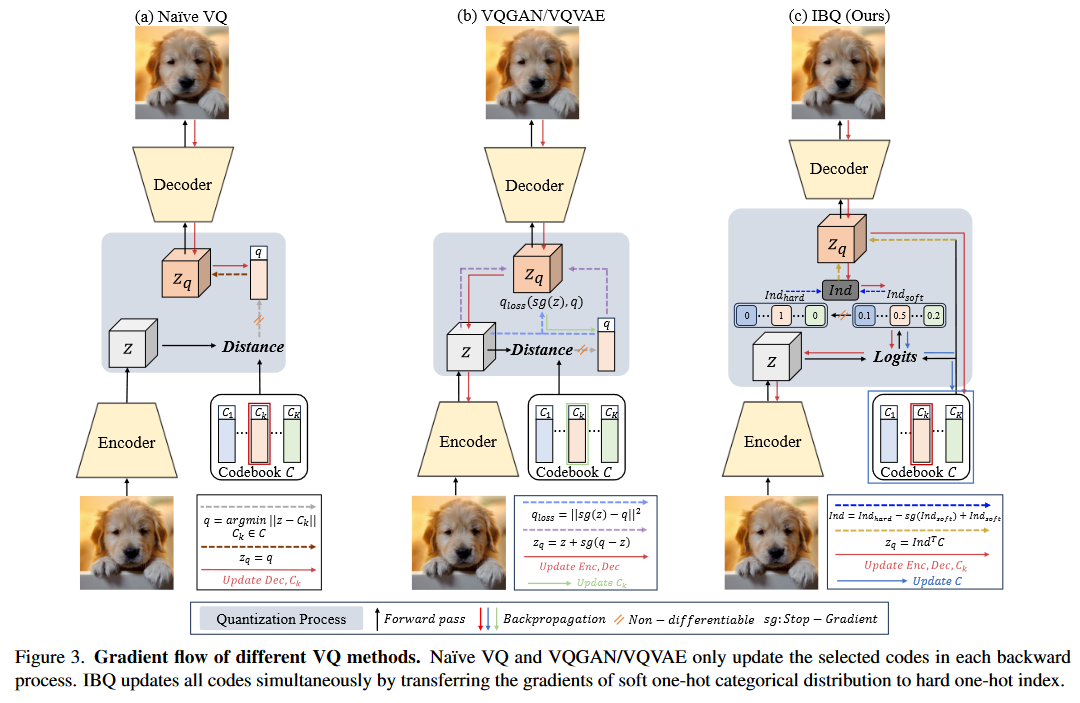
1 研究背景、动机、主要贡献 1.1 存在问题(动机) 现有的方法通过降低潜在空间的维度来缓解表示崩溃问题(只有一小部分 codebook 中向量通过梯度下降更新),但会以牺牲模型容量为代价。 1.2 主要贡献 提出了 IB...
Addressing Representation Collapse in Vector Quantized Models with One Linear Layer
