompt Image Editing with Cross Attention Control
1. 研究背景、动机、主要贡献 1.1 研究背景 像Imagen、DALL·E 2和Parti等LLI模型,展示了出色的语义生成和组合能力,但它们在图像编辑方面存在控制力不足的问题。即使是对文本提示的轻微修改,生成的图像也可能完...
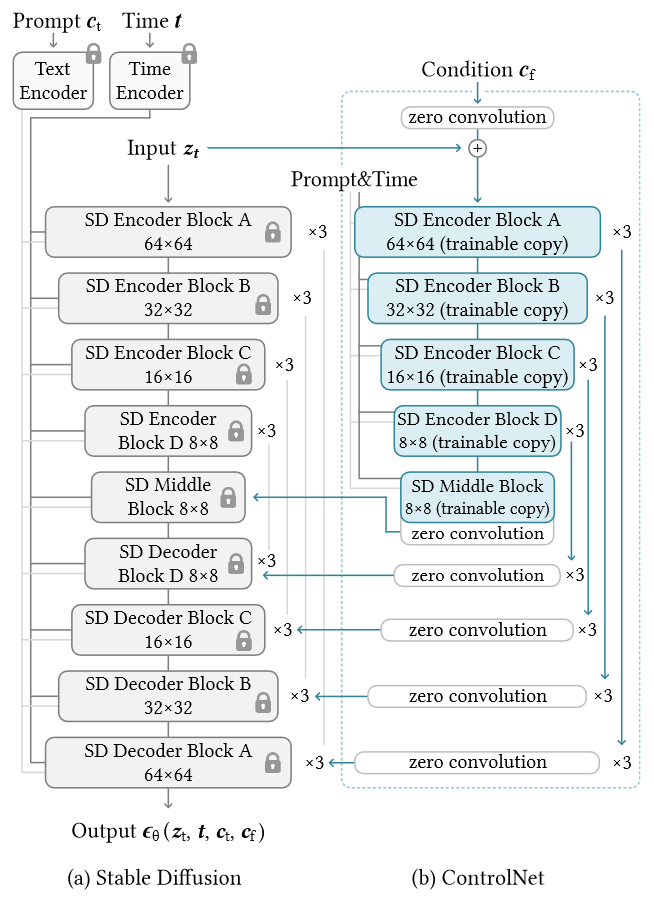
Adding Conditional Control to Text-to-Image Diffusion Models