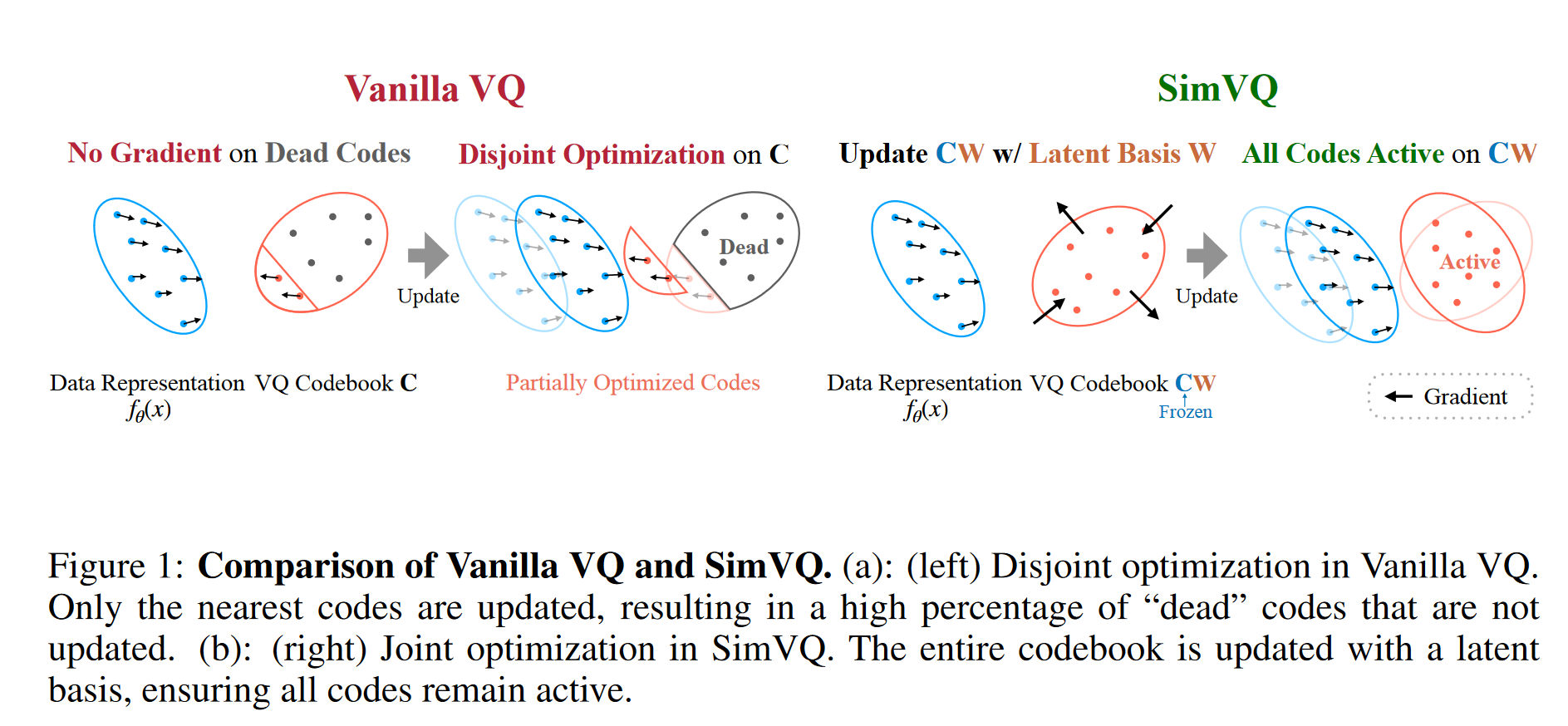
1 研究背景、动机、主要贡献1.1 存在问题(动机)现有的方法通过降低潜在空间的维度来缓解表示崩溃问题(只有一小部分 codebook 中向量通过梯度下降更新),但会以牺牲模型容量为代价。 1.2 主要贡献提出了 SimVQ 方法,有...
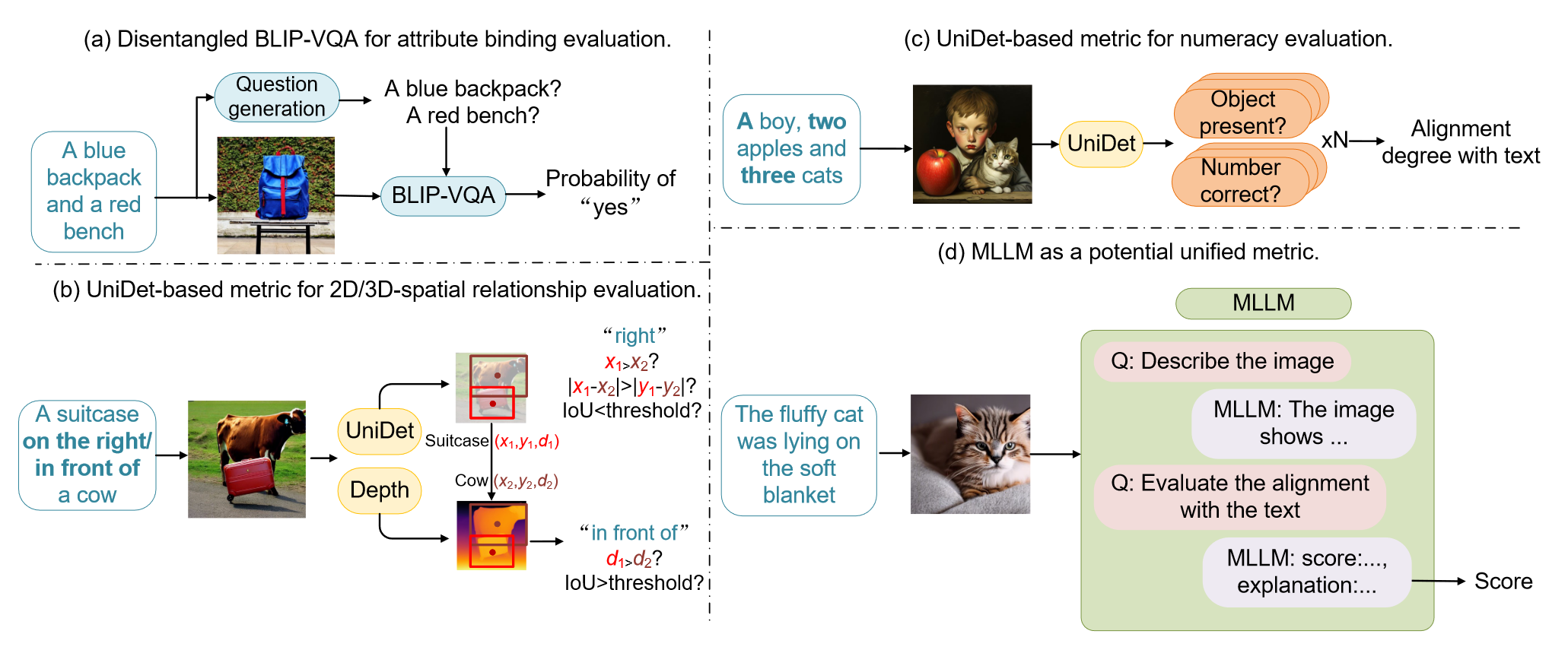