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 文本到图像模型在对图像的空间组成提供的控制方面受到限制。仅通过文本提示来精确表达复杂的布局、姿势、形状和形式可能很困难。生成与我们的心理想象准确匹配的图像通常需要多次反...
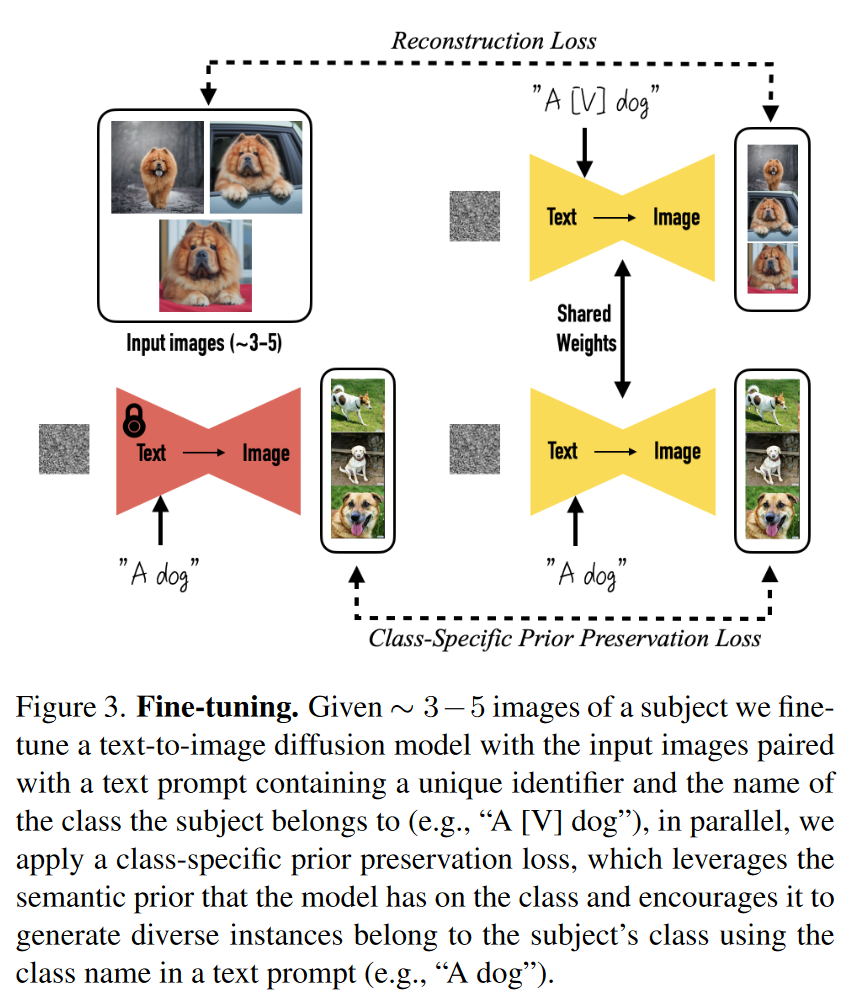
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
1. 研究背景、动机、主要贡献 1.1 存在问题(动机) 现有的文本到图像生成模型可以根据文本提示生成高质量和多样化的图像,但它们无法在不同的场景中一致地再现特定主体。 因为即使使用详细的文本描述,现有模型的输出域表达力有限,生...