T2I-CompBench++: An Enhanced and Comprehensive Benchmark for Compositional Text-to-image Generation
1 研究背景、动机、主要贡献 1.1 研究背景 文本到图像生成领域的最新进展展示了基于自然语言提示创建多样化和高保真图像的卓越能力。然而,即使是最先进的文本到图像模型也常常无法将具有不同属性和关系的多个对象组合成一个复杂且连贯的场...
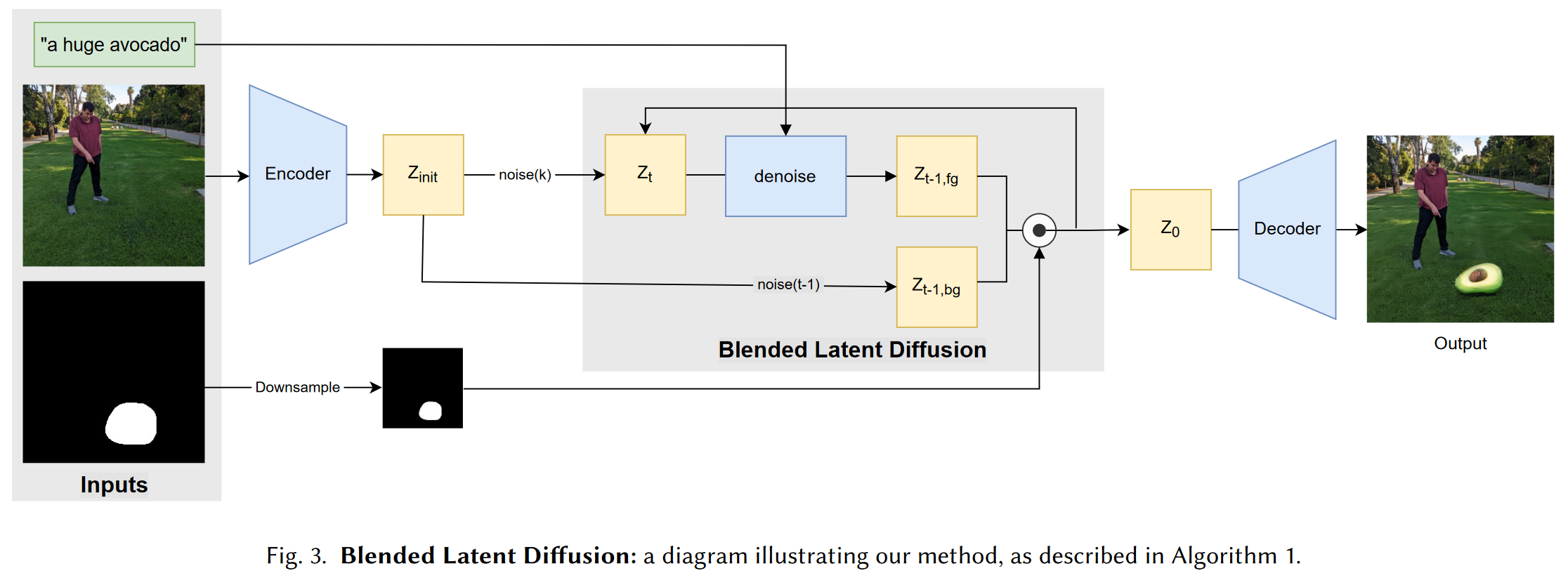
Blended Latent Diffusion
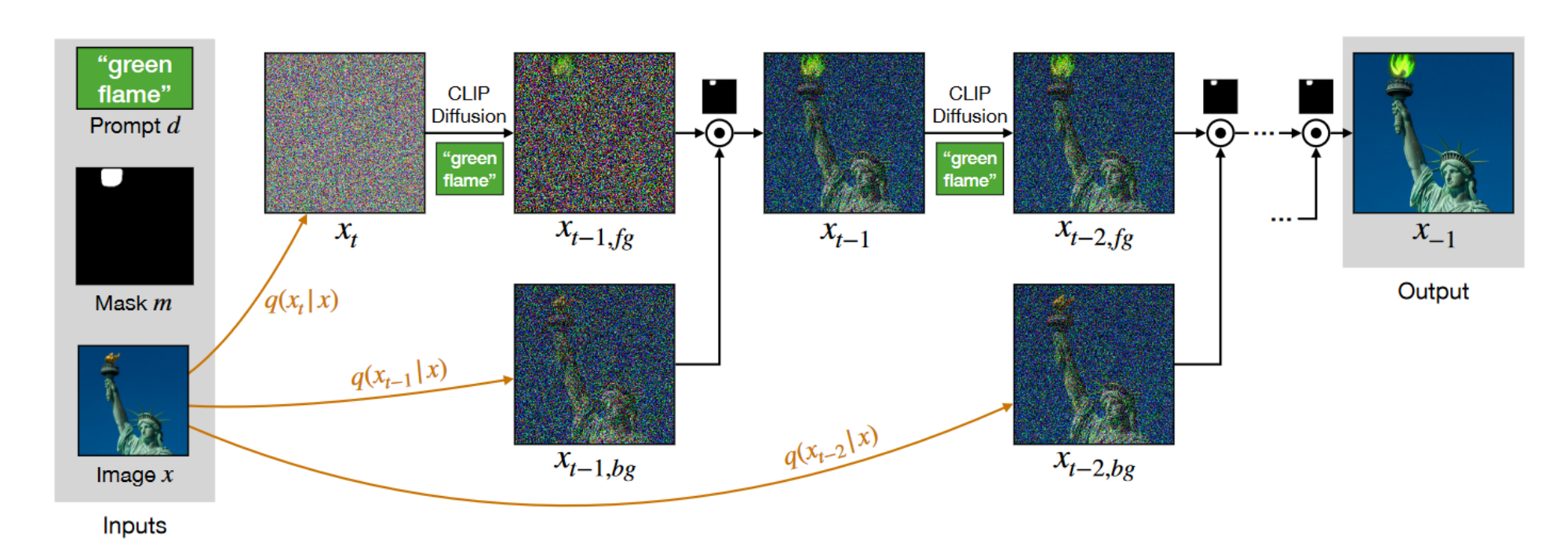
1 研究背景、动机、主要贡献 1.1 研究背景 GAN的崛起,扩散模型迅速发展,视觉-语言模型(如CLIP)的发展,Blended Diffusion 的提出。 1.2 存在问题(动机) 1.2.1 现有方案 Blende...
Blended Diffusion for Text-driven Editing of Natural Images
1 研究背景、动机、主要贡献 1.1 研究背景 文本生成图像的进展使得通过自然语言生成和编辑图像变得可行。特别是,基于 GAN 的方法在文本驱动的图像生成上取得了显著效果。 1.2 存在问题(动机) 1.2.1 现有方案 ...
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
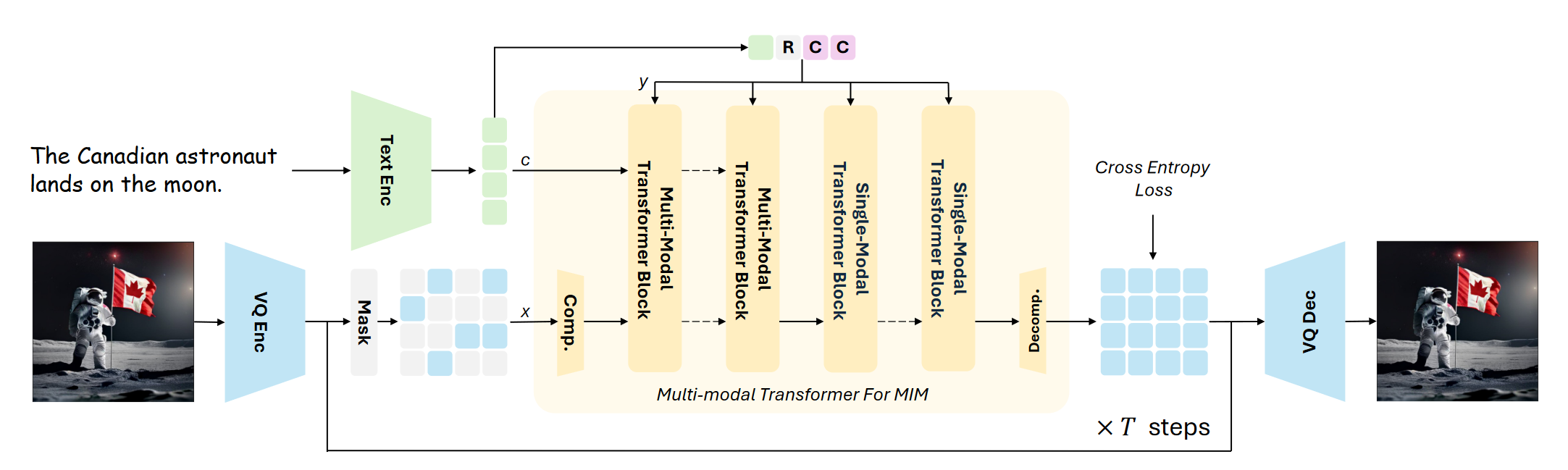
1 研究背景、动机、主要贡献1.1 存在问题(动机)自回归生成由于图像令牌数量庞大,效率低下;而非自回归方法(如MIM)则在性能上有限,无法与先进的扩散模型相比。 1.2 主要贡献 增强的变换器架构:结合多模态和单模态变换器层,提高M...