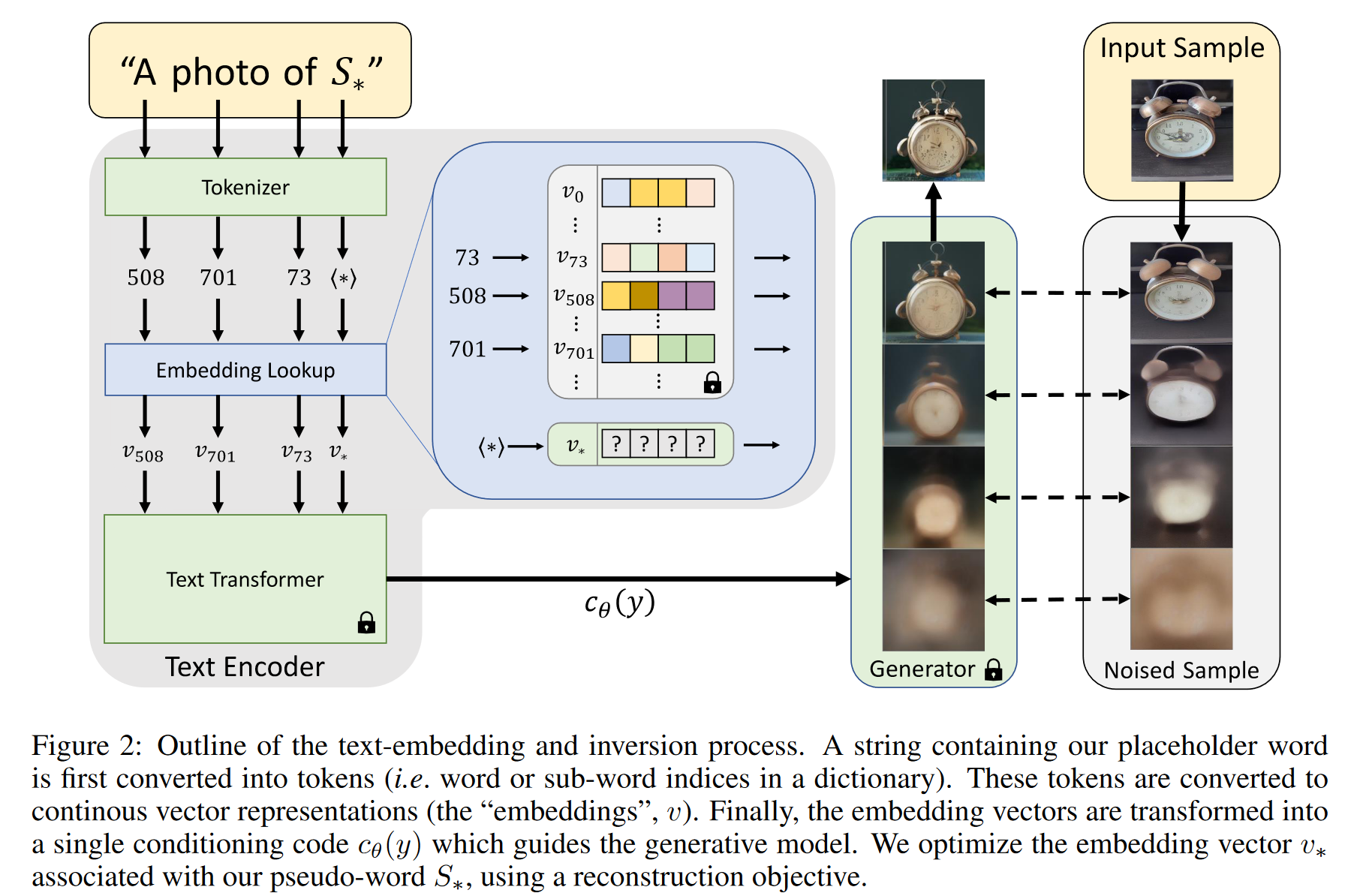
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
1. 研究背景、动机、主要贡献 引入新概念到大模型中往往是困难的。因为重新训练模型非常昂贵,而仅用少量示例进行微调通常会导致“灾难性遗忘”——模型忘记了先前学到的知识。尽管有些方法通过冻结模型并训练转换模块来适应新概念,但这些方法依...
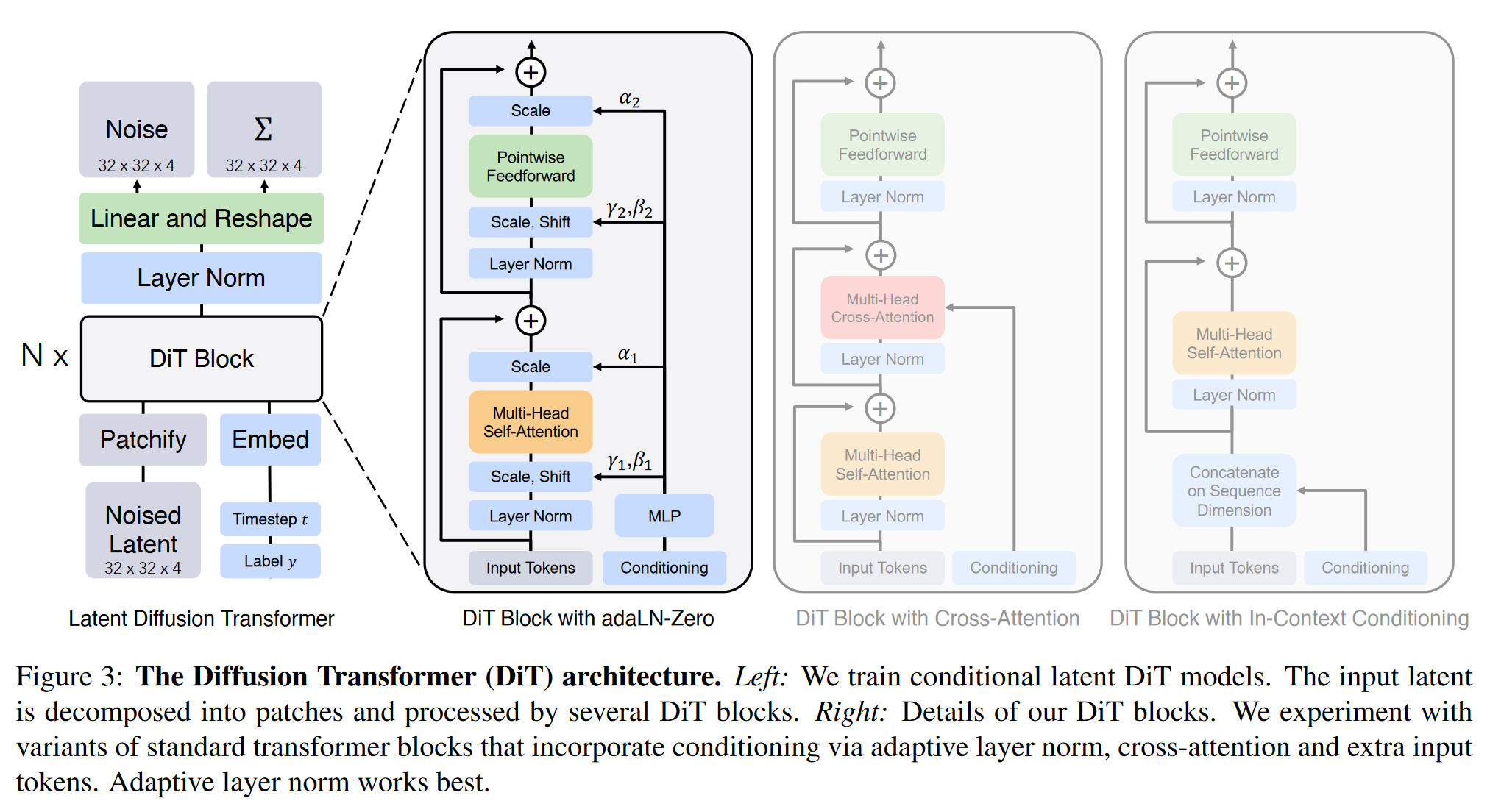