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
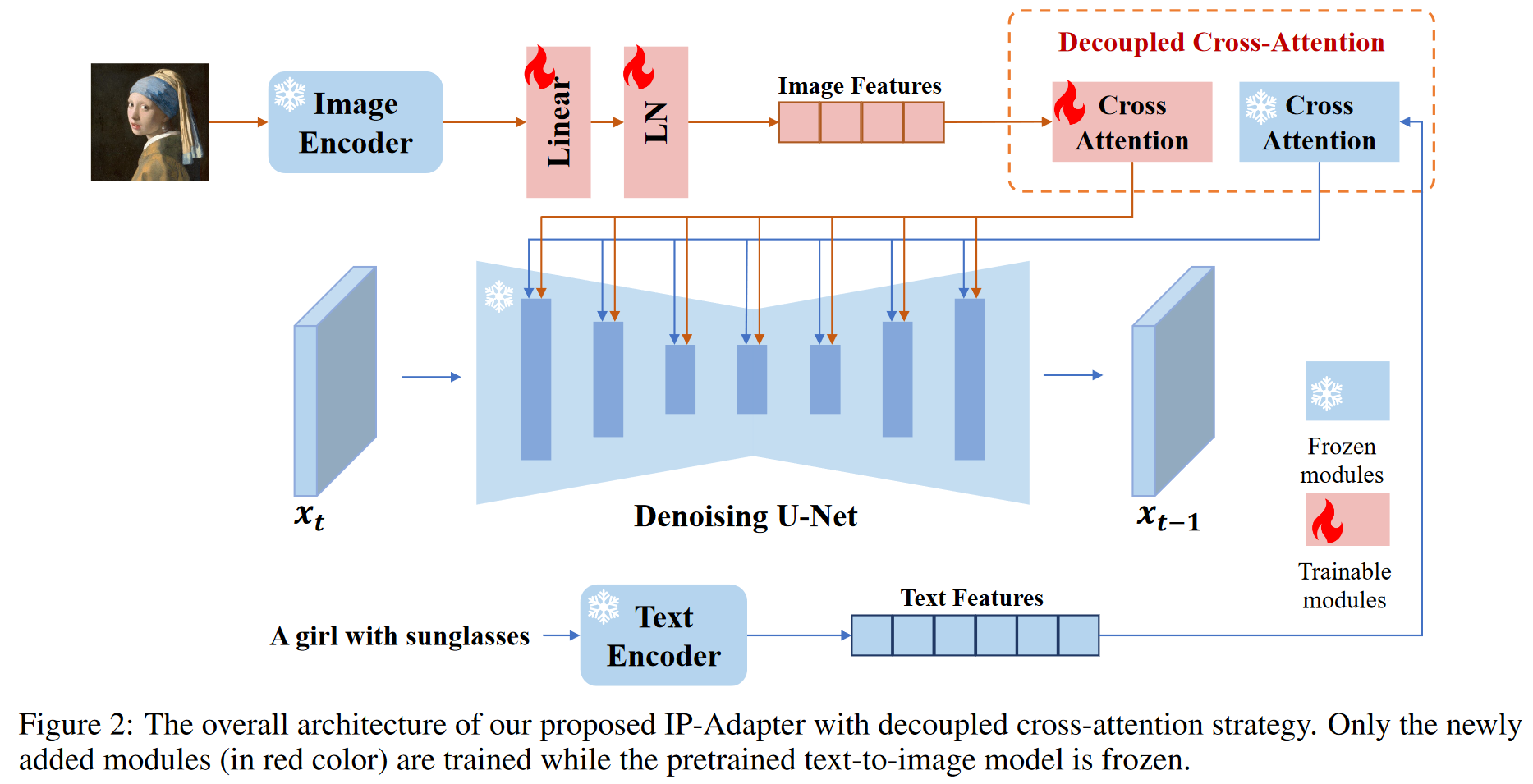
1 研究背景、动机、主要贡献1.1 研究背景近年来,大型文本生成图像扩散模型(如GLIDE、DALL-E 2、Stable Diffusion等)取得了显著进展,能够根据文本提示生成高保真图像。然而,生成理想的图像通常需要复杂的提示词...
SHOW-O: ONE SINGLE TRANSFORMER TO UNIFYMULTIMODAL UNDERSTANDING AND GENERATION
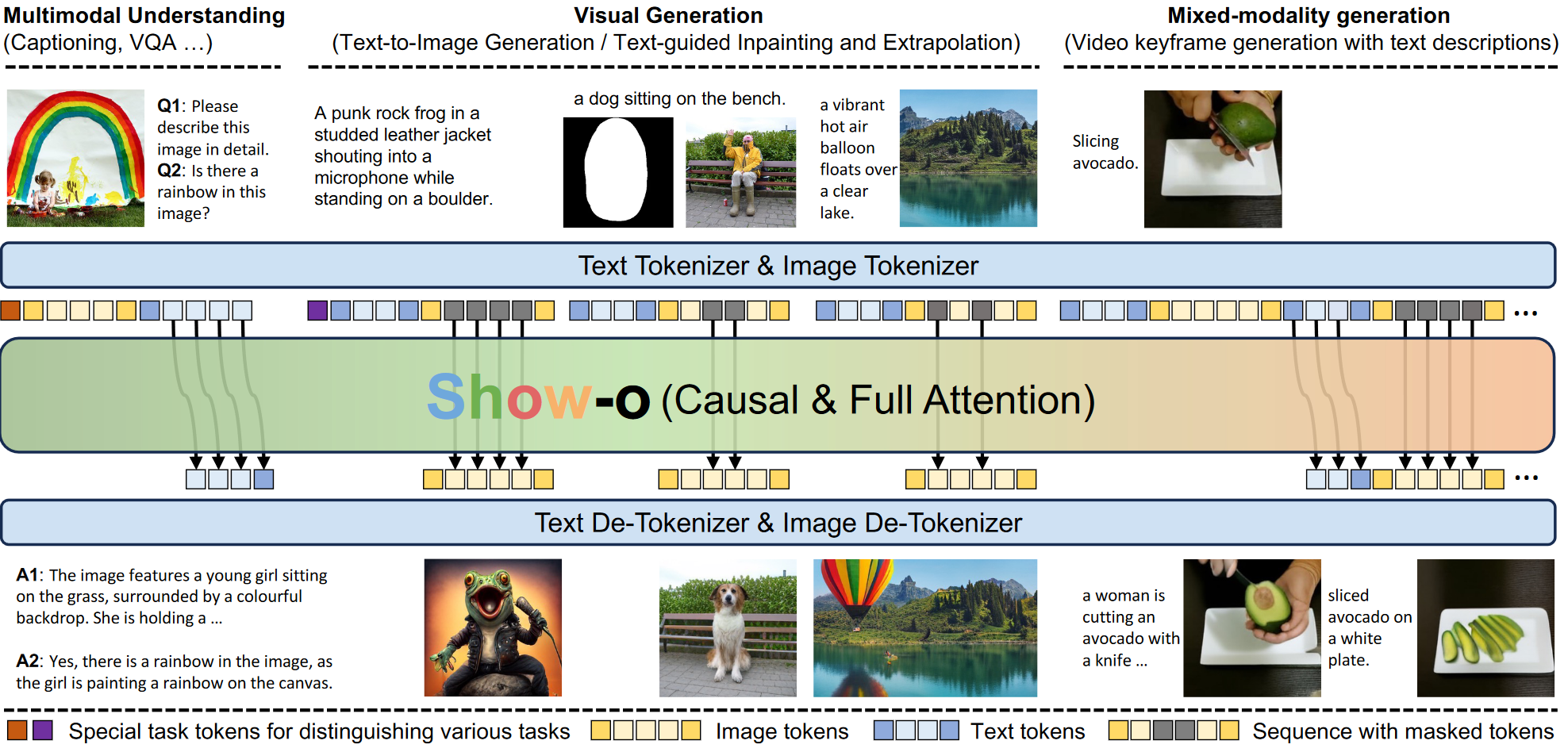
1 研究背景、动机、主要贡献 1.1 研究背景 现有的尝试主要是独立地对待每个领域,并且通常涉及单独负责理解和生成的模型。 1.2 主要贡献 提出了Show-o,一个能够同时处理多模态理解和生成任务的统一Transfo...