Scalable Diffusion Models with Transformers
1. 研究背景、动机、主要贡献 传统的扩散模型大多采用U-Net作为主干网络,LDM ( High-Resolution Image Synthesis with Latent Diffusion Models ) 也只是通过交...
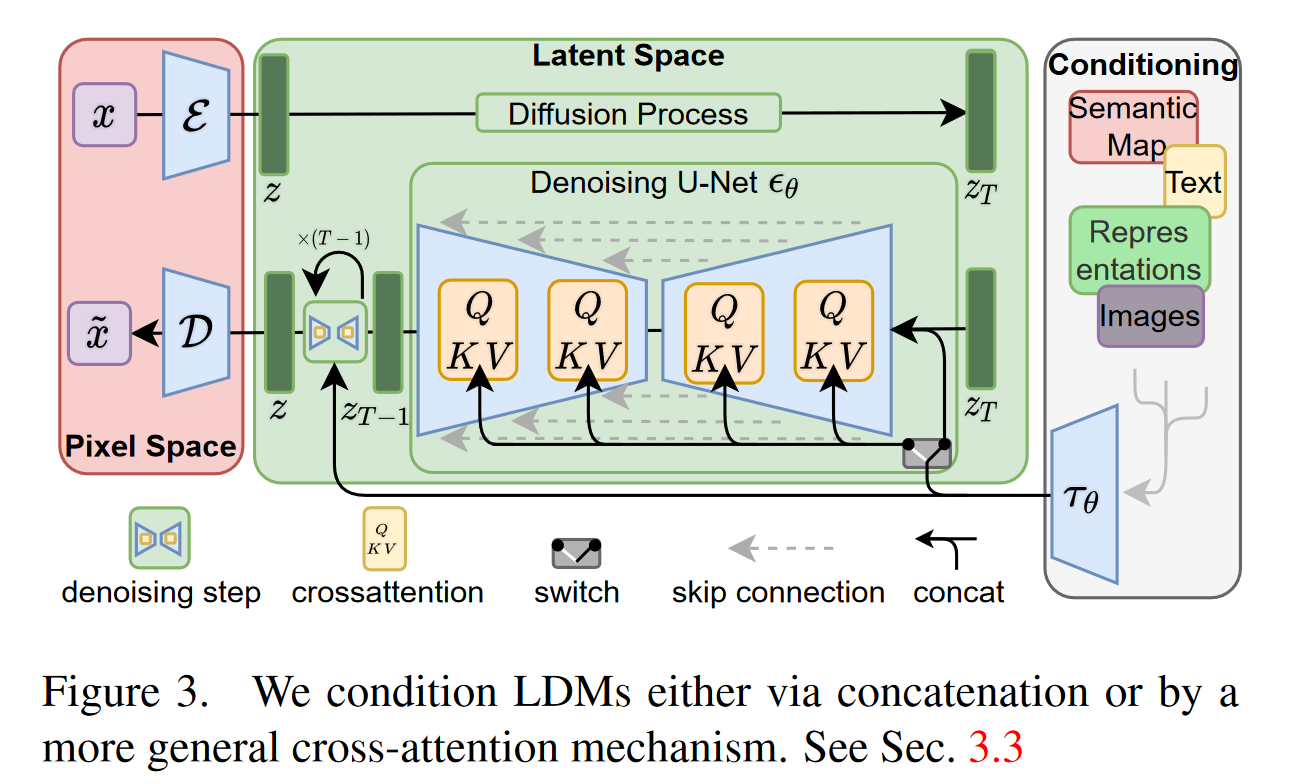
High-Resolution Image Synthesis with Latent Diffusion Models
1. 研究背景、动机、主要贡献 传统的扩散模型在像素空间操作,导致计算开销巨大,训练和推理都非常耗时。特别是高分辨率图像合成需要大量的GPU资源,限制了模型的广泛应用。 为了降低计算复杂度,作者提出在预训练的自动编码器的潜在空间中...
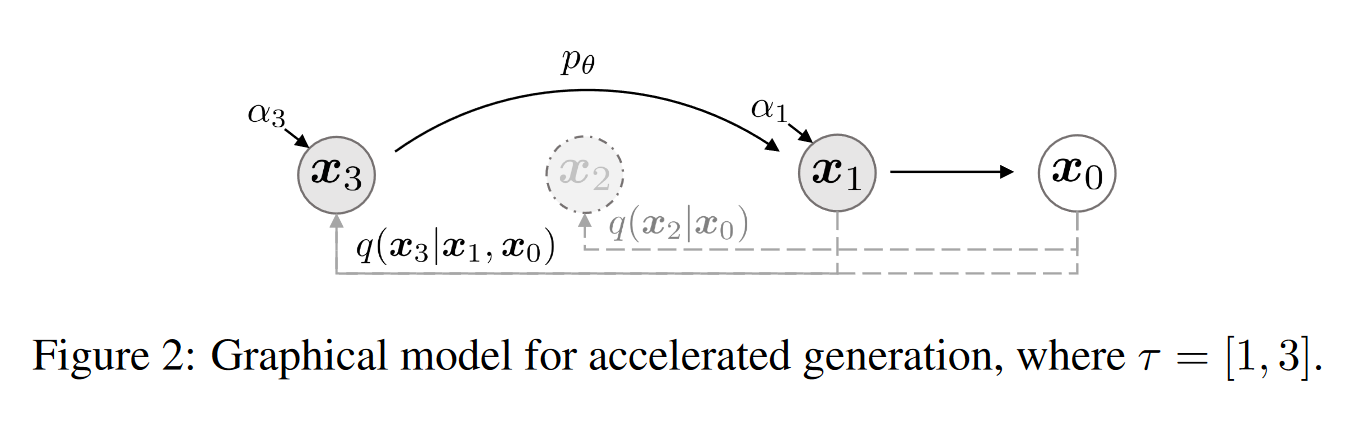
DENOISING DIFFUSION IMPLICIT MODELS
1. 研究背景、动机、主要贡献 在 DDPM 中,生成过程被定义为特定马尔可夫扩散过程的逆过程。 本方法通过一类非马尔可夫扩散过程来推广 DDPM。 这些非马尔可夫过程可以对应于确定性的生成过程,从而产生能够更快地生成高质量样...