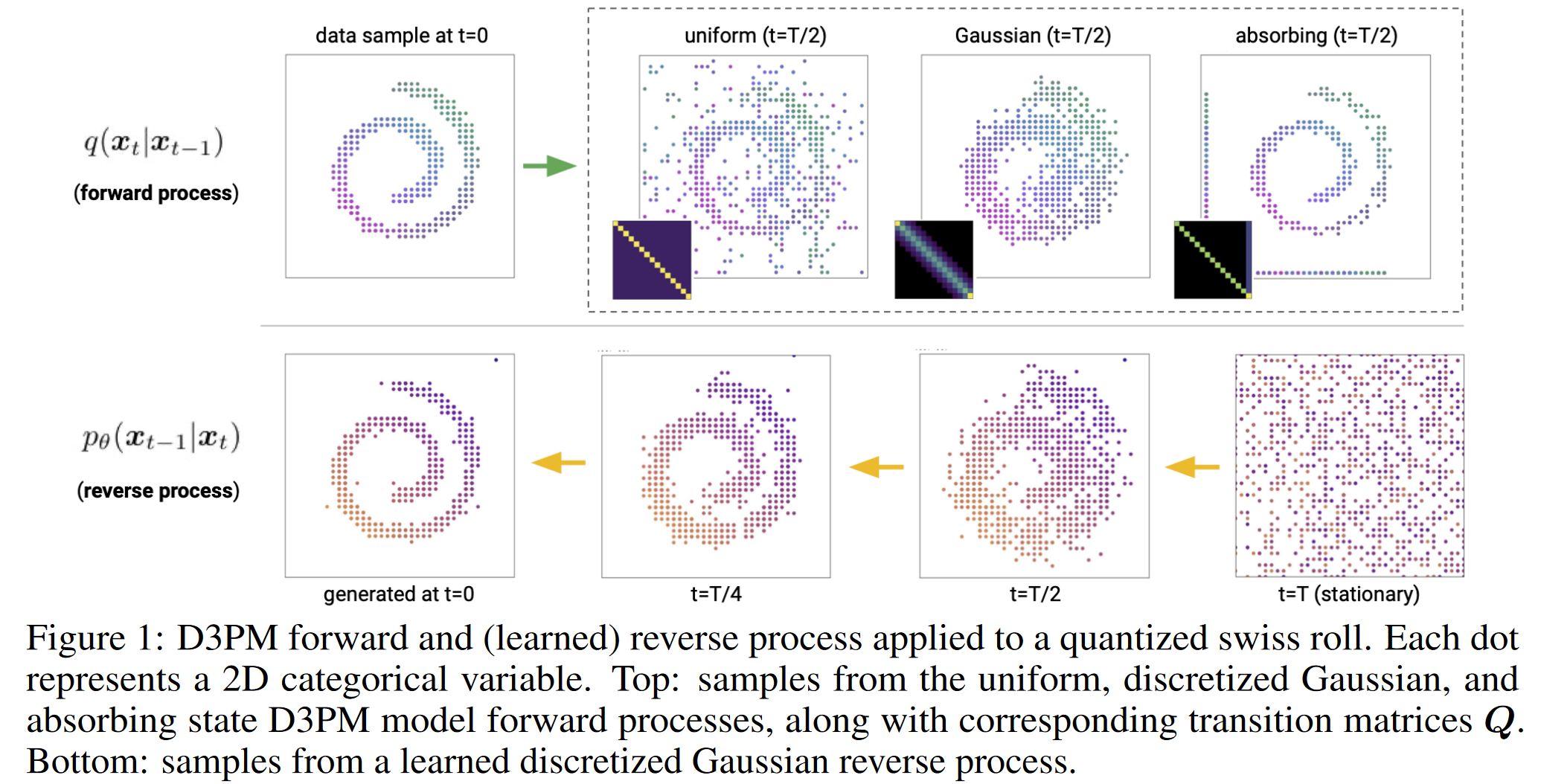
Structured Denoising Diffusion Models in Discrete State-Spaces
1 研究背景、动机、主要贡献 1.1 研究背景 尽管扩散模型在连续数据上表现良好,但在离散数据(如文本或量化后的图像)上的应用仍然有限。现有的离散扩散模型主要集中在文本和图像分割领域,尚未在大规模文本或图像生成任务上展示出竞争力。...

Hexo 公式渲染踩坑
renderer选择 解决多行公式(如矩阵)无法渲染问题 我的 node_modules : hexo-filter-mathjax hexo-renderer-ejs hexo-renderer-kramed hex...